SPSS Modeler ヒモトク
Modelerデータ加工Tips#17-対数と分位化で偏りのあるデータから特徴量を作る
2021年09月06日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
皆さま、こんにちは。Tポイントジャパンでデータアナリシス企画ディビジョンのゼネラルマネージャーをしています山本卓也です。
私どもの運営するTポイントは、共通ポイントのプラットフォームを構築してから18年目を迎えております。この間に会員様は約7000万人、ポイントが貯まるアライアン企業様は200社にご愛顧頂いています。
さて、私とSPSS Modelerとの出会いは17年前に遡ります。当時、Tポイントの分析組織立ち上げに参画した際に、一番最初に採用した分析ツールがClementine(SPSS Modeler)でした。 初心者でもつかえる操作感にチームで利用するのに向いていると直感したからです。
実際に、SPSS ModelerのユーザーフレンドリーなGUIによって、一定のレクチャーを受けると誰もがすぐに習得でき、先輩が作った分析資産は次々と高いレベルにアレンジされてゆきました。また、SQLの自動生成機能(SQLプッシュバック)によってSQLの経験がないメンバーも大規模で複雑なデータ処理が可能になった恩恵は計り知れません。
Tポイント事業の成長の過程で、アライアンス企業様に対してデータ分析を提供する分析官は増強されて現在50名程の分析官が在籍しています。もちろん必要に応じてPythonやRも利用するのですがSPSS Modelerが「共通言語」になって分析組織を支えているのは間違いありません。CADSの自動処理を含めて手放せない基盤になっています。
SPSS Modelerへの愛と感謝を語りだしたらキリがありませんが、これからもその進化とともに、自分もありたいと願っています。
偏ったデータから特徴量を作成する
SPSS Modelerのデータ加工は集計やデータ抽出、帳票作成などの基本的なものに役立ちますが、なんといっても予測モデルの精度を向上させる「特徴量の作成」でその威力が発揮されます。
特徴量にも、いろんな種類がありますが、このブログでもすっかりお馴染みのIBM都竹さんが次の記事「今あらためて考える特徴量エンジニアリング」で特徴量の作成をわかりやすく整理されていますので、ご本人の許可を得て掲載させていただきます。

さて、では特徴量をありったけ作れば良いかというと、時間と労力の制約上そうではないですよね。そうなると、モデルの実効性を検討しながら素早く準備できるかが、良いモデルを作るカギを握ることになります。
すでにこのデータ加工TipsブログでもTips#13の移動平均や標準偏差、Tips#15で主成分分析が紹介されてきました。この回では対数と分位化にフォーカスし、すぐにそれをセットアップできる能力を再確認したいと考えています。対数も分位化の説明も詳しくはしないのですが、たとえば、顧客の所得と売上を対数変換して、線形回帰を行うと、所得が1%伸びると売上が何%増えるか(弾力性:xの変化率とyの変化率の比)を算出できます。その対象を優良顧客に絞るとどうなるかなど分析のシナリオを増やすことができます。
特徴量を素早く作る点では推しノード#05「データの自動準備」、分位化はIBM河田さんのQiitaでも紹介されていますので、合わせてご覧ください。
例題1:「マウス操作だけで対数変換」
前回の出題は次の通りでした。
左のテーブルのValueフィールドを対数変換してみて下さい。そのとき式ビルダーからlog関数を使わずマウス操作だけで出来ますでしょうか。入力と出力の間には1ノードの1手詰めです。
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/longtail.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
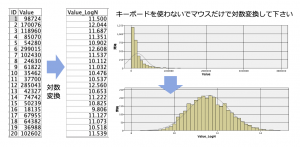
まず、次のようにストリームを作ります。①可変長ファイルノードで対象データを読み込んだら、②出力タブの変換ノードを接続して③Valueを設定。完了したら実行します。
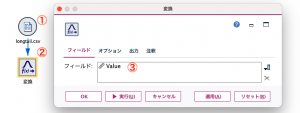
するとValueの分布と複数の方法による変換後の分布をグラフで表示してくれます。今回は①LogNを選択します。②がLogNに切り替わったら③生成メニューでフィールド作成ノードを選択します。
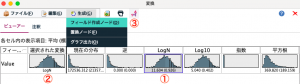
平均を0、標準偏差1にするzスコアも選べますが、今回は標準化されていない変換を選択してOKボタンを押します。
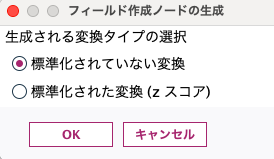
ストリーム領域にスーパーノードが自動生成されます。スーパーノードは推しノード#20で説明されている通り、本来複数のノードをカプセル化したものです。
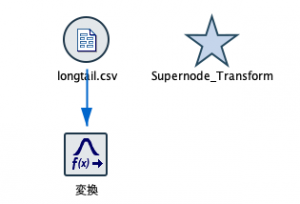
右クリックでスーパーノードをブラウズしてみます。含まれているのはフィールド作成ノードで、log(Value)が自動で作られているのがわかります。

あとはテーブルノードに繋げればストリームは完成です。実質利用したノードは1ノードです。ヒストグラムで変換前と変換後の分布も確認してみてください。
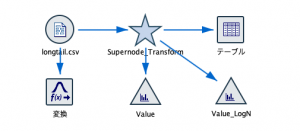
最初からlog(Value)で瞬殺なのですが、本来試行錯誤する特徴量作成に、分布を確認しながら、自動でスーパーノードを生成できる変換ノードを取り上げました。
例題2:「デシル分析のために顧客の購入金額を10分位に分類する」
出題は次の通りです。
例題1のデータを利用します。Valueフィールドを顧客ごとの購入金額だとして上位10%から下位10%まで人数が等しくなるように10のグループ分けて下さい(10分位=デシル)。このとき最も購入金額の高い1割の顧客グループをデシル1と定義します。以下のデシルフィールドのようにIDが1の顧客はデシルが6になるように注意して下さい。入力と出力の間には2ノードが必要です(2手詰め)。
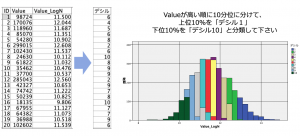
模範解答となるストリームはこちらです。
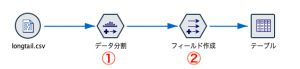
まずフィールド設定タブからデータ分割ノードを配置して次のように編集します。Valueを分位によって分割します。Valueの値が高い順に並べて、全てのIDの数が10%に分かれるように10分位化します。
プレビューするとちゃんと分類できています。ただし、最もValueの高いものを10にしていますので、これを反転する必要があります。
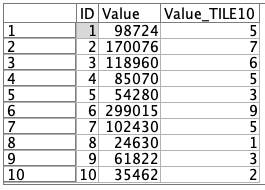
②のフィールド作成ノードで10を1に、9を2に反転させます。どうするかというと、
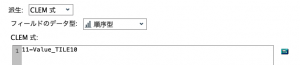
11から今出来上がったValue_Tile10を引き算します。この値の反転は福岡大学太宰先生が推しノード#15「順序尺度の逆転」で解説された小技です。
プレビューすると、できていますね。これで完成です。日本では1が最もよく買った上位1割のお客様をデシル1と定義されることが多いので、この反転が必要になります。デシルはdecileと表記され1リットルの10分の1がデシリットルだと言われると、なんだか馴染みのある言葉に思えてきます。
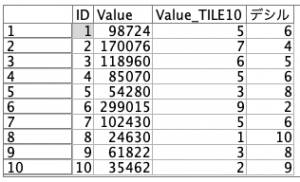
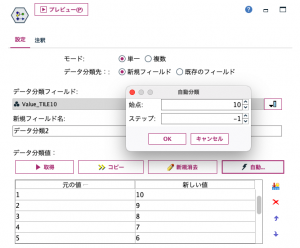
実はもう一つ反転する便利技があります。フィールド設定タブのデータ分類ノードを使う方法です。取得ボタンで元のメンバーを並べたら、変換する新しい値を自動ボタンで定義します。初期値を10にしてステップを−1にすると以下のように、値が反転します。
例えば分位化にしてからモデルに投入にすると、特定の分位の場合極端にモデルに影響を与えるなど、有益な特徴量になる場合があります。またモデル以前に分位毎の傾向で大きな示唆を得られる場合もあります。
例えば上位2割の顧客であるデシル1とデシル2が全体の7割の収益をカバーしていた場合、そのグループに販促コストを集中するべきだと判断できるかもしれません。またデシル3以下と購買行動を比較するだけで、重要な行動変容のアプローチを立案できる場合もあります。
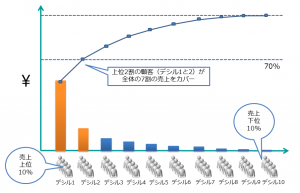
ちなみに今回のデータではよく言われる2割の優良顧客が8割の売り上げをもたらす「2-8の法則」ほどの集中はありませんでした。上位3デシルで68%の売り上げをまかなっていました。
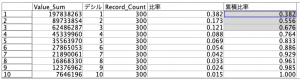
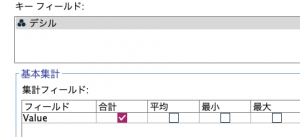
この表の作り方だけ簡単に。
最初にグローバルノードの設定で、Valueの総計をキャッシュします。
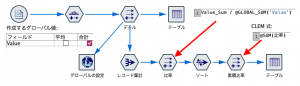
次にレコード集計でデシルをキーにそれぞれのValueの合計を計算させます。
フィールド作成ノードでキャッシュの値を呼び出して比率を求めてデシルで昇順ソートして累積値を求めれば完成です。
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「予測に最適なグループ化」
解約を予測するのに適するように期間をいくつかのグループに分けてください。出来上がったフィールド名は気にせず1手詰め(1ノード)です。
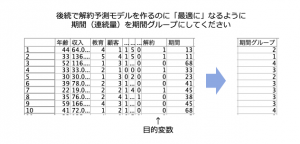
例題データ
https://raw.githubusercontent.com/yoichiro0903n/blue/main/optdata.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
例題2:「顧客グループ毎にモデルを作り分ける」
例題1の加工に続いて解約予測モデルをロジスティック回帰で作成してください。その際「顧客」フィールドの4群でモデルを作り分けてみます(モデルナゲットは単一とします)。例題1の手もカウントして3手詰めです。
フィールド「期間」は入力とせず、例題1で作成した「期間フィールド」を入力にしてみてください。連続量からグループに分けたメリットを、モデルを読み解く過程で触れるつもりです。

いかがでしょうか?「最適分割」も「モデルの出しわけ」も、Modelerに標準で備わった機能で実行できますので、ぜひ探してみてください。
さて次回のTips# 18はリバーフィールドの磯部さんが執筆されます。
ご期待ください。

山本 卓也
株式会社Tポイント・ジャパン
データアナリシス企画
ゼネラルマネージャー

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む