SPSS Modeler ヒモトク
Modelerデータ加工Tips#16-キーワードの有無で類似文章を検索する
2021年08月26日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさま、はじめまして。JALカードの辻井と申します。
当社は、「あなたの願いの、いちばん近くに。」をブランドスローガンに掲げ、JALのマイレージプログラムとクレジットカードを組み合わせたサービスをご提供しております。日常でためたマイルで、旅という非日常の体験価値をお届けすることをミッションとし、事業を展開しています。
「丸いものを繋いでいるのは、なんだろう。楽しそう!」。初めてIBM SPSS Modelerをみたときの印象です。隣席で操作する先輩のPCを見るたび、「私も触ってみたい!」と思ったあの時の気持ちは、今でもはっきりと覚えています。
そんな安易な感想を抱いた私も、IBM SPSS Modelerを使用して早6年。お客さま情報やクレジットご利用情報などを紐づけ、お客さま理解に努める日々です。IBMの皆様のお力添えにより、クラスター分析やアンケート調査など、分析目的に応じて使い分けができるようになりました。直観的、かつツール初心者でも操作が容易なIBM SPSS Modelerには、今後ともお世話になりたいと思います。
CADSを含めてどのようにSPSSを利用しているかは同じSPSSヒモトクブログで取り上げていただきました。記事はこちらです→「JALカードにおける分析の高度化・自動化への取り組み」
さてこのブログでは、非構造化データの活用をテーマにしてご紹介いたします。
文章を自然言語処理で定量化する
コンタクトセンターの会話ログや電子カルテ、営業日報のように自由に記述された定性的なデータは自然言語処理で定量化して分析に用います。
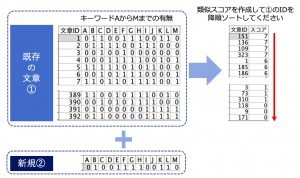
具体的なイメージは以下のとおりです。レビュー列から機械的に特定のキーワードやキーワード群を抽出してタグ化しています。

推しノード#22にあるクチコミに含まれる形容詞のフラグ化のテーブルを拝借しました。
かつてアンケートを分析する際には、手作業で以下のようにキーワードの有無をフラグ化するのが一般的だったそうですが、現在は機械にそれをさせることができます。
またTF-IDFやword2vec、BERTといった手法にかけてベクトル化するなど文章検索技術は次々と高度化しています。2019年のSPSSユーザー会でHonda小松さんが紹介されていた「自然言語ベクトル化と機械学習による自動車開発文書分類・検索支援のトライ」を記憶している方も多いと思います。
SPSS Modelerと自然言語処理
バージョン18.1以前では日本語処理のオプションの提供があったので私どもはそれを利用してます。以降のバージョンでテキスト処理するには大きく2つの方法が考えられます。
①拡張ノードでPython連携する
2021春のユーザー会でHonda小川さん・吉武さんが紹介されていました。外部のライブラリと連携する方法です。
https://www.ibm.com/blogs/solutions/jp-ja/smuc-2021-spring/
②スマートアナリティクス社のDatas for Modelerを採用する
こちらは、すでにテキスト処理に必要なストリームとR連携を含めて提供しておられ、すぐにテキスト分析に取りかかれると評判だそうです。
https://smart-analytics.jp/spss/ibm-spss-modeler/datas_for_modeler/
例題:「類似文章を検索する」
出題は以下の通りでした。既存文章①のキーワード有無13フィールドから新規文章①と類似性が高い(フラグの一致数)ものから順にソートします。
例題データ
利用する2つのデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/existing_text.csv
https://raw.githubusercontent.com/yoichiro0903n/blue/main/new_text.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
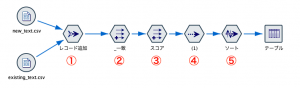
完成ストリームはこちらです。5つのノードを利用します。
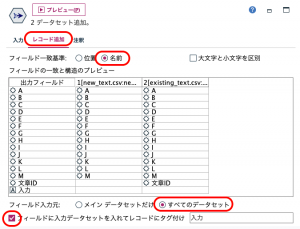
まず①で2つのデータをレコード追加します。このときリンクを接続する順序に注意してください。最初にnew_textから、次にexisting_textを矢印で繋ぎます。接続の設定は次の通りです。[フィールド入力元:]をすべてのデータセットにして下さい。また最下部の[フィールドに入力データセットを・・・]にチェックを入れておいてください。
この①が設定されるとプレビューが以下のようになるはずです。1番上のレコードが新規文章で2レコード目から既存文章が始まっています。
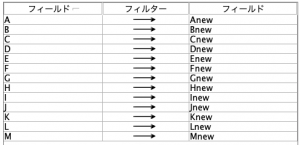
あとは全てのレコードと一番上のレコードを順番に比較、AからMの真偽が同じかをこのブログでもお馴染みの@OFFSETを用いて検査します。
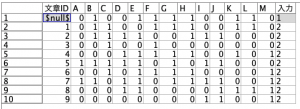
レコード間の比較をどのように行うか説明します。
例えば3レコード目の文章ID2のCが新規文章と一致しているかどうかを考えます。赤丸実線からみた2レコード上(オフセット)のC(赤丸点線)は@OFFSET(C,2)と記述できます。既存も新規も1なら真(Ture)とし、既存1と新規0、既存0と新規1、両方0を偽(False)としたいのですがどう計算すれば良いでしょうか?加算で2でもO Kなのですが掛け算であっさり表現できます。@OFFSET(C,2)*Cとすれば、どちらかに0があると結果は0になり、既存も新規も1の時だけ1になるフィールドを作ることが可能です。
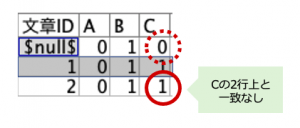
早速②のフィールド作成ノードで既存と新規の一致フラグを作ります。AからMまで1度に作れるのがフィールド作成のすごいところです。フィールドリストにAからMを選択します。出来上がった13フィールドに「_一致」という識別子を作ります。CLEM式ですが、先程例にあげた@OFFSET(C,2)*Cの「C」をAからMまで全てを1つで表せる「@FILED」に、「2」の箇所は何レコード上かを表すので「文章ID」を利用します。文章IDが1から始まる連続したIDであるため、偶然にもそのまま使えてラッキーです。
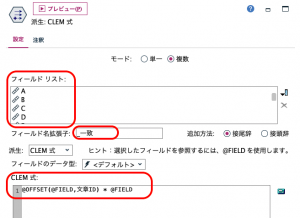
プレビューすると、対応する13フィールドが作られています。

あとはこれらの新規フィールドを③のフィールド作成ノードでカウントするだけです。派生フィールドに「スコア」と命名したら、式を設定します。カウントには推しノード#15で太宰先生が利用されたsum_nを用います。@FIELD_BETWEENでも良いのですが、今回は@FIELD_MATCHINGで対象フィールドをリストします。これで文字列「一致」を含んだ全フィールドの1をカウントすることができました。

仕上げに④のサンプリングノードで先頭レコードを排除して、既存文章のみに戻したらスコアで降順ソート(⑤)すれば完成です。

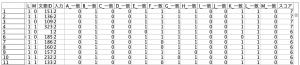
出来上がったテーブルです。スコアフィールドでソートされています。
以上が事前に予告していた5手詰めの解説です。
なんと、Tips#03でも、Tipsブログ運営サイドを唸らせたIBMのデータサイエンティスト都竹さんからまたしても想定手数より少ない4手詰めストリームをいただきました。「キーワード列が多いと運用に不向きかもしれない」と前置きがありましたが、素晴らしい内容でしたのでご紹介します。
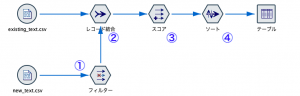
まず①で新規文章の全フィールドを後続のマージを考えて別名にします。
次に②の結合ですが、既存文章に新規文章を全てぶつけるので、結合方法はキーとしますがキー自体はブランクで結構です。
スコア計算の③は基本的には5手詰めと同じです。掛け算なら、既存と新規どちらかに0があると0になるので以下で求められます。

最後に④で降順ソートです。確かに今回のキーワード数なら、この方法が良さそうですね。
都竹さんに感謝の気持ちを込めて最近記事を宣伝?させていただきます。
都竹さんのMLOpsの記事はこちらhttps://www.ibm.com/blogs/solutions/jp-ja/mlops-2021-data/
いかがでしたでしょうか?
今回の加工は文章検索以外にもフラグ列が多いデータでの一致率計算などに応用できます。皆様の日頃のデータ活用にお役に立てれば幸いです。
Modeler詰将棋!次回のTipsから出題
次の例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「マウス操作だけで対数変換」
左のテーブルのValueフィールドを対数変換してみて下さい。そのとき式ビルダーからlog関数を使わずマウス操作だけで出来ますでしょうか。入力と出力の間には1ノードの1手詰めです。Modelerにそんな使い方があったのか!と知っていただきたくて出題しました。
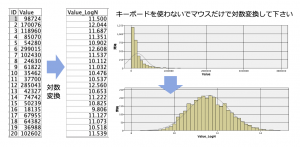
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/longtail.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
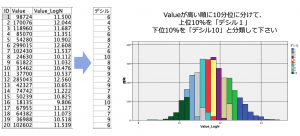
例題2:「デシル分析のために顧客の購入金額を10分位に分類する」
例題1のデータを利用します。Valueフィールドを顧客ごとの購入金額だとして上位10%から下位10%まで人数が等しくなるように10のグループ分けて下さい(10分位=デシル)。このとき最も購入金額の高い1割の顧客グループをデシル1と定義します。以下のデシルフィールドのようにIDが1の顧客はデシルが6になるように注意して下さい。入力と出力の間には2ノードが必要です(2手詰め)。
いかがでしょうか。IBMのベテラン棋士は例題1を2分、例題2を4分で解いたそうです。
さて次回のTips# 17はTポイント・ジャパンの山本さんに例題の解説をいただきます。
お楽しみに!

辻井 万里子
株式会社ジャルカード
営業・マーケティング本部
データマーケティング推進室

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む