SPSS Modeler ヒモトク
Modelerデータ加工Tips#15-後続モデルのためにフィールドを縮約(次元削減)する
2021年08月16日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさんこんにちは、株式会社スタテックスの長谷川博康と申します。SPSS社に在籍していましたが起業し、現在はコンサルタントとしてお客様からの依頼にお応えしてデータ分析支援をしています。統計解析、データマイニング、データサイエンスの領域を専門としてSPSS Statistics・Amos・Modelerなどさまざまな分析ツールを使っています。
このTipsでは主成分分析(PCA)による次元削減をテーマに取り上げます。
「えっ?学校の父母会の?それはPTAですやん!」・・・ってすみません。関西出身なので挨拶代わりにボケから入りました。ちなみに娘の小学校ではPTA会長をしています。
さてそれでは本題にゆきましょう。
フィールドを縮約する典型的な場面
皆さんはモデリングに説明変数として、フィールド数をどの程度同時に利用しますか?決定木のように有用なフィールドだけを選んで利用するモデルは問題ないのですが、例えば線型回帰モデルでは注意が必要です。
線型回帰モデルは
①説明変数の数が多い
②説明変数間に強い相関がある
③説明変数の数に対して扱えるレコード数が少ない(例えば200レコードのデータに対して説明変数が20は多い)。
といった場合には適切に処理をしないと誤った結果を導くことになります。
この回避方法のひとつが説明変数を縮約(=次元削減)するデータ加工として使える、主成分分析(PCA: Principal Component Analysis)です。
主成分分析による縮約ではフィールド数を膨大にもつゲノム解析での利用が典型的で、これまでも、さまざまな論文や記事に取り上げられておりご存知の方も多いはず。
フィールドの縮約
主成分分析や因子分析は、社会科学の分野では、よく用いられる統計手法です。多くの関連する変数(フィールド)がある場合に、そこから合成成分や共通因子を抽出する目的で利用されています。詳細な説明はここでは割愛しますが、主成分分析と因子分析は、同じようなアルゴリズムが使用されています。そのためSPSS Modelerでは、因子分析ノード内の設定で主成分分析を実行します。ノード名が「因子分析ノード」なので、「主成分分析ノード」どこ?と困惑された方も多いのではないでしょうか。
主成分分析は情報をできるだけ取りこぼさないように複数のフィールドを合成し、主となる成分を作るのが特徴です。それぞれの主成分は独立しており、もともとのフィールドに重みづけされたものの組み合わせで表します。主成分スコア(主成分得点)は、その和として計算され、その結果フィールドの数を主成分の数にまで減らせるのです。それぞれのフィールドは、各主成分と相関を持ちますが、その程度は、主成分によって異なります。どの主成分も、一部の若干数のフィールド群が強い相関を示し、その主成分がどのようなフィールド群を代表しているかを知ることができます。
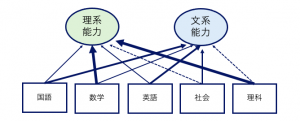
少し安直な例ですが、学生の5教科のテストの得点データから、理系・文系能力の得点を作るイメージで見てみましょう。
四角で表現しているのが学生の5教科のテストの得点で観測変数(手元のデータ)、楕円で表現しているのが主成分(観測変数から作る)です。太線、細線、点線は、観測変数と主成分の関係の強さ(重み)を表しています。各教科に重みを掛けて、足し合わせると新しい指標となる主成分の得点が計算できます。ここでは主成分に理系・文系能力と名付けましたが分析者の主観的な解釈や名付けでよく、特に決まりはありません。関係性のある観測変数群から名付けたり、総合力1、総合力2・・・としたりでも構いません。そして、実は主成分の数は観測変数の数と同じだけあって、全て使ってしまうと縮約(次元削減)にならないので、分析者の采配で扱う数を決めます。今回はご覧の通り、5つの観測変数を2つの主成分に縮約しました。5次元を2次元に次元削減したことにより、学生の特長を把握しやすくなりますね。
データ加工としての主成分分析
主成分分析によるフィールドの縮約は、フィールド数が多いIoTデータの分析でもよく活用されています。様々な状況によって、新しい指標を考えたいときには、主成分分析のようなフィールドの縮約(次元削減)が役に立ちます。多くのフィールドを使用して、データを縮約し、その結果を用いて予測モデルに使用する、あるいはクラスタ分析などにも使用できます。このような、予測・クラスタリングの前処理として、データ加工の位置づけで、主成分分析を利用するイメージを掴んでいただけましたでしょうか。
前回のTips#14で出題された例題を用いて詳しく説明します。
例題:「複数のフィールドを縮約する(=次元を削減する)」
出題は以下の通りでした。
モデル作成や後続処理のために、フィールド数を削減します。ただし情報量は7割以上保持してください。方法がピンとくれば瞬殺の1手詰め(入力と出力の間に必要なノード数)です。フィールド数をどうやって減らすか悩んだ経験がない方は「機械学習・次元削減」で検索してみてください。
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/ProdDna.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
次のようにストリームを作ります。

入力ノードで読み込むファイルを設定したあと、手数を減らすためデータ型タブで、次元削減の対象とするフィールドのロールを[入力]に、それ以外はロールを[なし]にして、値の読み込みをクリックします。

モデル作成パレットから因子分析ノードを選択して、入力ノードにリンクします。
因子分析ノードから主成分分析を実行する
入力ノードにリンクした因子分析ノードをダブルクリックし、編集します。モデルタブをクリックし、抽出方法を確認します。デフォルト設定は主成分分析です。
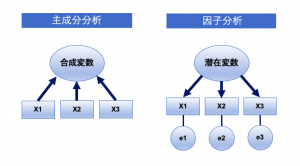
因子分析と主成分分析の違い
因子分析ノードの抽出方法には選択肢が用意されています。デフォルトの主成分分析以外は、すべて因子分析の因子抽出の方法です。

ここで、ちょっとだけ因子分析と主成分分析の違いをご紹介します。因子分析は、複数のフィールド間の関係性から潜在的に存在する因子(潜在因子)を抽出します。それに対して、主成分分析はフィールドから合成された主成分を抽出します。イメージは以下です。ポイントは矢印の向きです。
エキスパート設定
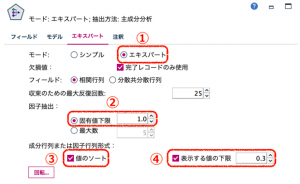
エキスパートタブをクリックします。①モードのエキスパートを選択します。詳細な設定ができるようになります。②抽出したい主成分を固有値か最大数で指定します。各フィールドの固有値(情報量)は1なので、抽出した主成分はそれを上回るものを選ぶということで、デフォルトの固有値下限1.0を採用します。アウトプットを見やすくするために、③成分行列の値をソートし、④固有値が0.3 以上を表示するように選択して、実行します。
作成されたモデルナゲット
作成されたモデルナゲットを参照します。主成分スコアの計算式が主成分ごとに確認できます。各フィールドに重み係数を掛けて足し合わせた式です。

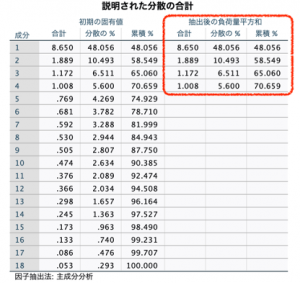
さらに、説明された分散の合計テーブルを参照すると、一番左の成分列にはフィールド数と同じ1から18までの値を示しています。そして、各成分の合計列には、成分が持つ情報量の値が算出されています。初期値にあった通り1フィールド1情報量(固有値)ということは18フィールドの全情報量は18です。第1主成分の情報量は、8.650ですので、全体の48.056%(=8.650/18*100)の情報量を持つ成分になります。モデル作成の際に、固有値1以上の成分を抽出するように設定したので、合計列の値が1以上の第4主成分までが抽出され、この4つの主成分で全体の70.659%の情報量であることがわかります。
モデルナゲットを通過させたデータ
モデルナゲットを通過したデータには、主成分スコア(主成分得点)が作成されます。
モデルナゲットにテーブルノードをリンクして実行すると、以下の主成分得点が作成されます。
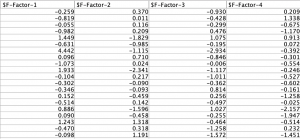
4つの主成分フィールドのできあがりです。18フィールドから4フィールドに次元を削減することができました。あとは、この4つのフィールドを使って予測モデルやクラスタリングなど次のステップへと進みます。次元を削減する手法は他にも存在するのですが代表的な主成分分析での取り組み例が皆様のデータ分析のヒントになれば幸いです。
Modeler詰将棋!次回のTipsから出題
次の例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題:「類似文章を検索する」
コンタクトセンターの既存文章にAからMまでのキーワード有無がフラグとして準備してあります。そこに新規文章がやってきた想定で、類似度(フラグ一致)が高い順にソートして示して下さい。
次回のTipsでは入力と出力を除いて5手詰めを解答例として用意しています。フィールド名やフィールド数・順序の調整は不要です。
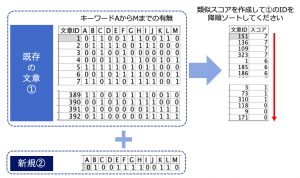
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/existing_text.csv
https://raw.githubusercontent.com/yoichiro0903n/blue/main/new_text.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
いかがでしょうか。IBMの女流名人は例題を9分で解いたそうです。
さて次回のTips# 16は過去にSPSSイベントでも登壇されたJALカードの辻井さんに例題の解説をいただきます。
お楽しみに!

長谷川 博康
株式会社スタテックス
代表取締役社長

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む