SPSS Modeler ヒモトク
Modelerデータ加工Tips#14-条件付きレコード結合で売り手と買い手のマッチング
2021年08月03日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさま、こんにちは。メルカリの松本です。私がSPSS Modelerに出会ったのは約20年ほど前です。これまで他のソフトも並行して使ってきましたが、SPSS Modelerは使えば使うほど、その良さに気づかされます。人を惹きつけて止まないデータ分析界のテーマパークのようです。
最近では、R、Pythonと言った製品を使う人も多いですよね。独断と偏見で、それぞれの良さを整理すると、
[RやPythonの良いところ]
・RやPythonのエンジニアの人口は多い。
・コードの共有やレビューなどを行うことが容易。
・LightGBM、階層ベイズ、状態空間モデルなど利用できるモデルの豊富さは、RやPythonの方が優位。
[SPSS Modelerの良いところ]
・データの入出力と加工に関する全体像を視覚的に確認しやすい。
・SPSS Modelerのインターフェースは「データを取得、加工し、モデルを作成して予測」という流れに特化されているため、基本的な作業に関する学習コストは低い。
・取り急ぎのモデルを作るプロトタイピングの過程は非常に早く、またこれに手を加えて改善していくことも容易。
最近のSPSS Modelerは、RやPythonを呼び出して使うことも可能なので、マーケティングの担当者からデータサイエンティストまで幅広く扱えるソフトとなっています。分析のプラットフォームとして使用し、必要に応じて高度な分析をすることも可能です。バージョンアップするたびに、いつも驚きの機能が追加されるので、その時期になると今回は、何が実装されるのかいつもワクワクしています。
SPSS Modelerの良さは5年前にこのヒモトクブログで取り上げてもらいました。ぜひご覧ください
https://www.ibm.com/blogs/solutions/jp-ja/spss-modeler-userstory2/
さて、私は前職リクルートライフスタイルからマッチングを生業にしていることもあり、カスタマとクライアントのマッチングを取り上げようと思います。今回は、わかりやすさを優先してお部屋を探すお客様の要望と物件情報から、条件結合する例をテーマにしようと考えています。カスタマとクライアントの両方の立場を考えて、どのようなマッチングが良いのか一緒に考えていただければ幸いです。
例題1:「お客様と物件をマッチングする」
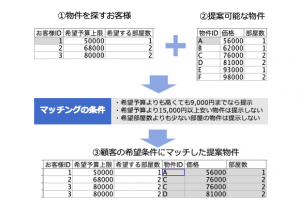
出題は以下の通りでした。お客様①と物件②を3つの条件を満たしてマッチングします。
例題データ
利用する2つのデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/matching1_1.csv
https://raw.githubusercontent.com/yoichiro0903n/blue/main/matiching1_2.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
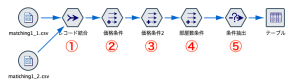
①でレコード結合を行う際にレコードの総当たり(N対N結合)をします。
あとは②③④で3つの条件にフラグを立てると、以下のテーブルになります。
条件はそれぞれ次の通り
- 希望予算上限 + 9000 >= 価格
- 希望予算上限 - 15000 <= 価格
- 希望する部屋数 <= 部屋数
この時点でテーブル出力するとこうなります。お客様3名に6つの物件を総当たりしているので18レコードあります。分かり易いように3つの条件をクリアすると赤字になるようにテーブルノードで設定しています。
- 価格条件 = 1 and 価格条件2 = 1 and 部屋数条件 = 1
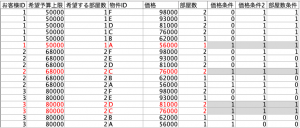
最後に⑤で先の赤文字に表示させる条件で抽出すると完成です。(フィールド順序は修正しています。)

これまでの処理は、条件が今後変化するときは、プロセスが個別に切り出されていて良いのですが、少し長いですよね。レコード結合の「条件つき結合」で一度で完結する方法を紹介します。
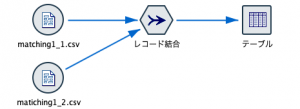
まず、レコード結合ノードにデータを接続します。この時リンクを接続する順番に注意です。matching1_1.csvから先に接続してください。ノード内でもテーブル順序をタグで設定できますが、先につなげたテーブルが主になると意識しておくとミスが減ります。
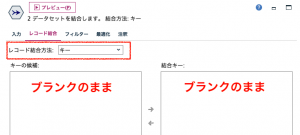
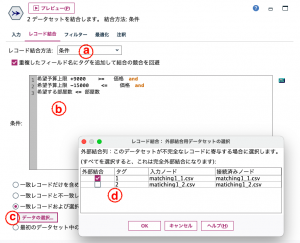
続いてaの通り、レコード結合方法を「条件」に、bで条件を記述します。cとdで主テーブルの確定をします。
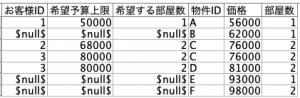
もしテーブルの順序を間違えると以下のようになり、顧客に提案されない物件が登場します。
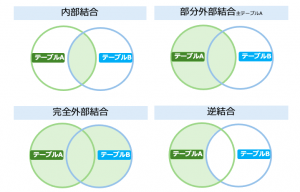
結合のタイプを踏まえれば何ということはないと思います。
正しく設定できていると、以下の4レコードが表示されるはずです。(フィールド順序は修正しています)
今回はビジネスルールを用いたマッチングの例でしたが、他にも様々な方法を組み合わせて実装します。例えば「渋谷エリア」を希望されるお客様になるべく選択肢を用意するため、隣り合った「新宿エリア」をカバーできるようにマスタテーブルを作っておく方法は有名です。またデータサイエンティストの皆様でしたら、過去の成約実績を機械学習させてスコアリングさせる方法もここ数年で発達しています。
マッチングでは、一度提案して検討いただいたものは次回から提案をしないように配慮します。これは商品レコメンデーションの際に、購入品はリストから外して意図的にクロスセルを促す場合も同じテクニックが要求されます。
例題2ではそのプロセスをテーマにしました。
例題2:「お客様が購入していない商品のリストを作る」
出題は以下でした。まだお客様が購入していないリストを作ります。
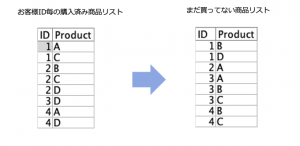
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/matching2.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
完成したストリームは次の通りです。4ノード利用します。
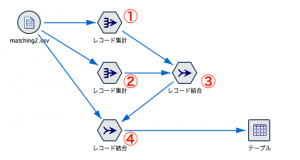
①と②はほぼ同じ処理をしています。
①ではレコード集計でシンプルな顧客リスト作成します。
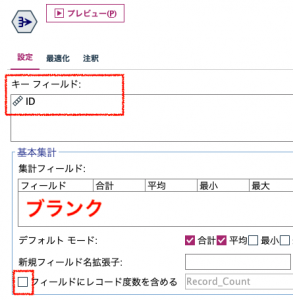
設定はキーフィールドを入れるだけで集計項目はブランクです。レコードはカウントしないようにチェックは外します。
②も同様に商品で同じことをします。
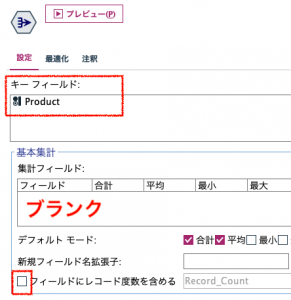
出来上がるとこんな感じです。ソートする必要はありません。
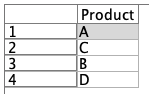
ここから、③で例題1でも登場した全てのお客様と商品の総当たりテーブルを作成します。結合方法はキーとしますが、キーはブランクのままです。
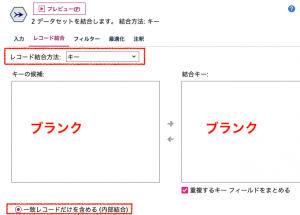
データはこの時点でこうなっています。4人のお客様に4つの商品ですので16通りの組み合わせテーブルができました。
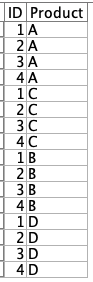
いよいよクライマックスです。このテーブルから、購入済み商品を消すために「逆結合」を使います。
④の入力タブで主テーブルを確定する必要があります。ここまで集計と結合をしてきたテーブルが主になるように、上矢印ボタンで順序設定します。
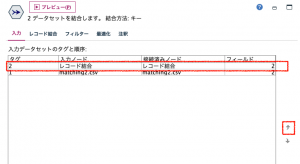
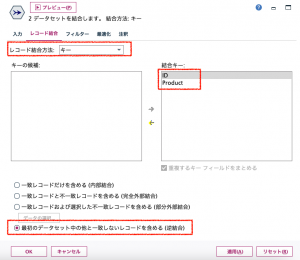
次にレコード結合タブで結合方法を「キー」にしてから結合キーに2つのフィールドを選択します。最初のデータセットの中の一致しないレコードを含める(逆結合)にラジオボタンをセットします。
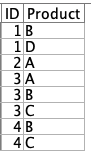
出来上がったテーブルを確認します。(フィールド順序は変更しました)
2つの例題を通して、マッチングに必要な
- 総当たりテーブルの作成
- 条件付きのレコード結合
- 逆結合によるリスト作成
を紹介しました。総当たりテーブルを作成するN対N結合はシミュレーションに威力を示しますし、条件付きレコード結合は不正検知でもよく用いられます。このTipsが皆さんの今後のお取り組みの何らかのお役に立てれ嬉しいです
Modeler詰将棋!次回のTipsから出題
次の例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題:「複数のフィールドを縮約する(=次元を削減する)」
モデル作成や後続処理のために、フィールド数を削減します。ただし情報量は7割以上保持してください。方法がピンとくれば瞬殺の1手詰め(入力と出力の間に必要なノード数)です。フィールド数をどうやって減らすか悩んだ経験がない方は「機械学習・次元削減」で検索してみてください。
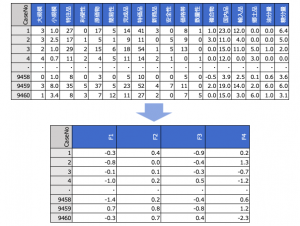
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/ProdDna.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
いかがでしょうか。IBMのベテラン棋士は例題を2分かからず解いたそうです。
さて次回のTips# 15はi-Learningの講師でもお馴染みの長谷川さんに例題の解説をいただきます。
お楽しみに!

松本 健
株式会社メルカリ
エンジニアリングマネージャー

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む