SPSS Modeler ヒモトク
Modelerデータ加工Tips#13-移動平均と偏差値で異常値を見極める
2021年07月21日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさんこんにちは。私は国立研究開発法人産業技術総合研究所(産総研)で研究員をしている本田智則と申します。
産総研は約2000人の研究者、その他スタッフや外部研究者等を含めて1万人の人員を擁する国内最大級の国立研究機関の一つです。その中で私が所属するゼロエミッション国際共同研究センターは、2020年1月に発足し2050年までの日本のゼロエミッション化実現に向けた基礎研究を行っています。センター長がノーベル化学賞を受賞した吉野彰さんであることでご存知の方もいらっしゃるかもしれません。
私自身は、スマートメーターやHEMS(Home Energy Management System)から得られた住宅のエネルギー消費データをSPSS ModelerとNetezza(IBM Netezza Performance Server)の組み合わせで分析することで、2050年に向けた脱炭素化社会実現のシナリオを研究しています。最近ではソーラーパネルの故障検知アルゴリズムなどを開発しました。
https://unit.aist.go.jp/rpd-envene/PV/ja/results/2020/poster/Honda.pdf(外部サイト)
研究報告にみなさんの見慣れたSPSS Modelerのグラフが多数掲載されています。
SPSS Modelerとの出会いは、私が大学院生だった2002年頃。当時はClementineと呼ばれており、バージョンは確か5.2でした。ハミングバード(日本語でハチドリのこと)と呼ばれるPC Xサーバ上で動く仕様で、起動時に綺麗なハチドリが画面一杯に広がる様子が印象的でした。以来、私の研究を縁の下で支えてくれている基盤ソフトのひとつであり、なくてはならないものになっています。
今回のTipsでは私が実際に研究している故障検知のベースとなった異常値発見の具体的な手続きをご紹介します。
異常値とはなにか
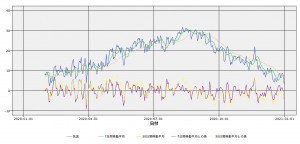
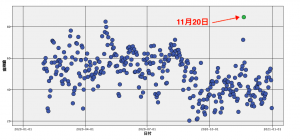
みなさんは以下の気温のグラフ(東京管区気象台の2020年)を見て、最も異常な気温を言い当てられますか?
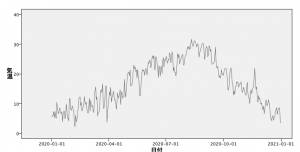
悩ましいのは、「何を持って異常な気温」と定義するか?です。ここでは、「その日に通常は起こりえない気温となった日」を異常な気温と定義します。
改めて下を見ていただくと、何カ所か他とは傾向の異なる気温が記録されているのがわかります。
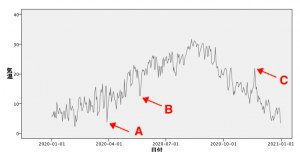
最も異常な気温は3つ目の矢印Cが差した「2020年11月20日」です。根拠は後ほどご説明します。
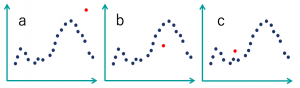
まず、異常値のパターンを3通り以下の赤丸で示します。aの様に全データの最大値だった場合は比較的簡単に検出することができます。一方で、bやcはどのように検出すれば良いでしょうか?単純に値の大きさで検出しようと思っても、異常値よりも大きな値も小さな値もたくさん存在します。
時系列トレンドに埋もれた異常値の検出
今回は、このように連続した時系列データの中で全体の傾向から大きく乖離した異常値を検出する方法を検討します。具体的には検証を要する値の直前までの移動平均を計算し、その移動平均値から検証値の乖離を見ることによって、異常度を判定します。もちろんさまざまな取り組み方法は存在しますが、より応用が利きやすいよう、極めて一般的な方法を選択します。
ちなみに、故障検知に取り組むとaのような「このような値はあり得ない」というケースに遭遇します。多くの場合、センサーの異常などに起因しますが、こういった前提知識から異常をフィルタリングするのは容易であるため割愛します。
平均値からの乖離による異常の測定
異常値の特定にあたり最初に、各気温の平均値との比較を検討します。
東京観測所の2020年の年平均気温は「16.55℃」でした。平均値の線を引くと以下のようになります。
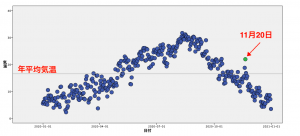
先に異常値と説明した11月20日は平均より5.4度高いのですが、年平均と比較してもあまり意味がないとすぐ気づきます。せめて「11月の平均より何度高い」が一般的な感覚かと思います。
そこで月平均との乖離を表したグラフが以下です。黄土色の折線を見ると月平均とどの程度乖離したかが捉えやすく、一見とてもいい感じです。
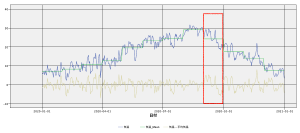
しかし、ここでもう一度グラフを見て下さい。特に赤枠に注目すると、9月1日~9月30日までに日平均気温が大きく下落している傾向があります。しかし、平均気温は9月1日でも9月30日でも全く同じ値を使うことになります。結果的に、9月のように1ヶ月の間に値の傾向が大きく変化してしまう月に「月平均気温との乖離」を計算する方法は適切ではありません。
もう少しイメージしやすい形で説明すると9月1日(夏休み明けのあの忌々しい初日登校日!)に平均気温が30℃近くあっても、それほど異常とは感じないかと思います。しかし、そろそろ運動会の練習が大詰め(最近は5月に運動会をやる学校も多いですが!?)を迎えた9月30日、日々の平均気温は20℃前後の涼しい季節になり、夜は少し肌寒さを感じるようになった時期に平均気温が30℃に達したら、、、これは異常です。
移動平均を使った乖離計算
このように常に方向性(ここでは季節変動)のある変化を有するデータにおいて、その乖離を計算する場合に有効な方法が「移動平均」と「移動平均からの乖離」を測定する手法です。
そして、この「移動平均」を計算する上で必要になってくるのが、@関数です!あ、ここまで読んでくださった方、ここまでが前置きで、ここからが本題です!自分でもビックリ!
移動平均は当日を含んで移動する一定の期間の平均のことです。新型コロナウィルス報道でも「7日間平均」として報道されるようになりました。移動7日間平均と呼ぶと1週間分の凹凸やノイズが除去され、トレンドをより的確に把握するのに便利です。7月7日の移動平均と呼ぶと、7月1日から7日までの平均ですので計算も明確です。
前回のTips#12で出題してあった例題を用いて詳しく説明します。
例題:「前日までの7日間移動平均を求める」
前回のブログで出題したのは、「日毎の気温データから前日までの7日間移動平均を求めてください(1手詰め)」でした。なぜ、当日を含まない指定したのか疑問に思われた方も多いと思います。異常検知の経験上、当日気温に異常があった場合、当日の異常な気温も含めて平均値を計算してしまうと、その異常さが見えづらくなってしまうからです。
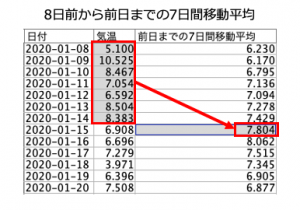
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/tokyo_daily_weather.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
3通りの完成ストリームがこちらです。
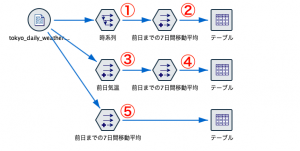
まず「フィールド設定タブ」の「時系列ノード」を利用する方法です。①の「時系列ノード」で「気温」を選択してオフセットは1、スパンは7で設定すると7日間前(オフセット)までの連続したフィールドが作られます。

続いて②のフィールド作成で追加された7フィールドを合計します。福岡大学の太宰先生が推しノード#15の「おまけ」で解説された@FIELD_BETWEEN(A,B)を使って7つのフィールドをリスト化してから、mean_n(リスト)で平均を求めます。

出来上がると、こうなります。前日までの7日間を保有する最初のレコードは1月8日ですのでそこに着目すると、確かに赤枠の中に気温から1日前、2日前と順番に7日前までの気温が並べられ、その平均が最終フィールドに作られています。これまで推しノードやTipsで紹介されなかった時系列展開して横方向に計算させる方法です。
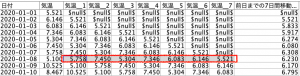
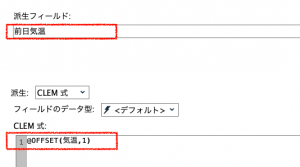
次は縦方向に計算させる方法です。もし当日を含む一般的な7日間移動平均でしたら@MEAN(気温,7)で1手詰みなのですが、前日以前のためワンクッション入れるのが③です。@OFFSETはこのTipsでも繰り返して登場していますね@OFFSET(気温,1)と記述すると1日前の気温を参照します。
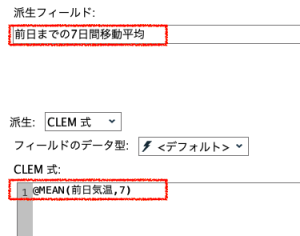
あとは④でこの前日気温フィールドをターゲットに@MEANで縦方向の平均をとれば完了です。個人的にはこの方法がわかりやすく、他の特徴量を作る際にもおすすめです。
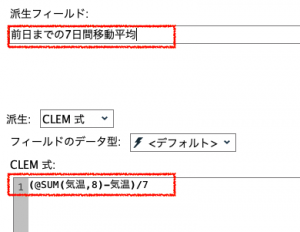
最後に1手詰め⑤です。当日を含む移動8日間から当日気温をマイナスしてから7日で割り算する方法です。
詰将棋例題は以上です。
ここからは移動平均の期間を30日に広げて気温の異常値を検討します。グラフみてわかる通り、7日よりもノイズが除去され、よりスムーズなトレンドを示しています。こちらが安定した検知に向いていることがわかります。
偏差値を使った異常度判定
季節毎の気温のばらつき方に違いがある(季節によって標準偏差に違いがある)ことを考慮してその異常度を判定するには「偏差値」が便利です。
偏差値と言えば、学生時代、一喜一憂した、また、その数値一つで人生を左右された!などという方もいらっしゃるかもしれません。この偏差値は、数学的には平均を50として、標準偏差が10になるように設定した値と定義できます。(データの自動準備ノードにあるz標準化や正規化を使う方も多いかもしれません)
今回の計算には、移動標準偏差を用います。以下のように30日の移動平均と同様に計算した同期間の前日気温標準偏差を示しています。これも@関数で計算でき、先の例題を30日間移動平均にしてから以下のように記述します。

結果、もっとも際立った偏差値は11月20日の86.1!でした。
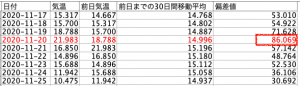
グラフで書くとこんな感じです。
偏差値だとなんとなくなじみが深いのでわかりやすいと思いますが、偏差値86.1というのは、0.023%の確率でしか起こらない事象です。もう少しわかりやすい言い方をすると、4300日に1回の珍しい気温、と言い換えることができます。1年は365日ですから、ざっくり12年に1度の珍しい天気と言い換えることができます。
これは経験的ですが、正規分布が保証されているケースでは偏差値換算した後、偏差値が15以下、または85以上の場合は、何か極端なことが起こっていると考えられます。
そもそも本当に正規分布しているのか?
移動平均からの乖離を偏差値にして異常を見つける方法は、値が正規分布していることが前提にあります。
実際に2020年の移動平均からの乖離のヒストグラムを示します。
いかがでしょうか??う~ん、微妙、というのが正直なところと思います。なんとなく正規分布しているように見えますが、データ数が少なすぎていまいちはっきりしません。
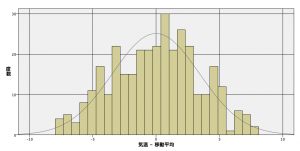
1年分のデータではどんなに頑張っても限界があります。そこで、2020年のデータだけではなく1962年から約60年分のデータで確認してみました。
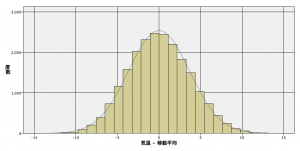
いかがでしょうか??かなり正規分布に近い形になっていることが確認できます。
実は正規分布よりも若干左に寄っていて、それは移動平均の特性に関係しています。そこを掘り下げると今回の方法は「季節外れの暖かさ」と「季節外れの寒さ」のうち比較的前者に向いている特徴を持つ説明をするべきなのですが、その理由は別の機会にでも。ただ後者の検知に注力するときにはまた別の工夫が必要だと承知しておいてください。
異常値検知のまとめと皆様へのお願い
ここまでで、時系列の山谷の中に存在する異常値を、移動平均と偏差値から検知できることがお分かりいただけたと思います。実際には、異常を検知する目的に応じて適切な特徴量準備や統計手法の選択、その前提になるデータの洞察が必要です。そしてその時最も重要なのが「試行錯誤が素早くできるか?」です。SPSS Modelerの@関数にはこれまで幾度となく助けられてきたのですが、億単位のデータを相手にする様になり、SQLプッシュバックが効かない@関数を使わず「いかに他の方法で同じことを高速にできるか」模索している毎日です。
もし同じようにデータベース接続で「大規模データに@関数でSQLプッシュバックさせたい」方こちらにぜひ一票お願いします。
https://ibm-data-and-ai.ideas.aha.io/ideas/MDLR-I-319(外部サイト)
Modeler詰将棋!次回のTipsから出題
次の例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「お客様と物件をマッチングする」
以下のお客様希望情報①に合致する物件情報②をマッチングして③を作ってください。ただし、できるだけ程よく提示できるように3つの条件を前提としています。利用するノードは1つだけの1手詰めです。
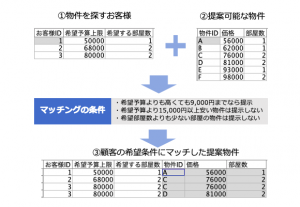
例題データ
利用する2つのデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/matching1_1.csv
https://raw.githubusercontent.com/yoichiro0903n/blue/main/matiching1_2.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
例題2:「お客様が購買していない商品のリストを作る」
以下のお客様の購入済み商品リストから、逆に未購入の商品リストをお客様毎に作ってください。4手詰めを模範解答として準備しています。もし3手以内でストリームができた場合には最寄りのIBM SPSS関係者にご一報ください。
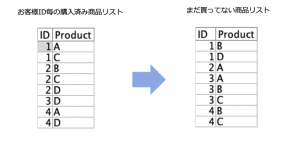
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/matching2.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
いかがでしょうか。IBMのイクメン棋士は例題1に5分、例題2には6分で解いたそうです。
さて次回のTips# 14はSPSSユーザーにはお馴染みの松本健さんに例題の解説をいただきます。
お楽しみに!

本田 智則
国立研究開発法人産業技術総合研究所
ゼロエミッション国際共同研究センター 主任研究員
東京都市大学環境学部 客員教授

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む