

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
Modelerデータ加工Tips#11-フィールド名を一括変換して見やすく整える
2021年06月30日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさんこんにちは 横浜国立大学 経営学部の鶴見と申します。
横浜国立大学 経営学部は、1923年設立の旧制 横浜高等商業学校を前身とする東日本では唯一の国立大学の経営学部です。2021年度からはデータサイエンス教育プログラム「DSEP」(ディーセップ:Data Science Education Program)をスタートし、経営とデータが重複する領域の教育にも力を入れています。
経営学部での私の担当は、マーケティング、マーケティング・リサーチの研究・教育です。ゼミナールでは調査データの収集、分析からマーケティング企画の立案まで、マーケティング・リサーチ全般に関わる指導に取り組んでいます。
私とSPSS Modelerの出会いは、2001年頃にさかのぼります。当時のエス・ピー・エス・エス株式会社のコンサルティング・チームをサポートするアルバイトとして、大学院生だった私がお世話になったのが切っ掛けです。私はプログラミングが必要な分析ツールをメインで使っていましたので、操作性に優れるSPSS Modelerに初めて触れたときは衝撃を覚えました。また、複雑なデータ加工、分析を含んだクライアントへのご提案でも、SPSS Modelerを使った数日の研修で技術移転が済んでしまったと聞き、2度目の衝撃を受けたことを今でも覚えています。企業とデータ分析の関わり方がSPSS Modelerによって大きく変わってゆく、時代の変化を間近で感じる日々でした。
そして、当時からSPSS Modelerのクライアントは一流の企業ばかりでした。コンサルティング・チームのサポートを通じ、それらの企業がマーケティングの最前線で収集したデータを分析できた経験は、今振り返ると、その後の研究者人生の支柱となる経験でした。今は学生達を教える立場になりましたが、先ほどご紹介したDSEPの学生達にも、私の様な経験を企業でのインターンなどで積んでもらえば、学生達にとってどんなに良い経験になるだろうか、と日々思っています。
あれから約20年。SPSS Modelerがより高度な機能を備えつつも、当時と変わらぬユーザー・フレンドリーなソフトウェアとして、ユーザーの支持を拡大していることを大変嬉しく思っています。
本日は、当時だけでなく今日においても、効率的なデータ加工に欠かせない、フィールド名の一括変換に関するノードの利用方法を紹介いたします。
例題1:「取引明細データから月別の部門売上テーブルを作成」
Modelerが得意とするデータの横持ち変換です。大分類の7つの部門を列に展開して月別に集計します。
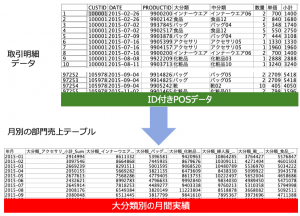
データは東京図書様に許可をいただき「実践IBM SPSS Modeler ~顧客価値を引き上げるアナリティクス」の紹介ページにあるダウンロードサンプルデータ「sampletranDEPT2015.csv」を利用いただけます。
解答例は次の通りです。

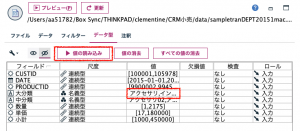
可変長ファイルノードでデータを読み込む際に、データ型タブの「値の読み込み」ボタンで値を確定しておきます。これをしないと②で列展開するべきメンバーが見当たらず途方に暮れることになります。データ型ノードを置いて同じことをしても結構ですが1手無駄にするため、入力ノードで済ませておきました。
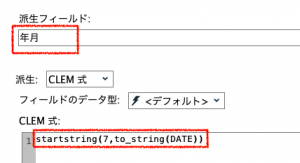
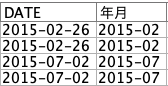
最初に①のフィールド作成ノードで「DATE」から「年月」フィールドを作ります。日付型のDATEを文字列変換するためto_string(DATE)とした上で、先頭7文字のみ残して消去するため以下のように文字列関数を記述します。
出来上がるとこうなるはずです。
ここからは推しノード#04や過去のTipsでも紹介された再構成ノード必勝リレーですね。
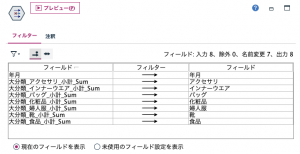
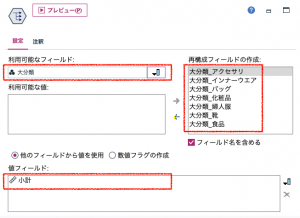
②の再構成から。「大分類」を利用可能なフィールドに選び、黄色い矢印で7つの部門を再構成フィールドへ移します。「フィールド名を含める」はチェックのままにしておいてください。「大分類_」という接頭辞が付きます。値フィールドは「小計」を選択します。値フィールドを指定したので「_小計」のように接尾辞が付きます。
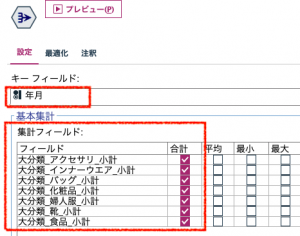
③レコード集計です。ここで部門の小計を合計した結果フィールド名は「_合計」の接尾辞が重ねて付くことになります。
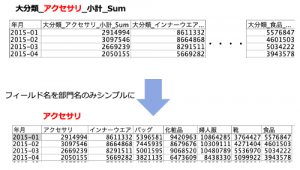
④最後は「年月」を昇順ソートします。

出来上がりました。こういった集計が即座にできるのがModelerの良いところですよね。ただ、「大分類_アクセサリ_小計_Sum」という長くて不明瞭なフィールド名は報告書に載せられません。次の例題で解決してみます。

例題2:「フィールド名の一括変換」
行いたいことは以下の通りです。アクセサリの前後の接頭辞や接尾辞のカットです。
「フィールド名の変更ならフィルターノードでしょ?」と以下の手作業を始める方もいらっしゃるかと思います。7フィールドですので、工夫の余地より手を動かしても良いと思います。しかしフィールド数が結構な数ある場合は機械的に変更したいはずです。自然言語解析をされるユーザーをはじめ、この点にお困りの方は多いのではないでしょうか。
データは例題1で完成したものを利用するか、以下URLで入手ください。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/Longfieldname.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
模範的な手続きはこちらです。3手詰めです。

まず①の行列入替でフィールド名を列名に含めてしてしまいます。行列入替はすでにTips#04とTips#10で取り上げられてきました。とりあえず試してみないとどう動くかわからない、ミステリアスなノードです。
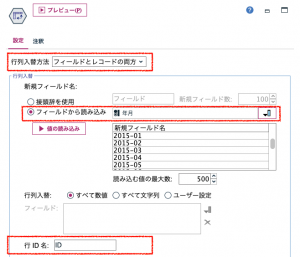
フィールド名が「ID」のケースとなり編集できるようになりました。

②置換でアンダースコアで区切られた文字列の2列目を抽出します。Tips#06でも触れられていますが、この関数はCHAR(文字)を扱うのでバッククォート(`)を利用します。
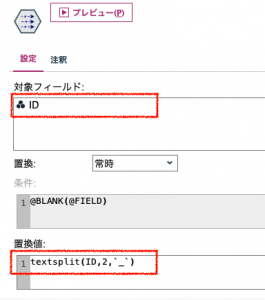
前後の文字列が消去されました。
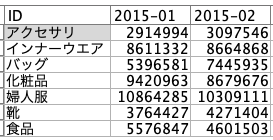
あとは行列を戻せば良いので③以下のように設定します。
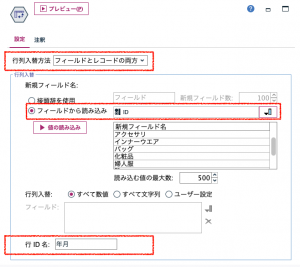
出来上がりを確認します。
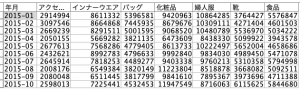
表計算ソフトとレガシースクリプトでフィールド名を一括変換
出題時にもPythonで実現する方法はIBM河田さんが紹介されているとお伝えしました。Pythonスクリプトを利用した例はこちらです。
実はPythonがModelerに搭載されたのは2013年の12月バージョン16。それ以前は、現在も残されている「レガシースクリプト」でループ処理などをしていました。このModelerスクリプトは表計算ソフトで下ごしらえしたもの(セルの循環やコピー)と組み合わせると非常に便利に利用できます。大学院生時代には推しノードでも登場する福岡大学の太宰先生と、しばしば裏技テンプレートを作っては、恵比寿のSPSSオフィスで共有、スタッフの皆さんに役立てていただきました。
今回の例題2で説明します。
ストリームはフィルターノードです。
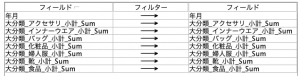
ここでスクリプトを利用します。メニューから、ツール>ストリームのプロパティ>実行を選択します。以下の①はPythonではなく「従来のもの」を②の作り方を一旦飛ばして③で実行します。
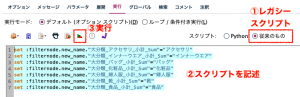
以下のようになります。フィールドが100を越えても②が作れれば楽チンです。
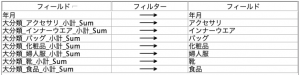
では、②をどう作るかなのですが、
まず入力ノードをプレビューします。そしてメニューから編集>全て選択を選んでから、フィールドと一体のコピーを選択。
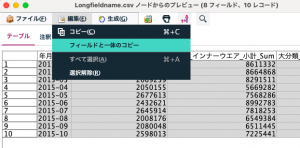
表計算ソフトで行/列の入替でA列にペーストします。あとは文字のルールに合わせて、最終的なフィールドをC列のように準備します。

最後に旧フィールド名と新フィールド名がスクリプトに埋め込まれるようにセルの結合を行います。AからEまでを「&」で文字列結合したものがF列です。

F列をコピーすれば先の②で利用可能になります。最初にシートに関数を仕込むときには時間がかかりますが、繰り返し実行する定番の分析作業では不可欠なものになる場合があります。式ビルダーで長い条件文を書くときもこの方法を思い出していただくと良いと思います。
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「顧客毎の累積購入金額を算出する」
顧客3名の日毎に集計された売上データから顧客毎の累積金額フィールドを作ってみてください。利用ノードは2つです(2手詰め)。
実は力技で1手詰め可能(解説予定)なのですが後続の例題を考慮して、購入回数フィールド作成に1ノード割り当ててください。
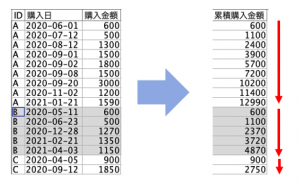
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/DataTips12.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
例題2:「累積2000円までの日数を算出する」
例題1の完成データを用いて顧客が累積2000円に到達するまでの日数を求めてください。フィールド名は気にせず3手詰めです。
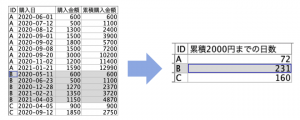
例題データ
例題1の完成データをそのまま使うか以下を利用ください。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/DataTips12_2.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
いかがでしょうか。IBMイケメン棋士は例題1に4分、例題2には5分で解いたそうです。
さて次回のTips# 12は浜銀総研の中村さんに例題の解説をいただきます。
お楽しみに!

鶴見 裕之
横浜国立大学
大学院国際社会科学研究院/経営学部 教授
学長補佐
More SPSS Modeler ヒモトク stories

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む
