

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
Modelerデータ加工Tips#10-時系列データを加工して95%予測上限と下限を求める
2021年06月07日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさんこんにちは。東京ガス株式会社の笹谷と申します。
弊社は、海外から液化天然ガス(LNG)を輸入し、LNG基地で都市ガスを製造、パイプラインを通して都市ガスを供給し、家庭用・業務用・工業用等のお客さまに販売する「都市ガス事業」を中心に、「電力事業」や「海外事業」、「エネルギー関連事業」などを展開しているエネルギー企業です。
私の所属するデジタルイノベーション戦略部データ活用統括グループでは、これら一連の事業活動に対してデータやアナリティクスを活用することによる業務改革や新たな価値創出に取り組んでいます。
私がSPSS Modelerを使い始めたのは2014年ごろでした。それまで当社では、SPSS Statisticsなどの統計解析ツールなどを用いてデータ分析を行っていましたが、いわゆる「ビッグデータ」ブームの到来と共に、扱うデータ量・種別が拡大しデータ加工の負担が大きくなってきたこと、データ分析に携わる人が増える中で培ってきた分析のプロセス・ノウハウを蓄積する必要があることから、SPSS Modelerの導入を決めました。以来、複雑なデータ加工もわかりやすく管理でき、過去の分析資産が蓄積されるSPSS Modelerは業務に欠かせない存在になっています。
業務においてSPSSを用いる良くある場面の一つが、需要予測や売上予測、故障発生件数予測など、様々な「予測」です。このTipsではそんな予測の過程で役に立つ、データ加工と予測区間算出に関してご紹介します。
例題1:「予実管理テーブルを分析用に加工する」
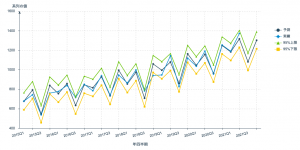
元データと完成イメージです。業務で用いられる予算と実績の管理シートは、見やすさを優先していて、予測などに利用しようとすると結構大変ですよね。例として以下のような行列を分析用テーブルに変換してみます。
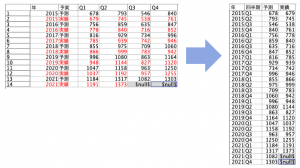
利用するデータはこちらです。
https://github.com/yoichiro0903n/blue/blob/main/forecast_before.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
本題からそれるのですが、出題イメージの元データをよく見ると実績が赤字になっているのに気づきましたでしょうか?テーブル表示する際には、一般的には何も設定なく実行すると思うのですが、設定タブで条件を指定していると、該当レコードが赤字で強調表示されます。

では解答例です。出題時にお勧めしなかった行列入替を用いる方法から。データにヌル値が含まれていなければ①と⑦が不要になり最有力の手筋となるはずです。

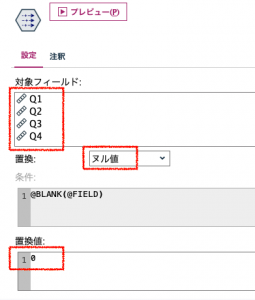
行列入替ノードはModelerバージョン18.2.2(ブログ執筆時点)ではヌルを受け取ると適切に処理しない仕様になっています。Tips#04でも、ウエスタン・デジタル小杉さんが行列入替ノードの気難しさに触れていますよね。仕方がないので①のようにヌルをゼロに置き替えます。
次に②で行列入替ノードを利用します。行列入替方法と索引、値を設定します。
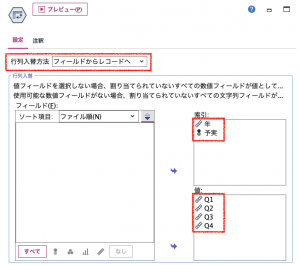
この時点で以下のようなテーブル構造になります。あとは予測と実績を列に展開すればOKですので、③データ型ノードで「値の読み込み」ボタンで型を認識させた上で④再構成の出番です。
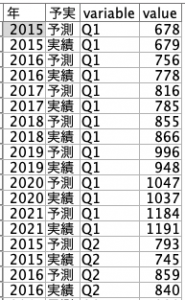
④再構成の設定は以下の通りです。予測フィールドと実績フィールドにvalueを埋めます。
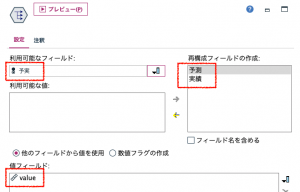
あとは再構成後の不要レコードの処理をレコード集計⑤で行い、ソート⑥します。推しノード#04でIBMの河田さんが触れている通りデータ型から再構成、そしてレコード集計はModelerの定跡(じょうせき)と言えます。

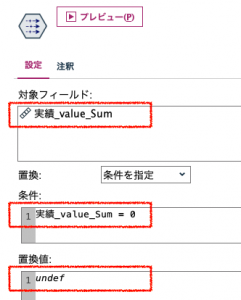
最後⑦は①で便宜的にゼロにしたヌルの2箇所を復元します。ヌルにするときの関数はundefです。
ここからは5手詰めの最短手筋です。ユーザー入力ノードを使います。このヒモトクTipsでは架空のサンプルデータを作る際に利用されていますし、推しノード#02でIBM西牧さんがシミュレーションの利用用途を示されていますが、暦情報の用意にも応用できます。
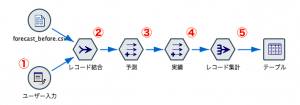
まず、ユーザー入力ノード①を次のように設定します。

この時点で対象にしているデータは以下の通りです。14レコードの本来のデータと、たった今作られた4レコード1フィールドのデータです。

2つのテーブルを結合キー方式にしながら結合キーなしで、レコード結合②します。
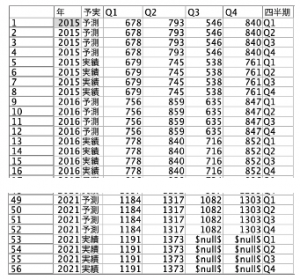
14レコードに四半期4レコードが14対4で結合し56レコードの全ての組み合わせが作られました。
③と④ではそれぞれ該当する予測フィールドと実績フィールドをif thenの条件によって作成します。


出来上がるとこうなります。
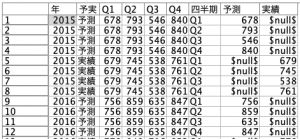
あとは⑤レコード集計で該当レコードが残るように要約します。
例題2:「95%予測上限と下限を求める」
将来の予測を幅で見込めると、在庫リスクや機会ロス減少につながると推しノード#14でも解説されています。実はModelerの「時系列ノード」は95%の予測上限と下限を自動で算出できますが、それ以外の機械学習アルゴリズムでトレンド予測した場合にはでません。そこで例題1で出来上がったデータから95%の予測区間の自作にチャレンジします。
データは例題1で完成したものを利用するか、以下URLで入手ください。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/forecast_after.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
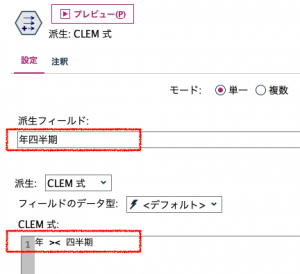
まず、①のフィールド作成ノードでグラフのX軸となる年と四半期の合成変数を作ります。単純な文字列結合ですので「><」を使います。
ここで95%予測上限と下限を求める式の確認をします。出題時のものを再掲します。

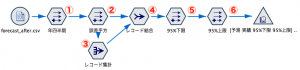
まず区間推定に必要な推定値の標準誤差を求めるため②誤差平方フィールドを作成します。

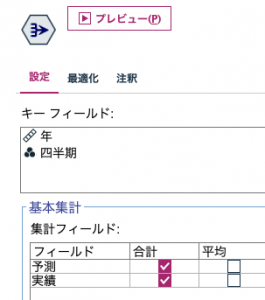
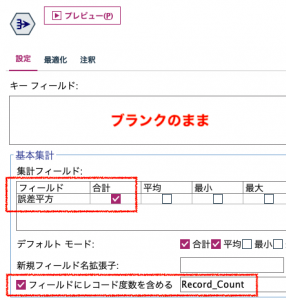
さらに誤差平方和を得るべく、③のレコード集計で和を求めます。レコード度数はデフォルトのまま計算させて、後続処理で利用します。
誤差平方和を全てのレコードに付与するために④でレコード結合します。結合方法はキーにしますが、実際のキーはブランクです。
⑤と⑥のフィールド作成での式は以下の通りです。


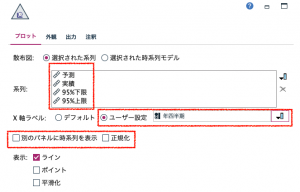
ここまでで6手詰めですが、グラフ表示を2種類紹介します。時系列グラフで以下のように設定します。
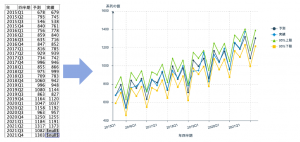
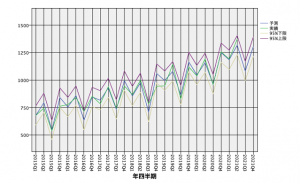
実行すると予測と実績に加え上限と下限のチャートが表示されます。
最後にModeler18.2で搭載された、グラフ機能を利用します。
⑥のノード上で右クリックして「データの表示」を選択します。
グラフタイプから複数時系列を選びます。
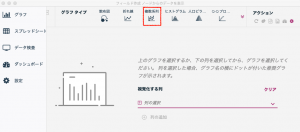
あとはX軸に年四半期とY軸に予測を選択します。系列を増やすためプラスボタンを押してY軸のメンバーを増やします。
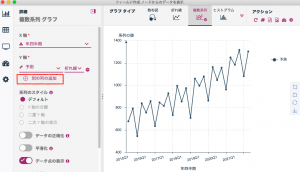
4つのフィールドを選択すれば完了です。格好良いグラフが出来ました。
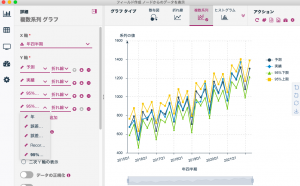
今回の95%予測上限と下限は動画「3分アナリティクス」でも取り上げられています。ご覧ください。

Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「取引明細データから月別の部門売上テーブルを作成」
取引データから以下の月別の部門売上テーブルを作ってみてください。利用ノードは4つです(4手詰め)。捻りなしのシンプルなサービス問題です。
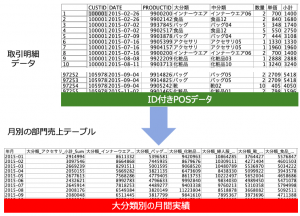
例題データ
東京図書様に許可をいただき「実践IBM SPSS Modeler ~顧客価値を引き上げるアナリティクス」の紹介ページにあるダウンロードサンプルデータ「sampletranDEPT2015.csv」を利用いただけます。
例題2:「フィールド名の一括変換」
例題1で作成したテーブルのフィールド名にある部門の接頭辞や接尾辞を消去してください。フィルターノードによる手作業やPythonスクリプトの自動処理は利用しない前提にします。3手詰めです。
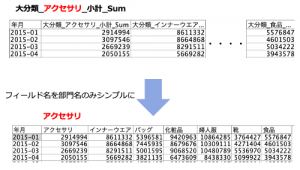
データは例題1で完成したものを利用するか、以下URLで入手ください。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/Longfieldname.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
Pythonスクリプトを利用した例はIBM河田さんがこちらで紹介されています。
いかがでしょうか。IBM所属のSPSS Modeler 女流名人は例題1に5分、例題2には6分要したとのこと。
次回のSPSSヒモトクブログはSPSSオンラインユーザー会イベントを運営者であるスマート・アナリティクスの畠さんがレポートされます。私の事例セッションも紹介いただけるそうです。
そちらを挟んだ後に、Tips# 11は横浜国立大学の鶴見先生に例題の解説をいただきます。
ご期待ください!

笹谷 俊徳
東京ガス株式会社
デジタルイノベーション本部
デジタルイノベーション戦略部
データ活用統括G
More SPSS Modeler ヒモトク stories

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む
