

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
Modelerデータ加工Tips#03-欠損値に直前の値を代入または線形補間する
2021年03月19日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさん、こんにちは。株式会社ビデオリサーチの田村玄です。
私は、学生時代も含めると約20年、SPSS Statistics, SPSS Modelerを使い続けています。当社はメディアリサーチを生業としておりますが、私は、リサーチデータの加工から集計・解析、また、リサーチデータを活用したサービス開発など、広範囲にわたりSPSSを使っています。昨今はリサーチデータだけではなく、ログデータを扱うことが多くなっています。必然扱うデータ量は多くなり、苦労する点もありますが、データ加工や統計解析といったスキルがベースになることは変わりません。若い方々にはこれらスキルを身に着けることをお勧めします。
このTips#3ではModelerの「欠損値NULLの代入」を紹介します。
欠損値は分析者を悩ませます。例えばアンケート調査では性別や年齢、収入など、なんらかの回答項目が無回答や無効になりますよね。もし大規模アンケートの場合1箇所でも欠損したデータを見つけたらレコード毎削除もO Kですが、数百のサンプル数の場合には、抜け落ちた値をなんとか補完して利用するのが一般的です。その補完方法にもいくつかのテクニックがあり、、SPSS StatisticsではオプションモジュールMVA(Missing Value Analysis)が幅広くサポートしています。
このTipsはアンケートではなく、IoTセンサーを想定します。そして通信状態に起因する欠損データがやってきた場合の対処方法をご紹介します。
前回のTips#2で出題した、欠損値の処理は、解けましたでしょうか?
以下のように4レコード欠損しているセルを直前の代入と線形補間してみたいと思います。データは自作いただいても良いですし、出題時のPythonスクリプトを使うと楽チンです。メニュー>ツール>ストリームのプロパティ>実行で、セットアップできます。
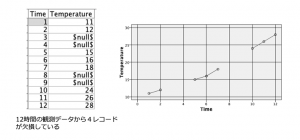
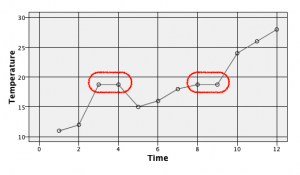
対象データとグラフ
例題1 欠損の直前の値を代入する
行いたいことは以下の通りです。

完成ストリームとひとつ目の置換ノード設定は以下のようになっています。一度ユーザー入力ノードで正解データを作成した上で該当4レコードをヌルに置換えています。3つ目の置換ノードから本題開始です。
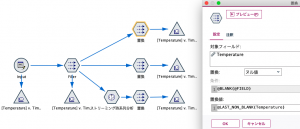
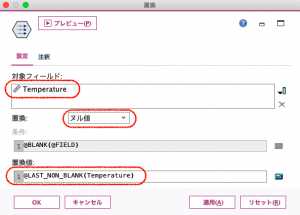
置換ノードの設定をします。欠損値ヌルを見つけたら、ヌルではなかったレコードまで遡って置換えます。
結果をグラフで確認します。赤枠が補完されたレコードです。直前の値にそのまま従っているのが分かります。
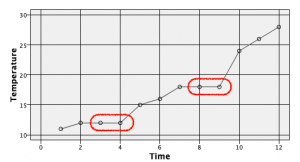
欠損を平均値で代入する
最小値・最大値や平均値を代入する方法も多用されます。平均を例にして2つのパターンを紹介します。
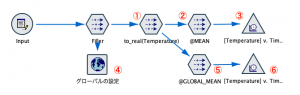
欠損値が発生した時点以前の平均を利用する方法を説明します。
まずは平均値が小数になる想定をして、①でフィールドをinteger(整数)からreal(実数)型に変更します。
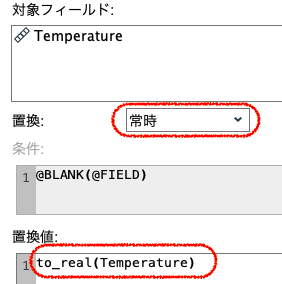
次に②の置換ノードで@関数を利用し、以下のように式を作成します。
③グラフで結果を確認しています。欠損時点までのデータの平均値を代入しているのが分かります。
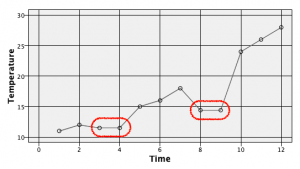
全てのレコードの平均を計算して、それを代入する方法もあります。
ここではグローバルの設定を利用します。
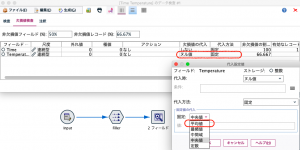
④のようにグローバルの設定を接続して、平均を指定し実行ボタンを押下します。これでこのセッション中は平均値がキャッシュされ関数で呼び出せます。
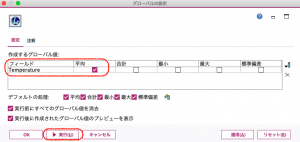
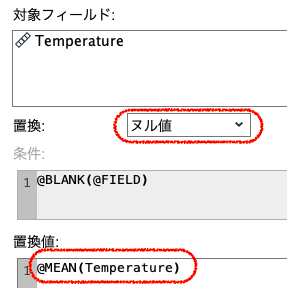
続いて⑤で置換を行います。式ビルダーを起動し、画面右の「フィールドリスト」の▼をドロップダウンをするとグローバル値が表示されます。これを黄色矢印でエントリーするだけなので、タイプ不要です。現在の値欄を見ると平均値が18.75だと確認できました。
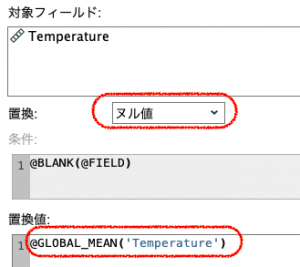
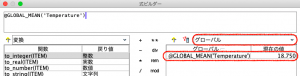
⑥でグラフから欠損が代入された結果を確認します。グローバルの設定で求めた平均値、18.75が代入されています。
平均値だったら「データ検査ノードからでもいいのでは?」と思われた方もいらっしゃるかと思います。→推しノード#3「データ検査」はこちらから
推しノードブログでは外れ値の処理が紹介されていますが、欠損値の代入をヌル値に指定し代入方法を平均値に設定すると、生成メニュー>欠損値スーパーノードが出来上がり⑥と同じ結果を得ることができます。
そして、平均以外にも最頻値や中央値のような値も選べる上、多変量の場合には、なんとアルゴリズムCARTを用いた欠損値補完もできてしまいます!
例題2 欠損値を線形補間する
例題1では特定の値や代表値を使いましたが、線形補間にチャレンジします。

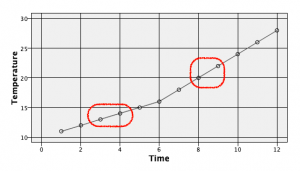
なぜ線形と呼ぶのかはグラフを見るとよく分かります。6時間目以降で傾斜に変化が起きますが、欠損した値をナチュラルに補間しています。
作成するストリームは以下の通りです。
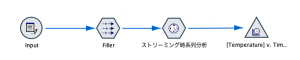
ストリーミング時系列分析をレコード設定タブから選んで配置してください。「何そのノード?」という方は 推しノード#14「時系列」をご覧ください。モデルナゲットでスコアリングするのがModelerのお作法ですが、この「ストリーミング」と始まるものは文字通り読み込みながらモデルを作り、プロセスノードとして予測してしまいます。
今回は自分の過去のトレンドを説明変数にして自分を予測するモデルを作るため、対象にのみTemperatureを選びます。
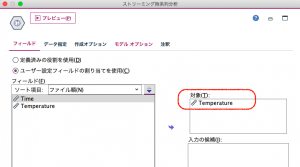
データ指定タブで時間単位を定義する必要があります。期間フィールドにTimeを選択します。
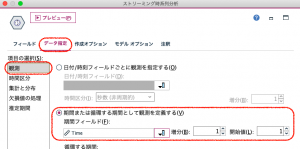
「欠損値の処理」の設定を確認しておきます。初期設定が線形補間になっているので、そのままOKしてグラフを実行します。
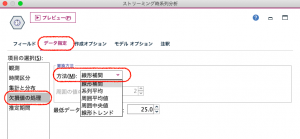
きちんと線形補間できています。
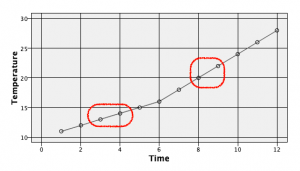
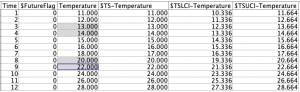
目的変数や説明変数に欠損があっても予測を成立させるための線形補間機能を利用しました。
線形補間をストリーミング時系列なしで行う
事前に準備していた解答例7手詰めはこちらです。
なんと、日本アイ・ビー・エム・システム・エンジニアリングの都竹さんから6手詰めストリームが出来たと連絡をいただきました。実は先の7手詰めは、一見シンプルですがソートを2回繰り返す5G時代に逆行した非効率な戦法でした。それに対して都竹さんは序盤から意表を突くレコード集計から区間にラベルをつけて再結合するという魔法のような圧巻の手筋でした。ご自身のQiitaに紹介をお願いしました。
是非覧ください。
Modeler詰将棋!次回のTips から出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「Precisionを作ってみる」
精度分析ノードやクロス集計で求めずPrecisionを自作してみてください。利用ノードは2つです(2手詰め)。結果のフィールド名はどのようなものでも結構です。
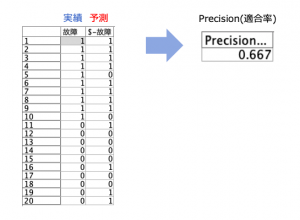
Precisionの計算方法は以下のとおりです。

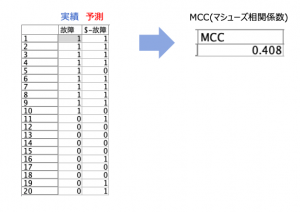
例題2:「MCCを作ってみる」
同じデータでMCC(マシューズ相関係数)にもチャレンジしてみてください。
こちらは結構複雑です。過去のModeler詰将棋で使わなかった駒の検討をしてみてください。4手詰めです。もし3手以下で投了に持ち込めた強者がいらしたら、IBMのこのブログ運営をしているSPSSテックチームまでご一報ください。
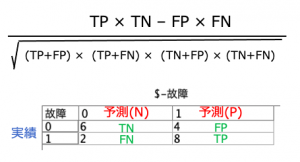
例題のデータのセット方法①(手入力)
エクセルなどで手入力準備よりも、ユーザー入力ノードが便利です。
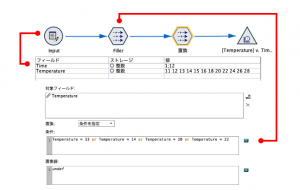
フィールドに「故障」と「$-故障」、ストレージは両方「整数」。データの生成は「順番」に。
値は「故障」に「1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0」
「$-故障」に「1 1 1 1 0 1 1 1 1 0 1 0 0 0 0 1 0 0 1 1」を入れてください。

精度分析を利用して正誤行列を確認する場合のためにデータ型はフラグにしておきます。

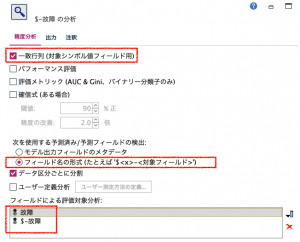
精度分析ノードでデータの入力が正しいか確認するには、一致行列にチェックし、フィールド名の形式にラジオボタンを合わせてください。$がついたフィールドが予測であると認識します。推しノード#23「自動分類」で紹介されたようにフィールドによる対象分析に2つのフィールドを選ぶことでPrecisionが求められ、正しく入力できているか確認できます。
例題のデータのセット方法②(pythonスクリプト)
メニュー>ツール>ストリームのプロパティ>実行で以下のスクリプトをコピー&ペーストし再生ボタンを実行すると二つの例題のユーザー入力ノードが自動生成されます。
難しそうですね。IBMのSPSS Modeler ベテラン棋士は例題1に3分、例題2は7分要したとのこと。
今回ブログ本編で取り上げた欠損区間の補完ですが、コロナ収束の目処が立たない現在に通じるものがあると思います。会えない人がどう過ごしているか思いを馳せ、元気でいて欲しいと願う日々です。春のSPSSオンラインユーザー会は5月21日だと伺いました。1日も早くSPSSユーザーの皆さんと、同じ場所で刺激を与え合える日が来ることを願います。
次回Tips# 04で解答例を説明いただくのはウエスタンデジタルの小杉さんです。
お楽しみに!!

田村 玄
株式会社ビデオリサーチ
ソリューション事業局 ソリューション開発部
データサイエンスグループ 課長
More SPSS Modeler ヒモトク stories

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む
