SPSS Modeler ヒモトク
Modelerデータ加工Tips#02-関数で任意の文字列を削除・抽出する
2021年03月10日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさんこんにちは、ヤマトホールディングス株式会社の杉野です。
読者の皆様におかれましては平素「クロネコヤマトの宅急便」をご利用頂き誠にありがとうございます。私が所属するデジタル戦略推進機能は、ヤマトグループが保有する多様なデータを活用した「データドリブン経営」の推進を目的に2020年度に新設されました。その中で私はデータサイエンティストとして、宅急便に関連するデータ分析を行っています。私共が扱う業務データは非常に膨大で、例えば2019年度の宅急便取扱個数は約18億353万個!(皆様のご愛顧の賜物です)こうした大量データをサクサクと加工したり、モデルをチューニングするのにSPSS Modelerを役立てています。
このブログをお読みの皆様も、Modelerで日々業務データと格闘されているのではないでしょうか。業務データはほとんどの場合、統計的に分析されることを前提としておらず、多くの労力が分析の前処理であるデータ加工に割かれます。特に数値以外のデータ型が厄介で、例えばカテゴリデータの再区分、数値内に混在している記号の処理、日本語テキストの扱いなどは苦行に近いものがあります。こういった迷惑系「文字列データ」を序盤で意味のある形にできるかが分析者の腕の見せ所でもあり、言うまでもなくこの局面での出来が成果に大きなインパクトを与えます。
そこで今回のTips#02ではModelerの関数を用いた「文字列の操作」を通じて、企業内データサイエンティストの皆様へ少しでもヒントを提供できればと考え執筆を引き受けました。少しでもお役に立てれば幸いです。
SPSS Modelerの文字列関数はQiitaで詳しい記事もあるので予め目を通して頂いても良いと思います。
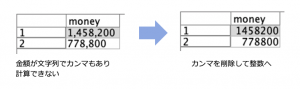
前回のTips#01で出題した、「金額の桁を表すカンマを削除し整数化」と「ログメッセージ内の[角括弧]文字列の抽出」は、解けましたでしょうか?
具体的な手順に従って説明いたします。
例題1「金額の桁を表すカンマを削除し整数化」
行いたいことは以下の通りです。
まずは対象データを読み込みます。
ユーザー入力ノードで入力してもテキストデータで準備いただいても結構です。
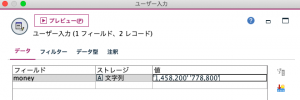
Pythonスクリプトを用いて、例題2と合わせてセットアップする方法はTips#01で出題の際に触れていますので、そちらを利用してもOKです。
対象データをテーブルノードで表示します。
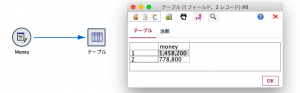
このmoney列を変更するので、置換ノードを配置して編集します。
置換ノードを詳しく説明した記事はこちら→推しノード#15「置換」
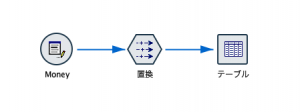
①と②まで以下の通り設定して、③の通り式ビルダーを起動します。
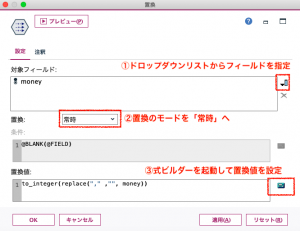
式ビルダーを起動したら、関数リストから「変換」を選んでto_integer( )を黄色矢印でエントリー。さらに、かっこの中に「文字列」の関数でreplace(?,?,?)を含めてください。タイプしながらto_integer(replace(“,” ,””, money))と記述します。
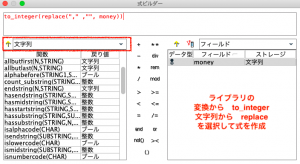
この式の表す内容は以下の通りです。

replaceで「カンマ」を「文字なし」へ変身させた上で、to_integerで整数化しています。
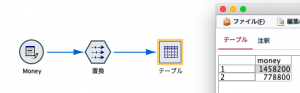
出来上がりを確認します。
例題2「ログメッセージ内の[角括弧]文字列の抽出」
こちらは、Serverや設備が記録するデータから事後のインシデントや故障を推測するための「文字列抽出」です。
例として以下のようにLogフィールドのメッセージから[ ]で囲まれた文字列を見つけた場合、別のフィールドに該当文字列を記述しようと思います。[ ]がなければヌルで結構ですし、2つ目や3つ目の[ ]が登場するケースは、この課題をクリアできた時点で実現可能になるはずです。

データをスクリプトからインポートをせず、手入力する方のために、Logを記します。
「931 INFO [LmtpServer-99] ;mid=149083; mailop – Adding Message: id=191」
ユーザー入力ノードを利用する場合には鉤括弧をシングルクォーテーションにしてください。入力ができましたらフィールド作成ノードを3つ連続で配置します。
フィールド作成ノードの詳しい記述はこちら→推しノード#7「フィールド作成」
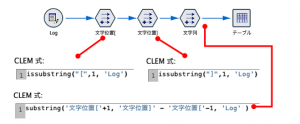
最初のフィールド作成は名称を文字位置 [とします。式ビルダを起動して
下の図のように記述します。
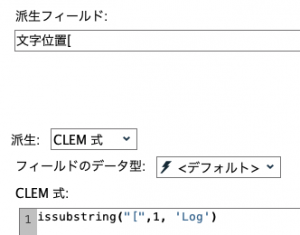
以下のようにこの関数で[の文字位置を整数で求めることができます。

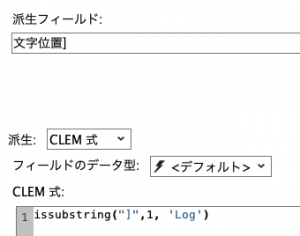
次に右括弧]を探して抽出終了位置を特定するフィールド文字位置]を作成します。
ここまででプレビューすると以下になるはずです。
![]()
ここで括弧の文字位置を確認します。このケースだと左括弧11文字目の次の12文字から、13文字を抽出すればOKです。13文字の文字数の求め方は
25–11–1です。終了位置と開始位置の差から1を引けば良さそうです。

これを関数substirng(A,B,C)で表現します。フィールドCのA番目からB文字の文字列を表示します。

実際のフィールド作成は以下のとおりです。

出来上がりを確認します。文字列が上手に抽出されています。
![]()
今回はフィールド作成を3つ使いましたが、ひとつに統合して済ませるには以下の式になります。
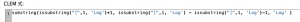
他にも1手詰めの例を挙げておきます。
STRING(文字列)はダブルクォーテーションで囲みますが、CHAR(文字)はバッククォート(`)を使うので注意してください。
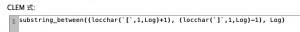

システムログから特定文字列の有無や回数に目をつけ、機械学習で予測モデルにかける場合には、避けて通れない加工の例をご覧いただきました。いかがでしたでしょうか。
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「欠損の直前の値を代入する」
4つの欠損レコードに直前の値を埋めます。1手詰め(1ノードで完了)です。余力のある方は平均などの代表値を埋める方法も検討してみてください。

例題2:「欠損値を線形補間する」
直前の値ではなく、欠損する区間の前後を見て線形補間します。この例題も1撃必殺の豪打で1手詰め可能です。もしその会心の1手を使わなくても、ノードを丁寧に繋ぎ7手詰めする方法もあります。個人的には大駒(アルゴリズム)なしで数手かけ巧妙に寄せてゆく方がTipsらしく、チャレンジする甲斐があると思いました。もし7手未満&大駒抜きのストリームが出来た場合IBMのSPSS Techsalesチームがご一報望むとのことでした。

例題のデータのセット方法①(手入力)
エクセルなどで手入力でも結構ですし、ユーザ一入力ノードで一旦正解データを作ってから置換ノードで特定4レコードを欠損させる方法を紹介します。
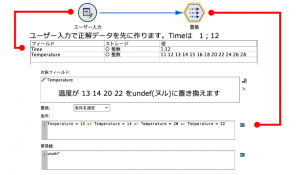
例題のデータのセット方法②(pythonスクリプト)
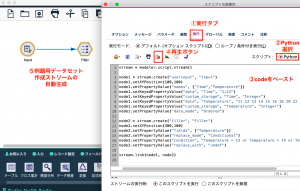
メニュー>ツール>ストリームのプロパティ>実行で以下のスクリプトをコピー&ペーストし再生ボタンを実行すると2つの例題のユーザー入力ノードが自動生成されます。
いかがでしょうか。IBM所属のSPSS Modeler 女流名人は例題1に2分、例題2は5分要したとのこと。
将棋をデータ分析に見立てる今回の企画は面白いですね。将棋の世界では「ヘボ将棋玉より飛車を可愛がる」という格言があり、戦闘力の強い飛車を大事にしすぎると、肝心の王様の守りが疎かになるという本末転倒を意味します。データ分析でも、解くべき業務課題(玉)を置き去りにして、パラメータ最適化だの、最新のライブラリといった飛び道具に夢中になる場合があります。武器は武器、手段は手段として冷静に盤上を眺めて、特徴量を的確に準備しモデルと施策の精度をあげてゆくためにも、今回のデータ加工Tipsの連載の意義は大きいと思いました。
さて次回のTips# 03はビデオリサーチの田村さんに例題の解説をいただきます。
ご期待ください!

杉野 恒男
ヤマトホールディングス株式会社
デジタル機能本部

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む