

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
Modelerデータ加工Tips#01-「キャッシュ」で後続処理の効率をアップ
2021年02月26日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさんこんにちはIBMの斉藤明日香です。
IBMテクノロジー事業部でデータサイエンス・ソフトウェアのエンジニアをしています。最近愛猫の活動をIoTセンサーで分析し、より健やかな毎日を送れるようにできないか真剣に思案しています。どなたか先行研究や要素技術をお持ちでしたら是非お声がけください。
昨年2020年全24回のModeler推しノードリレーが完結し、いよいよ2021年の新企画が始まりました!!タイトルの地味さが個人的に残念ですが、毎回、次のTipsの内容を「Modeler詰将棋」と称して出題します。初心者からベテランまで、それぞれに気付きがあるはずです。某・アスカの名言のように「ストリームは常に無駄なく美しく」仕上げてみてください!
記念すべき第1回目に取り上げるデータ加工Tipsは「キャッシュ」です。
キャッシュ機能は分析ストリームの特定のノードにデータをキャッシュ(=ストレージの一時ディレクトリに格納)することで、毎回入力データを読み込まず、キャッシュを起点に処理し時短につながります。
ご存知の方のためにも少し注意事項にも触れながら説明します。
キャッシュを試してみましょう
キャッシュの具体的な手順を示します。
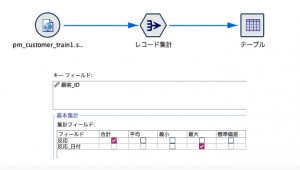
Modelerをインストールすると自動で「Demos」に保存されるサンプルデータの「pm_customer_train1.sav」をStatistics入力ノードから読み込み、図のように集計してみます。(例ですので実際には、どのようなデータで、どういった加工でも結構です。)
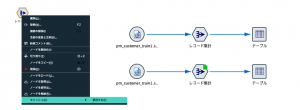
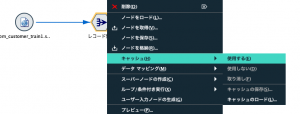
次に集計ノードを右クリックしてメニューの中から「キャッシュ>使用する」を選択します。
すると、集計ノードの右上に白いファイルのアイコンが付与されます。この時点ではまだキャッシュされていません。
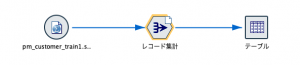
では、かかる処理速度を意識しながらテーブルを実行します。
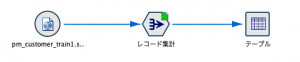
テーブル表示が終わると先ほどのキャッシュファイルのアイコンが緑色に変化しています。これで、レコード集計処理済みデータがキャッシュされていると分かります。
ここでテーブルをもう一度実行してみてください。先ほどの半分の時間で表示します。元データから処理を開始せずに、集計済みのキャッシュを表示させるため、処理速度が向上します。メニューの「ツール>ストリームのプロパティ>メッセージ」で処理時間を確認、比較してみてください。
このサンプルデータは約2万レコードですので、そもそもキャッシュ無しでも1秒程度。しかし元データが大きくなるほど劇的に効率が上がり、その差は数十倍になるはずです。
DBキャッシュとは
Statistics形式(.sav)や CSV形式のようなフラットファイルではなく、Db2のようなデータベース接続でこれを行うと、さらに別次元のメリットが生まれます。
データベース入力ノードを利用している時点でキャッシュを実行するとアイコンが以下のようになります。

これはファイルでキャッシュしているのではなくデータベース領域に、一時的なテーブルをクリエイトしていることを意味しています。これにより、このノードを起点にして、処理をするのはファイルキャッシュ同様ですが、後続ストリームでSQL自動生成(SQLプッシュバック)の恩恵を受けることが可能になるのです。複数のテーブルの結合や集計などある程度重めの処理が済んでからDBキャッシュできると効果的です。
後続のSQLプッシュバックの効き方やDBサイズによって、キャッシュせずに、中間テーブルをDBエクスポートノードで作成する方が効率が良い場合もあるのでITご担当者と相談してみてください。
キャッシュの上手な利用と注意
ダメなキャッシュの例を示します。このストリームの何がダメなのかお分かりになりますでしょうか?
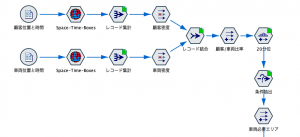
キャッシュを複数オンしてあちこちグリーンが点灯していますね。試行錯誤でストリームを夢中で作り続けた結果の「あるある」です。しかし、このキャッシュで意味があるのは後方2番目の条件抽出ノード(Select)のみ。前方の4つは、もはやリソースの無駄遣い。場合によってリソースが圧迫をして効率を下げるリスクもあります。したがってストリーム作成の最後尾の加工ノード以外は右クリックでメニューから「キャッシュ>使用しない」を選択しリリースしましょう。「キャシングのご利用は計画的に」とテレビでも注意喚起しているとおり(キャッシュのスペルが違いますね・・・)みだりに使うのは問題ですね。
実はキャッシュを利用する理想的な局面があります。例えばレコードが抽出・集約される際や多重ソート・結合などの負荷のかかる処理をした時点です。そして、覚えておきたい重要なルールがあります。ストリームが完成したらキャッシュは、(意図的な利用をのぞいて)全て解除しておいてください。SPSS CADSなどでストリームをバッチ処理する際にはキャッシュによってロスが生じるからです。
キャッシュでランダム処理をセッション中に固定
「意図的な利用って何?」ってなりますよね。実はキャッシュはストリーム作成の時間短縮以外で利用することがあります。ランダムな処理をさせながら、特定の処理の最中にレコードを固定する場合がそれです。
異常検知モデルを作る例で説明します。設備の異常は一般に稀にしか観測されないため、正常と異常の比率は偏っています。例えば99%のレコードが正常で1%しか異常が観測されないアンバランスのまま機械学習モデルを作ってみます。するとモデルは意味のある学習を放棄して全てのレコードを正常と予測。見せかけ上の精度99%を確保しようとしてしまいます。
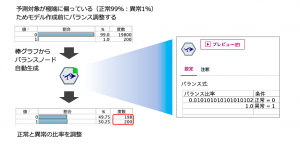
これを回避するためにモデル作成時点だけ、バランスノードで正常と異常の比率を整えます。その際にバランスノードはランダムシードがないため毎回対象レコードを変化させてしまいます。そこでキャッシュで再現性を確保します。ランダム関数を用いて交差検証をするときも同様です。つまり、あるセッションやループ処理の間だけ対象レコードを固定するのにキャッシュを使う場合には、完成版であってもキャッシュは必要になります。
それから、キャッシュファイルはストリームをクローズするとリセットされます。継続的に利用する場合にはキャッシュファイルを保存(「キャッシュ>キャッシュの保存」)するか、エクスポートノードを用いて利用しやすいフォーマットでエクスポートしてください。
Modeler詰将棋!次回のTips から出題
次の2つの例題にチャレンジしてみてください。なんの賞品も用意していませんが正解すると名誉と自信がもれなくついてきます!
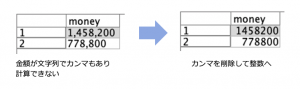
例題1:金額の桁を表すカンマを削除し整数化
カンマやハイフン、特定記号やスペースを削除する文字列加工の例です。加工に利用するノードは1つです(詰将棋風に言うと一手詰めです!)
例題2:ログメッセージ内の[角括弧]文字列の抽出
ログメッセージ内に[角括弧]をみつけたら、その中の語句だけを抽出して新しいフィールド「文字列」を作ります。角括弧は1度きりの登場が前提で、どの位置で出現するかは未定です。加工に必要なノード数は3で解説されますが、一手詰めも可能です。

例題のデータのセット方法①(手入力)
エクセルなどで手入力準備よりも、ユーザー入力ノードが便利です。
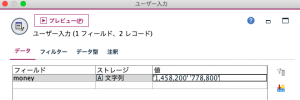
例題1のユーザー入力ノード設定
フィールドに「money」、ストレージを「文字列」。値に「1,458,200」「778,800」を入れてください。値を入力する際は図のように金額をシングルクォーテーションで囲みます。
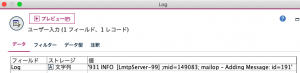
例題2のユーザー入力ノード設定
例題2ではフィールドに「Log」、ストレージを「文字列」、値には「931 INFO [LmtpServer-99] ;mid=149083; mailop – Adding Message: id=191」を入力してください。例題1と同様にシングルクォーテーションで囲みます。
例題のデータのセット方法②(pythonスクリプト)
メニュー>ツール>ストリームのプロパティ>実行で以下のスクリプトをコピー&ペーストし再生ボタンを実行すると二つの例題のユーザー入力ノードが自動生成されます。
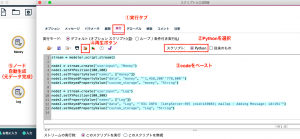
Pythonによるデータ入力ノード生成
難しそうですね。私の同僚のSPSS Modeler 名棋士は例題1に2分、例題2は10分要したとのこと。
次回Tips# 02で解答例を説明いただくのはヤマトホールディングスの杉野様です。
どんな内容か私も楽しみです!

斉藤 明日香
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス
More SPSS Modeler ヒモトク stories

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む
