SPSS Modeler ヒモトク
身近な疑問をヒモトク#12-ちょっと待って!その説明統計的に有意なの?
2022年12月21日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
こんにちは、日本IBM Data & AIの牧野です。
突然ですが、みなさま10月18日は何の日かご存じですか?
答え、10月18日は「統計の日」です。昭和48年(1973年)に定められたとのことです。実際には統計の歴史は古く、古代ローマ時代から納税や人口調査に利用されていました。それが、現代の国勢調査につながっていると考えると統計の世界はどこまで続くのでしょう。また、統計といえば選挙の当選予測、テレビの視聴率、天気予報、占い、商品マーケティング、感染症者数の予測などなどいろいろな場面で利用されています。
みなさんの周辺でも「統計が示している」と説得にかかる方いらっしゃいますよね。しかし「その統計は適切に扱われているのか?」と疑問を持たれることもあると思います。この記事ではそんな疑問に応えるため「あるべき統計の手順」について解説いたします。

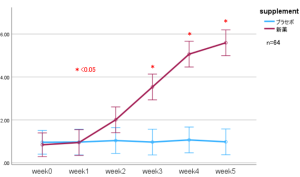
ところで、こんなグラフを電車や雑誌の広告で見かけたことないでしょうか?これは、サプリメントの効果を説明するために、サプリメントを服用したグループ(赤)と服用しなかったグループ(青)で1週間ごとに数値に違いがあるかを比較するために表したエラーバーグラフです。折れ線が1週間ごとの被験者の測定値の平均値で、上下に伸びているバーが平均値の95%信頼区間です。平均値の95%信頼区間とは、たとえば検査を100回繰り返し実施したらそのうちの95回の検査の平均値が含まれる範囲です。3週目以降は、2群のエラーバー(95%信頼区間)に重なり合いがないことから、サプリメントを服用したグループと服用しなかったグループでは、有意な差があると判断できます。このようなグラフは、新薬や特定保健用食品、サプリメントなどの効果を示す際に、論文やジャーナルまた、広告などで使用されています。
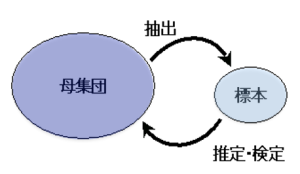
統計学の考え方は、母集団と標本の関係が基本にあります。母集団は分析結果を反映する全体で、標本は調査する対象で全体の一部になります。部分から全体を知るということですね。とても合理的な反面、調査対象の一部が全体を反映していないととんでもないことになります。標本は母集団から偏りなくランダムに抽出されていることが大前提になります。
たとえば、ある飲料メーカーではサプリメントを開発中でターゲットは30代の女性です。その場合、マーケティング部門としては、商品をヒットさせるためにターゲットの嗜好や悩みを調査します。通常は、予算も時間も限られていることから調査できるのは30代女性の一部です。また、特定の地域に在住や特定の仕事に従事などとなるとそれに該当しない30代女性には好まれないかもしれないので、さまざまな地域のさまざまな職種の人を選びます。選ばれた人たちが標本になります。そして、そこから得られた結果が母集団を反映していると考えます。このことからも、標本の人数が多い方が、母集団との違い(誤差)が少なくなるのでより母集団を反映することが伺えます。
統計学には、記述統計と推測統計があります。記述統計とはデータの粗集計で、平均値や中央値、最頻値などのデータの中心と分散や標準偏差、最小値、最大値などのデータのばらつきを表したものです。データの視覚化も記述統計の一つです。記述統計では、データの中心やばらつきの統計量とグラフから標本の様子を把握します。
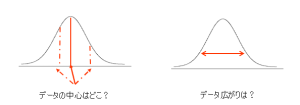
もう一方の推測統計には推定と検定があり、どちらも標本の値から母集団の傾向を調べます。推定は、母集団の平均値や分散がいくつなのかを推測します。検定は、仮説を立て母集団における変数間の統計的な関係(有意)性を評価します。
たとえば、調査した30代女性の標本から睡眠時間や運動時間、1日のスマホの利用時間、収入などの平均と分散、最も多く摂取する食品や飲料水などの情報がわかれば母集団の値が推定できます。推定には、1つの値を推定する点推定と特定の確信度の下で値が含まれる範囲を推定する区間推定があります。信頼性がわかることから統計では区間推定がよく利用されます。エラーバーグラフでは、区間推定を利用しています。
また、睡眠時間と1日のスマホの利用時間との関係や好きな食品と運動時間との関係、職種と好きな飲料水との関係などは検定を利用することで母集団の傾向を評価することができます。
統計の検定にはさまざまなものがありますが代表的な検定には、カイ2乗検定、無相関検定、t検定・分散分析があります。データの尺度の組み合わせによって利用できる検定が異なります。

【検定の進め方】
- 帰無仮説を立てる
帰無仮説:2つの変数間には関係がない (常に帰無仮説は関係がないとするのがルール)
対立仮説:2つの変数間には関係がある - 帰無仮説が正しいとすると標本から得られる値が発生する確率(有意確率)を計算する(ソフトウェアが算出)
- 有意確率と有意水準を比較する
有意確率が有意水準(一般的に0.05)以下の場合、帰無仮説を棄却する
2つの変数間には関係がある つまり、統計的に有意と判断
有意確率が有意水準(一般的に0.05)超過の場合、帰無仮説は棄却できない
2つの変数間には関係があるという証拠が見つからなかった つまり、統計的に有意ではないと判断
このように統計解析では、全数調査ができなくても一部の標本から母集団の傾向を評価します。
最初のサプリメントの広告は、反復測定(Repeated Measurement ANOVA)を用いて分析を行っています。
反復測定は分散分析の1つで、SPSS StatisticsのAdvanced Statisticsのオプションを使用すると分析の実行とエラーバーグラフの作成ができます。
ここでは、広告の効果測定のサンプルデータを使って分析をしてみます。広告宣伝をする前、広告宣伝をして1週間後、2週間後、3週間後、4週間後の売上に有意な差があるかを評価しました。
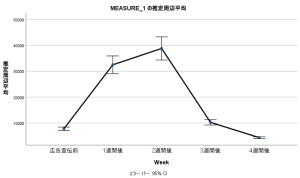
グラフから広告宣伝後、2週間後まで売上の上昇がみられますが、3週間後には広告宣伝前とほぼ変わりがなく、4週間後にはさらに下がってしまっています。広告宣伝前と1週間後、2週間後、3週間後、4週間後の売上の違いが統計的に有意かどうかを評価したものが次の表です。
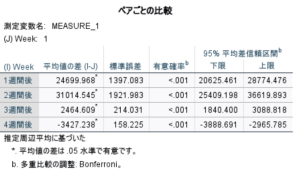
ペアごとの比較(編集済み)では、広告宣伝前と1週間から4週間後のそれぞれと売上の平均値に有意な差があることが有意確率からわかります。特に、1,2週間後までは広告は統計的にも効果があったと言えます。4週間後は、広告宣伝前の売上の平均値との差がマイナスになっているため、今後はその前に何か施策を打つことを検討した方がよいかもしれません。
SPSS Statisticsは、さまざまな統計解析の手法が実行できる統計解析ツールのスタンダートです。SPSS Modelerからも連携して利用するこができますので、SPSS Statisticsの検定やコレスポンデンス分析など分析の幅を広げて活用することができます。

いかがでしたか?
この記事をきっかけにビジネス上の意思決定を促す説明に説得力を持たせるためにも統計的な裏付けを使う重要性に今一度目を向けていただければ幸いです。
「身近な疑問をヒモトク」は今回が最終回です。様々な身近な疑問をきっかけにデータ活用の可能性について考えて頂けていれば嬉しいです。来年も新たなブログ連載を準備しておりますのでご期待ください。
→これまでのSPSS Modeler ブログ連載のバックナンバーはこちらから

牧野 泰江
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む