

























SPSS Modeler ヒモトク
身近な疑問をヒモトク#06-答えはお客様の中にある!アンケートの自由回答からニーズを顕在化させる
2022年06月20日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:

こんにちは。マーケティングバリューアップの千野といいます。
みなさんは日頃、アンケートに協力することはあるでしょうか。
かつては紙一択だったアンケート。最近はスマホやタブレットの調査が低コストで「顧客の声」を収集できるとあって、すっかりオンラインがお馴染みになりましたよね。
しかし耳を傾けてくれるのは良いのですが、回答する立場としては「結構な時間をかけて、根掘り葉掘り聞かれた自分の意見はちゃんと反映されるのか?」と思いますよね。
実際に多くのアンケートは、簡単な集計にとどまる場合がほとんど。特に自由回答は手づかずの場合も多いのです。
なぜ自由回答は活かされないのでしょうか?
アンケートの多くは選択肢を選ばせる単一回答(SA)か複数回答(MA)。それはアンケート作成者が用意した想定範囲を超えられないデメリットがあります。重要なニーズや阻害要因を見落とすリスクも。
一方で自由回答(FA)はなんでも意見できる代わりに、集計が極端に面倒で結果を定量的に商品開発や意思決定に繋げるのは難しいと考えられています。
どうすればアンケートの自由回答から回答者のニーズを顕在化させられるでしょう。私のおすすめの方法は「自然言語処理してからの共分散構造分析」です。
本論の前に自己紹介を簡単にしておきます。
私はマーケティングコンサルタントとして25年以上活動をしています。
サービス内容としては新商品・サービス企画支援やマーケティング支援・講演セミナーです。その中でも特にマーケティングデータを分析し、戦略立案や施策をサポートすることを主業務にしおり、ツールは様々利用しますが、SPSS ModelerとSPSS Statisticsは20年以上使っています。
<共分散構造分析について>
まず共分散構造分析ツールのAmos(Analysis of Moment Structures)について説明しますね。
共分散構造分析を用いると項目間の関係性の把握が可能になります。
その関係性の把握を大きく分けると3つあります。
1.項目間の関係性の把握する(パス解析モデル)
回帰分析も行えますが、下記のように複数項目の関係を把握することも可能です。
下記の例ですと認知から購入への直接的効果(0.16)と間接効果(0.80×0.63=0.504)の違いや総合効果(0.16+0.504=0.664)の確認ができます。

2.因子分析と回帰分析の組合せで関係性を把握する
因子項目に影響を与えている項目は何かというような形で複雑な影響関係を把握するモデルを作ることができます。
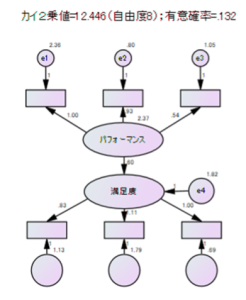
3.性別や年代別の属性間の違いを把握する
全データを対象にして作成したモデルが、性別や年代など自分が比較したいグループ単位でも分析が行えるため、グループ別に影響の違いや因子分析で作成された潜在変数の比較などが行えます。
<共分散構造分析を使用した背景>
市場に商品・サービスを投入(上市)する場合、STP分析(市場をセグメントし、自社のターゲットとなる顧客層を決定し、市場の中でどのようなポジショニングをとるか)が行われます。
分析の最初に行うセグメントですが、日本では様々な商品があるため、どのようなセグメントに設定すると自社商品・サービスの優位性が保てるかというのを考えることは非常に難しくなっています。
例えば、市場を性別・年代別のようなプロファイルでセグメントを行うと、「親子お揃いコーデ」が好きな顧客層については、発見しにくいというような場合がそれにあたると思います。
では「親子お揃いコーデ」を発見するのはどのようなセグメントが必要でしょうか?
まず「親子お揃いコーデ」がしたい理由を考えた場合、「家族の一体感が欲しい」のようなニーズが背景にあると思います。
であるならば、市場をニーズでセグメントを行うと、ニーズを解決する商品・サービスを考えることができるはずです。
ということで顧客のニーズにフォーカスをして下図のように整理してみました。

ニーズは価値観と現状の“ギャップ(顧客の課題)”です。
そのニーズ(課題)を満たすために必要なものは“ベネフィット(役立ち=解決手段)”となります。ということは価値観でセグメントをし、上記のような関係性が把握できればどのような商品・サービスを市場に投入すればよいか理解できるはずです。
この関係性を把握する方法としてAmos(共分散構造分析)を採用しました。
(この分析方法は、2004年から行っているので、IBMさんにはお世話になっております。)
<価値観でセグメントする方法>
まず初めに、アンケートを実施します。
回答者の価値観・ニーズ・ベネフィットなどに関する回答は選択肢であると本当の意見が聞きにくいため、自由記述にしています。
以降は下記手順を踏み、最終的にAmosで価値観と関係があるニーズ-(ベネフィット・阻害要因)を把握します。
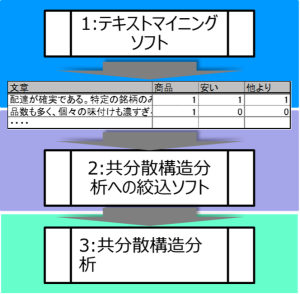
注:図の説明内容
- テキストマイニングを使用して自由回答をキーワード化
- 共分散構造分析(Amos)で分析が可能となるようキーワードのクレンジング
- 共分散構造分析で関係性の分析(パス解析モデル)
<SPSS Modelerでテキストマイニングする方法>
自然言語処理をする方法は様々ですがSPSS Modelerを利用するにはふたつの方法があります。この記事では自然言語処理後の手続きにフォーカスします。
①拡張ノードでPython連携する (→この方法を解説する記事はこちら)
②有償のテキスト処理テンプレートを利用する (→SA社の製品説明はこちら)
<実際の使用例>
それでは、分析結果について簡単に説明します。
テーマは食品をネットで購入する理由について調べてみました。
(注:自費調査のため、阻害要因の質問は省いた内容になっております。)
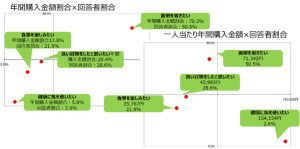
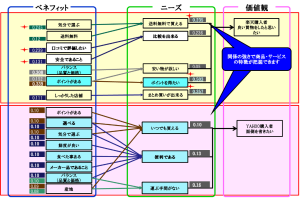
分析の結果、価値観は、以下の4つに分類されました。
価値観-ニーズ(要望)-ベネフィット(役立ち)の関係をAmosで分析すると以下のようになります。
参考例:面倒を省きたい
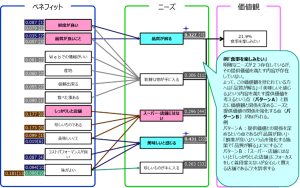
この分析結果では2つの特徴が見えます。
1.「価値観とニーズ」、「ニーズとベネフィット」の関係性(数値)からニーズの重要度やベネフィットの重要度が把握できる。これは、ある価値観を持っている方に商品・サービスのベネフィット(役立ち)をどのように伝えるべきかを数値化しているため、理解しやすいと思います。
2.ニーズによってベネフィットの重要度が違います。
このことはベネフィットの伝える匙加減をニーズによって変えるとお客様は理解しやすいということが分かります。
また主な購入先を設問として設けているので、サイト別に重要度の違いも把握できます。
<まとめ>
テキストマイニングとAmosを用いて価値観別顧客セグメントを作成しました。
この分析結果を活用すると、どのような差別化戦術が必要であるかディスカッションがしやすくなるため、自社の強みを活かしたSTP分析が行いやすくなるはずです。自由回答欄に眠る貴重な宝をすぐに覚醒させるべくトライしていただけると幸いです。
またAmosは、BSCの戦略マップの検証にも活用するなど、様々なビジネスシーンで使えると思います。ご興味を持てましたら、まずはAmosを使ってみることをお勧めします。
なおこちらの価値観別顧客セグメントは学習院大学上田先生と横浜市立大学国際商学部柴田先生の論文「製品利用におけるオケージョンと価値体系:ラダリング法とテキスト・マイニングの活用–ビール・発泡酒を事例として(マーケティングジャーナル 22 (3), 18-32, 2003)」を参考に行っております。
上田先生と柴田先生には、この場をお借りして御礼申し上げます。
次回の身近な疑問をヒモトクはIBMの角田さんが「ニュースでよく見るイケてる地図グラフを自分でもサクッと描いてみたい」を執筆。また並行連載中の「ブログで学ぶSPSS Modeler」はIBMの西牧さんが「モデル比較には欠かせない重要度分析のカラクリと存在意義」書いてくださいます。お楽しみに。
→これまでのSPSS Modeler ブログ連載のバックナンバーはこちらから

千野 直志
マーケティングバリューアップ
代表
<略歴>
SI会社に10年在籍し、マーケティング情報システムのシステムインテグレーションを行う。退職後、コンサルティング会社で取締役を経て、2009年にマーケティングバリューアップを設立する。25年以上のマーケティングコンサルタント経験とデータサイエンティストのスキルを駆使し、これまで数十社へのコンサルティング活動と企業研修を実施している。

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む