

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
ブログで学ぶSPSS_Modeler #13- 原点回帰CRISP-DMから始まるデータ分析
2022年12月26日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
いよいよ2022年のヒモトクブログも最終回となりました。
今回は長年SPSSプロダクトに携わってきた日本IBM Data & AIの牧野が担当させていただきます。
唐突ですが最終回にデータマイニング(データ分析)の原点に立ち返ってみようと思います。「えっ、なんで!?」と思われた方もいらっしゃるかもしれませんね。単純なのですが、新しいことを追いかけているとついつい基本的なことをなおざりにしてしまうので初心に返って、データマイニングのプロセスを今一度読者のみなさまと共有させていただこうと考えた次第です。
また、昨今企業のDX推進の追風に乗ってデータサイエンティスト人材の育成が課題となっています。これからデータサイエンティストを目指す方やデータサイエンティストを育成する方にとって、データマイニングのプロセスの型は重要だと思われるので、そのような方々の参考にしていただけるのではないかとも考えました。
では、さっそくご紹介していきましょう。
SPSS Modeler(リリース当初の製品名は、Clementine)には、イニシャルウィンドウ右下のプロジェクトウィンドウに[CRISP-DM]タブがあります。これは分析のフェーズごとに、作成したファイル情報を管理する目的で用意されています。SPSS Modelerで作成したファイルだけでなく、Word、Excel、PowerPointなどのファイルもドラッグアンドドロップするだけでファイルのパス情報が記録され管理することができます。
では、このCRISP-DMとはそもそも何なのでしょうか。
CRISP-DMは、1996年の後半にDaimlerChrysler、SPSS、NCRの3社によって考案されました。このころは、データマイニング市場の歴史はまだまだ浅くて未熟でしたが、DaimlerChrysler は、商工業組織の多くに先駆けて、ビジネスオペレーションへのデータマイニングの適用の分野ですでに実績がありました。SPSSは、1990年からデータマイニングに基づくサービスを提供していて、1994年には初の商用データマイニングワークベンチであるClementine(現SPSS Modeler)を発表しています。NCRは、Teradataデータウェアハウスの顧客に付加価値を提供するための一環として、データマイニングコンサルタントとテクノロジーの専門家からなるチームをすでに設立して、顧客の要求を満たすためにサービスを提供していました。
そこでこの3社がコンソーシアムを組織して、業界、ツール、アプリケーションに対する中立性を保つことを目指してCRoss-Industry Standard Process for Data Mining(CRISP-DM)を開発しました。CRISP-DMは、学術的なものではなく、実務者たちが作成した、実用的で現実的な経験に根ざしたプロセスモデルです。
CRISP-DMは、データマイニングプロジェクトのライフサイクルの概要を示しています。ここでのライフサイクルはモデル運用のMLOpsに至る前と考えてください。そして、そのライフサイクルには6つのフェーズがあります。ビジネスの理解、データの理解、データの準備、モデリング、評価、展開/共有です。各フェーズの矢印は一方向に進むだけに限らず双方向に進む/戻るといった場合もあります。データマイニングのプロセスは、状況によってフェーズ間の行ったり来たりを繰り返しながら進めていくものだからです。また、外側の円の矢印は、データマイニングの循環を表しています。これは、ソリューションへの展開が済んでもデータマイニングは終わりではないからです。多くの場合、データマイニングのプロセス中に明らかになったことや展開したソリューションがきっかけとなって、さらに焦点を絞り込んだ新しいビジネス上の問題が発生してきます。そこで、後続のデータマイニングのプロセスは、前のプロセスの経験を利用することができます。
すでにデータマイニングを実施されている読者の方もCRISP-DMを意識せずともこのようなプロセスで作業を行われているのではないかとお察します。
ただ、CRISP-DMがあることによってこれからデータマイニングを始めよう、始めなければならない、始めてもらうように指導しなければならないという場合に多いにお役立ていただけるものと思っています。なぜなら、CRISP-DMはデータマイニングのプロセスの型になるからです。
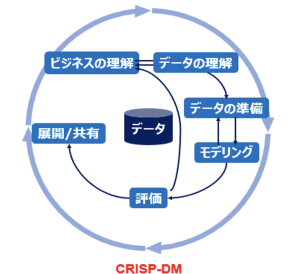
図:CRISP-DM
各フェーズの概要は、CRISP-DMガイドから以下の通りです。
IBM SPSS Modeler CRISP-DM ガイド – IBM Documentation
1.ビジネスの理解
ビジネス上の観点からプロジェクトの目的と要件を理解し、その知識を基にして、データマイニングの問題定義と目的達成のために設計された初期計画を作成することに重点を置きます。
2.データの理解
初期データの収集を実施し、次に、データをよく理解し、データの品質の問題を明らかにし、データに関する最初の洞察を行うかまたは興味深いサブセットを見つけ出して、隠された情報に関する仮説をたてるためのアクティビティを行います。
3.データの準備
初期の生データから最終的なデータセットを(モデリングツールに入力するデータ)を構築するためのすべてのアクティビティを行います。データの準備タスクは、多くの場合、決まっていない順序で何度も実行されます。このタスクには、テーブル、レコード、属性の選択、さらにモデリングツール用のデータ変換とクリーニングが含まれます。
4.モデリング
さまざまなモデリング手法を選択して適用し、そこで使うパラメータを調整して最適な値に設定します。通常は、同じデータマイニングの問題タイプに対して、複数の手法を使用することができます。一部の手法では、特定の形式のデータが必要になります。そのため、しばしばデータの準備フェーズに戻る必要が生じます。
5.評価
データマイニングの観点から見て品質が高いと思われるモデルを、1つ以上はすでに作成しているはずです。モデルの展開の最後に進む前に、さらに徹底的にモデルを評価し、モデルを構築するために実行された手順をレビューし、ビジネス目標が正しく達成されていることを確認することが重要です。重要なビジネス上の問題で十分に考慮されていないものがないかを調べることが主な目的です。このフェーズの最後には、データマイニングの結果の使い方を決定してください。
6.展開/共有
通常は、モデルを作成してもプロジェクトは終了しません。モデルの目的がデータに関する知識を増やすことだとしても、取得した知識をユーザーが使用できるように整理して提示する必要があります。多くの場合、このタスク内で、組織の意思決定プロセス内にある「生きた」モデルの適用を行います。たとえば、リアルタイムでWebページをカスタマイズしたり、マーケティングデータベースに繰り返し記録したりする場合などがあります。しかし、要件によっては、導入フェーズは、レポートの生成のように単純になる場合もあれば、繰り返し実行できるデータマイニングプロセスを企業全体にインプリメントするというように複雑になる場合もあります。多くの場合、導入のステップを実施するのは、データアナリストではなく、顧客です。しかし、アナリストが導入作業を行わないとしても、作成されたモデルを実際に活用するには、必要なアクションについて顧客が事前に理解していることが重要です。
次に必ずしもこれがすべてというわけではありませんが、各フェーズの標準タスクとアウトプットを図で表現し、合わせてアウトプットのレポート化について取り上げましたので見てみましょう。データマイニングのレポートは、そのプロジェクトに関わった人や関わらなかった人にも分析内容を説明するために文書化します。
レポートには、分析の透明性、信頼性が盛り込まれ、データマイニングの説明責任を果たす目的があります。AI(機械学習を含む)化が進む中で、ますますレポートの必要性は高まります。
1.ビジネスの理解
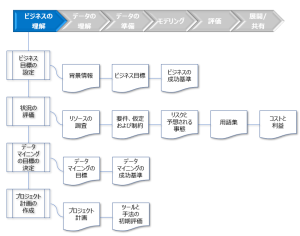
図:[ビジネスの理解]のタスクとアウトプット
レポート
- 背景情報
プロジェクトの状況の概要を説明します。プロジェクトの対象領域、既に存在が認識されている問題点、さらに、データマイニングにより解決できると思われる理由をリストして記述します。 - ビジネス目標と成功基準
ビジネス目標は、プロジェクトの目標をビジネス用語で記述したものです。各目標についてビジネスの成功基準を設定する必要があります。ビジネスの成功基準とは、その目標に関してプロジェクトが成功したかどうかを判断するための明確な測定基準のことです。 - リソースの調査
リソース調査の目的は、プロジェクトの実施に利用できる人員、データソース、技術的設備などのリソースを確認することです。 - 要件、仮定および制約
プロジェクトの実施方法に関する一般的な要件、問題の特性と使用データに関して設定された仮定、プロジェクトに課せられた制約のリストを記述します。 - リスクと予想される事態
プロジェクト中に発生する可能性がある問題を識別し、その問題を放置した場合の結果を記述し、その影響を最小限に抑えるために実施できるアクションを記述します。 - 用語集
用語集があると、プロジェクトが取り組んでいる問題について十分な知識がない人々がそれらを理解できるようになります。 - コストと利益
プロジェクトのコストとプロジェクトが成功した場合に期待されるビジネス上の利益について記述します。 - データマイニングの目標と成功基準
データマイニングの目標では、ビジネス目標の達成を可能にするプロジェクトの結果を記述します。さらに、有望なデータマイニングアプローチと、プロジェクトの結果を判定する成功基準のリストをデータマイニング用語で記述する必要があります。 - プロジェクト計画
プロジェクトで実施される段階のリストを作成します。期間、必要なリソース、インプット、アウトプット、および依存関係も記述します。 - ツールと手法の初期評価
使用される可能性が高いツールと手法、およびその使い方に関する初期見解を示します。ツールと手法に関する要件を記述し、利用可能なツールと手法のリストを作成して、それらを要件と照らし合わせます。
2.データの理解
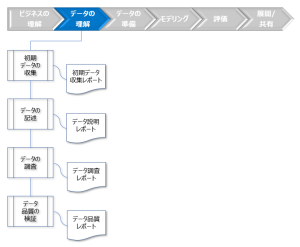
図:[データの理解]のタスクとアウトプット
レポート
- 初期データ収集レポート
リソース調査で確認されたさまざまなデータソースを習得、および抽出する方法について記述します。- データ背景情報
- 必要なデータを広範囲に渡ってカバーするデータソースのリスト
- 各データソースを取得、および抽出する方法
- データの取得時、または抽出時に発生した問題
- データ説明レポート
取得した各データセットの説明を記述します。- 各データソースの詳細説明
- テーブルなどのデータベースオブジェクトのリスト
- 単位や使用するコードなどを含む各フィールドの説明
- データ調査レポート
データの調査とその結果を記述します。- 予測される規則性やパターン
- 検出方法
- 検出、予測された規則性、またはパターン、および予測されていなかった規則性、またはパターン
- そのほかの予測外の事柄
- データの変換やクリーニング、そのほかの事前処理に役立つ結論
- データマイニングの目標、またはビジネス目標に関する結論
- 結論の要約
- データの品質レポート
データの完全性と精度について記述します。- データ品質評価に使用したアプローチ
- データ品質評価の結果
- データ品質評価の結論の要約
3.データの準備
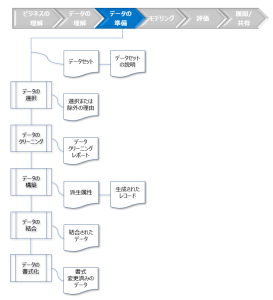
図:[データの準備]のタスクとアウトプット
レポート
- データセット説明レポート
事前処理後のデータセットの概要とデータセットの生成プロセスについて記述します。- 事前処理の大まかな目標と計画を含む背景情報
- データセットの選択、または除外の基準
選択した各データセットについて
- 事前処理の説明
- 生成されたデータセットのテーブルごと、およびフィールドごとの詳細な説明
- 属性の選択、または除外の基準
- 事前処理で発見された事柄と今後の作業への影響
- 要約と結論
4.モデリング
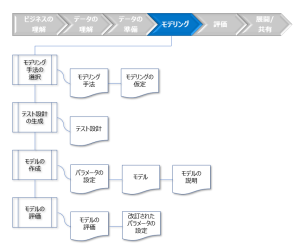
図:[モデリング]のタスクとアウトプット
レポート
- モデリングの仮定
データに関する仮定と使用するモデリング手法に暗黙的に含まれる仮定を定義します。 - テスト設計
モデルの作成、テスト、および評価の方法を記述します。- 使用するモデルと学習データのタイプに関する大まかな説明
- モデルのテスト方法、または評価方法の説明
- テストに必要なすべてのデータの説明
- テストデータの生成計画
- ドメイン、またはデータの専門家によって計画されているモデルの検査の説明
- テスト計画の要約
- モデルの説明
作成されたモデルとそのモデルを作成したプロセスの概要について記述します。- 作成されたモデルの概要
- モデルのタイプと、データマイニングの目標とモデルの関係
- モデルを作成するために使用したパラメータの設定
- モデルの性質に関する詳細説明
- データ内のパターンに関する結論
- 結論の要約
- 作成されたモデルの概要
- モデルの評価
テスト設計に従ってモデルをテストした結果を記述します。- 評価プロセスと評価結果の概要
- 動作の精度や解釈などの測定結果を含む詳細なモデルの評価
- ドメイン、またはデータの専門家によるモデルに関する意見
- モデルの評価の要約
- モデリング手法やパラメータ設定によって、結果が異なる理由に関する考察
- モデルセット全体の要約
- 評価プロセスと評価結果の概要
5.評価
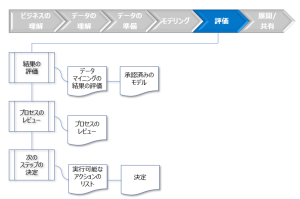
図:[評価]のタスクとアウトプット
レポート
- ビジネスの成功基準に基づくデータマイニングの結果の評価
データマイニングの結果をビジネス目標、およびビジネスの成功基準と比較します。- ビジネス目標とビジネスの成功基準のレビュー
- 成功基準とデータマイニングの結果の詳細な比較
- 成功基準の達成可能度とデータマイニングプロセスの適切さに関する結論
- プロジェクトが当初のビジネス目標を達成したかどうかを確認
- このプロジェクト期間中、または今後のプロジェクトで解決する必要がある新しいビジネス目標の有無の確認
- 今後のデータマイニングプロジェクトに向けての結論
- ビジネス目標とビジネスの成功基準のレビュー
- プロセスのレビュー
プロジェクトの有効性を評価します。また、見過ごされた可能性がある要因を特定して、今後そのプロジェクトを繰り返すときに考慮に入れることができるようにします。 - 実行可能なアクションのリスト
プロジェクトの次のステップに関する推奨事項を記述します。
6. 共有/展開
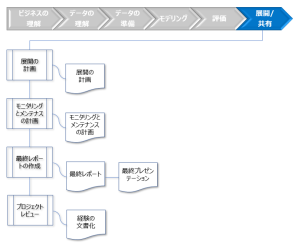
図:[展開/共有]のタスクとアウトプット
レポート
- 展開の計画
データマイニングの結果の展開方法を指定します。- 展開可能な結果の要約
- 展開計画の説明
- モニタリングとメンテナンスの計画
展開された結果のメンテナンス方法を指定します。- 結果の展開の概要、および更新が必要な可能性がある結果、およびその理由の説明
- 定期的な更新、きっかけとなるイベント、パフォーマンスのモニタリングなど更新を開始する方法の説明
- 更新の実行方法の説明
- 結果の更新プロセスの要約
- 結果の展開の概要、および更新が必要な可能性がある結果、およびその理由の説明
- 最終レポート
プロジェクトとその結果を要約するために使用します。- ビジネスの理解の要約
- データマイニングプロセスの要約
- データマイニングの結果の要約
- 結果の評価の要約
- 導入計画とメンテナンス計画の要約
- コストと利益の分析
- 企業のための結論
- 今後のデータマイニングに向けての結論
CRISP-DMは、データマイニングのプロセスの型です。一度この型に従ってプロセスを進めることで、次はその経験を活かしブラッシュアップしたプロセスでデータマニングが実施できることでしょう。
もしかすると、データマイングのプロセスの途中で道に迷うことがあるかもしれません。そんな時は、CRISP-DMを思い出してください。問題に対する示唆が得られるかもしれません。忘れているタスクはないですか?
さあ、CRISP-DMの地図をもって目的地に向かって進んで行きましょう!
来年も新たなブログ連載を準備しておりますのでご期待ください。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

牧野 泰江
日本アイ・ビー・エム株式会社 テクノロジー事業本部
データ・AI・オートメーション事業部 Data & AI 第一テクニカルセールス
More SPSS Modeler ヒモトク stories

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む
