

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
ブログで学ぶSPSS_Modeler #12- 時系列データを扱う「シーケンス関数」をおさらいしよう!後編
2022年12月05日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
この記事は前編から続きです。
ブログで学ぶSPSS_Modeler #12- 時系列データを扱う「シーケンス関数」をおさらいしよう!
前編はこちら→https://www.ibm.com/blogs/solutions/jp-ja/learn-modeler-11/
特殊関数を使ってみる
最後に、特殊関数グループの関数を紹介していきます。

ここでの主役は@OFFSET関数です。この関数を覚えておけば、データ加工の幅が一気に広がります。
① @INDEX
この関数は読み込んだレコードに対し順番にレコード番号を取得してくれます。
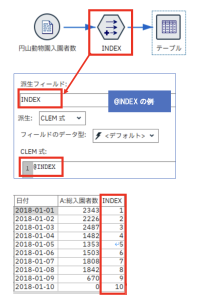
単純にレコード番号を取得してくれますが、例えばキーとなるフィールドがないデータを活用する場合、レコード番号をキーフィールドとして活用するなど、アイデア次第で活用の幅が広がります。
② @SINCE(EXPR) / @SINCE0(EXPR)
この関数は引数 EXPR に 論理式を記述します。前方参照して、論理式が成立するレコードを特定し、現行レコードからのレコード数を返します。@SINCEと@SINCE0の違いは論理式の成立するレコード自身を0レコード目とするか、しないかの差です。
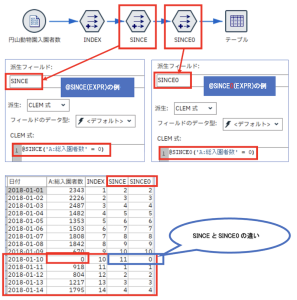
論理式には、<A:総入園者数 = 0>と記述しました。
論理式が成立するレコードからのレコード数を取得しています。 前方を参照して論理式が成立するレコードがない場合はレコード番号+1の値を返します。(INDEXフィールドの値もあわせて参照)
論理式<A:総入園者数 = 0>が成立するのは2018/1/10のレコードが最初です。 2018/1/10が起点となり、2018/1/11は1レコード目というようにカウントしています。簡単に思いつく使い方としては、エラー発生からレコードをカウントするなどでしょうか。この関数も特徴量を作成するために利用できそうです。 SINCE0は該当レコード自身を0レコード目としていますね。
③ @SINCE(EXPR, INT) / @SINCE0(EXPR, INT)
@SINCE/@SINCE0の引数が2つのバージョンです。前方参照するレコード数の最大値を二つ目の引数で指定することができます。論理式が成立するレコードを前方参照して、該当レコードからのレコード数を返しますが参照するレコード数に上限があるため、指定されたレコード内で該当レコードが存在しない場合は、レコード番号+1が返されます。
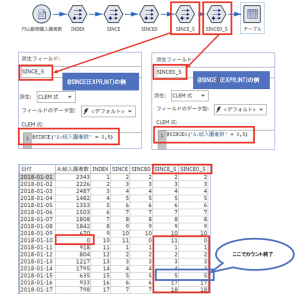
例を見てもらうと、上限値を5と指定したので、5つ前のレコードまでしか参照していませんね。そのため2018/1/16のレコードはレコード番号+1が付与された状態となっています。引数が1つの場合の@SINCEとは値が異なっていることが分かりますね。
④ @THIS(FIELD)
この関数は@SINCE/@SINCE0と組み合わせて使うことが推奨されています。引数<FIELD>で指定された同一レコードのフィールドの値を返してくれます。普通に使用した場合は指定したフィールドの値を返すだけです。
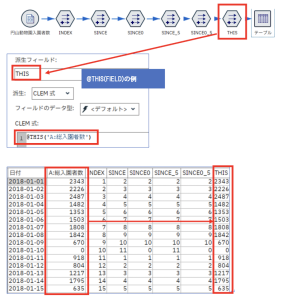
日本IBM西牧さんのQiitaの記事<ID毎に同じ事象が起きてからの経過日数を求める(SPSS Modeler データ加工逆引き4-11)>に@SINCE関数と組み合わせた使い方がまとめられています。ものすごく分かりやすく、すばらしい記事ですので活用例については該当記事を参考にしてください。
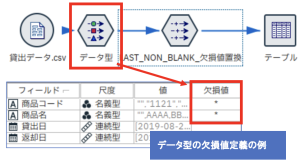
⑤ @LAST_NON_BLANK(FIELD)
この関数は前方参照して引数で指定したフィールドの最後の空白(欠損値)でない値を返します。それまでに読み込んだレコードの値がすべて空白(欠損値)である場合は、$null$ を返します。 主に欠損値の補完に使用することが想定されます。
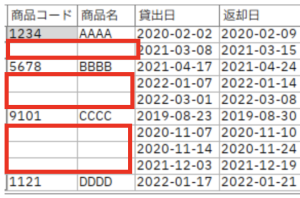
上記のような商品の貸し出し記録データを使ってみます。商品コードと商品名の欠損値を埋めてみましょう。最初に欠損値をきちんとデータ型で定義しましょう。
つづいて欠損値を置換します。
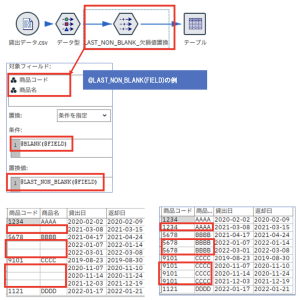
上記のデータは商品の貸し出し記録です。同じ商品の場合には商品コードと商品名が空白になっています。そのため空白の場合は、前方参照して、欠損値でない最後の値に置換するように置換ノードで処理を記述しています。
西牧さんの<欠損値/空白に直近の値を置換する(SPSS Modeler データ加工逆引き5-1)>も参考にしてみてください。
⑥ @OFFSET(FIELD, EXPR) / @OFFSET(FIELD, EXPR, INT)
さて、最後に真打となる@OFFSET関数の登場です。この@OFFSET関数は第1引数で指定したFIELDの値を第2引数で指定したレコード分、前方参照を行います。いままで紹介してきた関数を@OFFSETで代用できるものもあります。第3引数があるものは、@SUM関数などと一緒で参照するレコード数を制御する際に利用します。
※.ちなみに、第2引数には、マイナス(-)の値も指定できます。@OFFSER(AAA,-2)などのようにマイナスの値を指定すると後方レコードを参照できます。 では、@OFFSET関数の活用例をいくつかご紹介します。
(ア)差分の計算 / @DIFF1(FIELD)との比較
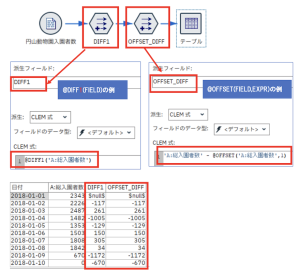
これは、簡単ですね。一つ前のレコードの値を引いています。ちなみに@OFFSET関数ですと、第2引数の値を変更することで2つ前とか、7つ前(1週間前)との差分も計算することができます。さらにマイナス(-)の値を指定して後方参照することもできます。
(イ)移動平均 / @MEAN(FIELD,EXPR)との比較
移動平均を計算する際にもよく活用されます。
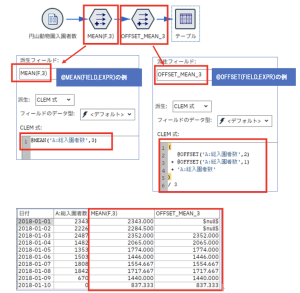
こちらも簡単ですね。2つ前と1つ前、現行レコードの値を足して3で割っています。
@MEANの場合は参照先が存在しない場合でも値を算出してくれていますが、 @OFFSETは計算結果が$null$となっています。
(ウ)欠損値置換
欠損値を置換する際にも大活躍してくれます。@LAST_NON_BLANKの場合と同様に置換ノードで実施してみます。
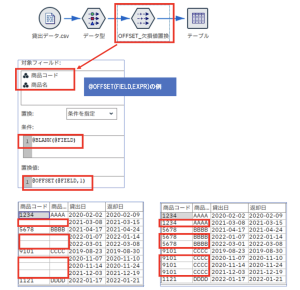
これは、自身が欠損値の場合に直前の値で置換しています。1レコード進んでまた欠損値であった場合も、直前で欠損値でない値に置き換えているので直前で置き換えた値で上書されます。
(エ)順番付与
フィールド作成ノードの活用例もかねて説明します。ここでは、OnlineShopの購入履歴について、購入順と購入間隔のフィールドを新規作成してみます。
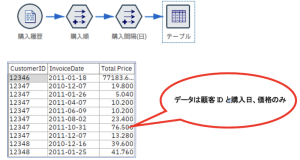
上記のような購入履歴データを使用して、顧客毎の購入順序と購入間隔(日付)を計算します。1回目の購入から2回目の購入までの日数やどんな買い回りをしているのかが分かるようになりますね。
※.データについて UC Irvine Machine Learning RepositoryのOnlineRetailを加工して使っています。
<https://archive.ics.uci.edu/ml/datasets/Online+Retail>
・購入順の作成
顧客毎購入履歴に初回購入からの順番を付与します。

- フィールド作成ノードで派生は「カウント型」にセット
- 初期値に「1」をセット ※.初回購入は1
- 増分条件に: 「CustomerIDが一つ前のレコードと同じ」という条件をセット
- 増分は「1」をセット ※購入順は1ずつカウントアップ
- リセット条件に「CustomerIDが一つ前のレコードと異なる」という条件をセット
同じCustomerIDが続く場合にカウントアップされ、CustomerIDが切り替わった場合に初期値1にリセットされます。
・購入間隔(日)の作成
前回購入日からの日数を計算します。

- フィールド作成ノードで派生は「条件付き」をセット
- 条件に「CustomerIDが一つ前のレコードと同じ」という条件をセット
- 購入間隔は、date_days_difference関数を使って一つ前のレコードのInvoiceDateの差分を計算させます。
- CustomerIDが一つ前のレコードと異なる場合は初回購入と判断して欠損値をセット
これで、購入間隔(日)が計算できます。
結果は下記の通り。CustomerIDが切り替わると購入順、購入間隔ともにリセットされていることが分かります。あとはCustomerID毎にレコード集計ノードなどで集計すれば、平均購入間隔(日)などもわかるようになりますね。
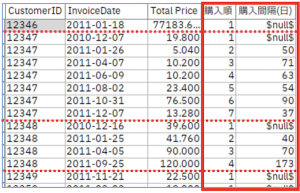
いかがでしたでしょうか。作成したフィールド値をうまく活用するには、レコード集計ノードや再構成ノードなどとも組み合わせて利用してみてください。
Modelerデータ加工編の記事で様々なTIPSが紹介されていますので参考にしてください。
SQLプッシュバックについて
最後にシーケンス関数を利用する際のSQLプッシュバックについて補足します。(SQLプッシュバックについては詳しい説明が本連載の第2回の記事にありますので、ぜひ参考にしてください。)
@OFFSET関数をはじめ本記事で紹介した関数はSQLプッシュバックが機能しません。@OFFSET関数のように前後のレコード値を利用し、かつSQLプッシュバックを機能させるストリームを作成るにはどうするのでしょうか?
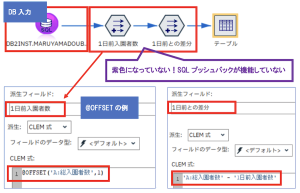
上記の例では1日前のレコードから値を取得するために@OFFSET関数を利用していますが、そのノード以降でSQLプッシュバックが機能しません。(ノードが紫色になっていません)
2020年の秋のユーザーイベントでSQLプッシュバックの実装をリクエストするために機能追加を依頼する投票なども実施しましたが、まだ実現はされておりません。
さて、SQLプッシュバックを機能させながらレコードを前方参照するにはどうするのか?
・クエリをDB入力ノードに記述する方法
DB入力ノードにクエリを記述して、1日前の入園者数を取得してから、前日との差分を計算する方法をまずはご紹介します。(データベースについてはDb2 v11.1を利用しています。)
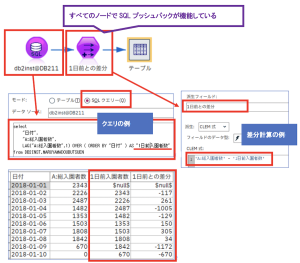
DB入力ノードにLAG関数を使用したクエリを記述しています。

※. SQL Server / Oracle 等のクエリについては、必ず各ソフトウェアのリファレンスを参照してからご利用ください。 例は一番シンプルなクエリで記述しました。
- DBからデータを取得する際に、クエリで前方のレコード値も取得(1日前入園者数というフィールドに格納)
- 1日前入園者数を当日の入園者数から引いて差分を計算
このようにするとSQLプッシュバックを機能させながら@OFFSETのように前日の入園者数を取得する処理を実現できます。SQLプッシュバックが機能することによりストリームのパフォーマンス向上も期待できますね。
※. LEAD関数もあり、LAG関数は前方を参照し。LEAD関数は後方を参照します。
・クエリを記述せずに実現する方法
既存のノードを組み合わせて@OFFSETの機能と同等の内容を、SQLプッシュバックを機能させながら実現する方法は、日本IBM河田さんのQiitaの記事<@OFFSETをSQLプッシュバックさせる(Db2版)>に詳しい内容がまとめられておりますのでぜひ参考にしてください。
確認したところ、@INDEX、@MEAN、@DIFF1、@SDEV、@SUM、@OFFSETはDb2で同じ要領で同等の処理をプッシュバックできました。
工夫次第で同様の結果を得ることも可能ですので日々精進しましょう!
まとめ
時系列データを扱う際に役に立つシーケンス関数をご紹介しました。
いかかでしたでしょうか。
「SPSS Modeler春のオンラインユーザーイベント2022」に参加された方の中には、センサーデータや時系列データを扱ってデータ分析に活用してみようと考えた方もいらっしゃると思います。ちょうどお客様からの問い合わせも増えてきていたので、今回ご紹介させていただきました。前後のデータの関係性を理解しながら、うまく関数を利用してデータ分析に活用してください。
「ブログで学ぶSPSS Modeler」リレー連載は次回が最終回です。アンカーIBM牧野さんによる「原点回帰CRISP-DMから始まるデータ分析」。お楽しみに!!
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

林 啓一郎
株式会社AIT 開発事業本部
ソリューション戦略第2部 次長
More SPSS Modeler ヒモトク stories

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む