

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
ブログで学ぶSPSS_Modeler #10- 異常検知の自動化!CADSの設定を動画でご紹介
2022年10月05日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
こんにちは!IBM斉藤です。今回はSPSS Modelerで作成したストリームをCollaboration and Deployment Services (以下CADS)で実行するための設定を動画にてご紹介します。
利用環境:
- SPSS Modeler v18.4 Mac版
- Collaboration and Deployment Services v8.4 ( Windows Serverに構築

図1 接続イメージ
はじめに 想定シナリオのご説明
今回の異常検知では、時系列データを用いて、過去のデータから異常値の有無を判定します。例えば24時間稼働の工場で、製造数の計画に基づきMT_002ラインで1時間あたりに消費された電力が正常の範囲内であったか確認します。(95%予測区間。範囲の設定方法は、本記事でご説明申し上げます。)
この時、実際に消費した電力が上振れしている場合は、過去データをもとに分析した結果、なんらかの理由で無駄に電力を使っていると判断できます。製造機器の摩耗や劣化で消費電力が増えてしまっている場合、故障となる予備軍を早めに見つけ出すことに繋がります。
下振れしている場合は、過去のデータに比べなんらかの電気系統で通電のエラーがあったなど、電力系統がうまく機能していなかった可能性も考えられます。大規模障害が実際に発生する前に故障予備軍となる不具合を早めに見つけメンテナンスするなどができると考えます。
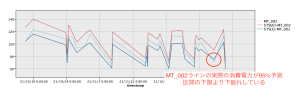
図2 MT_002の95%予測区間 グラフ
SPSS Modeler ストリームの解説
SPSS Modelerの[可変長ファイル]ノードでcsvを読み込み、[ストリーミング時系列分析]で95%の範囲(区画)を算出し、上振れまたは下振れしている場合は[フィールド作成(MT_002異常フラグ)]ノードで異常フラグをつけて[条件抽出(生成)]ノードで異常フラグがついているものだけを抽出し、終端の[フラットファイル]ノードにcsvで出力します。
CADSではどの枝のストリームを実行するか選ぶことができますが、このストリームでは終端は[フラットファイル]ノードのみとしています。

図3 異常検知のストリーム
このModeler フローでは、過去の時系列のデータを見て分析を行うため、分析を行う上で一定のデータ件数が必要となります。1周期分のデータを常に外部システムから、エクスポートするのがよいと思われます。(1周期分:1年、1ヶ月など。新しいデータが追加されたら、古いデータは削除するなどして読み込みデータの肥大化を防ぐ工夫も考慮ください。)
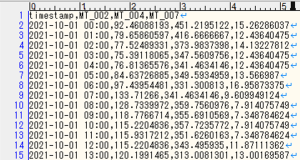
図4 インプットデータサンプル
[ストリーミング時系列分析]ノードは、モデルナゲットを作成せずとも、時系列分析を実施できるノードです。95%の範囲(区間)の予想値を算出するには[モデルオプション]タブで[確信度限界幅]を指定します。
参考)https://qiita.com/416nishimaki/items/11d1581bef7fff2a9ede
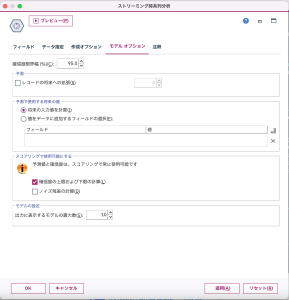
図5 確信度限界幅の設定
[MT_002異常フラグ]ノードでは、実際の電力消費が、時系列分析結果の上限より上か、または下限より下かを式で判定しています。
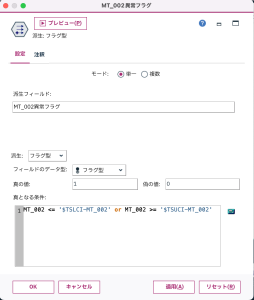
図6 異常の条件の設定
[生成]のノードでは、異常フラグが真(1)だったものだけを抽出し、最後に [フラットファイル]ノードでcsvファイルとして出力しています。
SPSS Modeler ストリームの格納
ストリームを実行して、問題なく動くことが確認できたら、いよいよ、CADSにストリームを登録(格納)します。
[ファイル]→[格納]→[ストリームとして格納]を選択します。
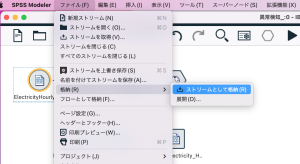
図7 ストリームのCADSコンテンツリポジトリへの格納
初回のCADSアクセス時には、コンテンツリポジトリーのURLとユーザー、パスワードが求められます。
ご参考)https://qiita.com/kawada2017/items/e3689c6086794cecfb45
コンテンツリポジトリへのストリームの格納は動画を取りましたので、こちらもご参考ください。
動画1 ストリームのCADSへの格納
CADS側の設定(ジョブの設定)
CADSのコンテンツリポジトリに保存したストリームをジョブ実行できるように設定します。
ご参考)https://qiita.com/kawada2017/items/3a9b651ecb9509f1d254
主な設定は、ジョブの作成、サーバーの情報の設定、インプットとアウトプットファイルのパスの修正、通知の設定等です。
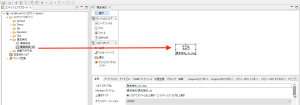
図8 ジョブの設定
ジョブの設定は動画を取りましたので、こちらもご参考ください。
動画2 ジョブの設定
ジョブの設定スケジュール実行の設定
ジョブをスケジュール実行できるように設定します。
ご参考)https://qiita.com/kawada2017/items/3a9b651ecb9509f1d254
ジョブのスケジュールの設定はコンテンツリポジトリのジョブを右クリックし[新しいスケジュール]→[時間ベース]を選択して設定していきます。
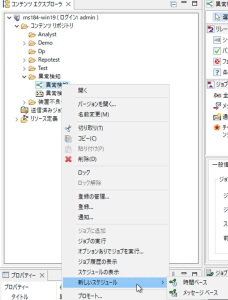
図9 ジョブのスケジュール設定
ジョブのスケジュール実行の設定は動画を取りましたので、こちらもご参考ください。
動画3 ジョブのスケジュール実行の設定
まとめ
今回はSPSS ModelerのストリームをCADSでスケジュール実行する方法をご紹介しました。また、時系列データの分析で便利な[ストリーミング時系列分析]ノードを使って、予測の上限値と下限値を持たせて異常な状態を判断する方法もご紹介しました。
今回ご紹介した内容が、分析のお役に立てるようであれば幸いです。今後もSPSS Modeler および CADSをよろしくお願いします!
さて次回はAIT の林さんが「時系列データを扱う「シーケンス関数」をおさらいしよう!前編」を執筆してくださいます。並行連載の「身近な疑問をヒモトク」ではIBMの河村さんが「秒速で掘り起こす!テキストマイニングはデータが多いほど実効性が高い」を書いてくださる予定です。どちらもお楽しみに。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちらから
→SPSS Modelerノードリファレンス(機能解説)はこちらから
→ SPSS Modeler 逆引きストリーム集(データ加工)

斉藤 明日香
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス
More SPSS Modeler ヒモトク stories

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む
