SPSS Modeler ヒモトク
ブログで学ぶSPSS_Modeler #08- パッと見地味でもベテラン推し!平均値ノードで示す施策の有効性
2022年08月05日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
こんにちは、株式会社MAIの木暮です。
今回は、SPSS Modelerの平均値ノードで示す施策の有効性検証に活用するTipsを、具体例を交えながら掘り下げていきます。
SPSS Modelerの強みは機械学習アルゴリズムやデータ加工ノードだとお考えの方は多いと思います。業務のデータを素早くハンドリングしてモデルを実装できるのは素晴らしいですよね。しかしデータに基づいたアクションをした後、検証はどうしたら良いでしょうか?BIなどで成果を見える化でも結構なのですが、せっかくSPSSを利用しているのですから統計的に裏付けを取りたいですよね。
実はSPSS ModelerでもSPSS Statisticsと同じように t値やF値、χ2乗値などの検定を行うことで施策などの効果検証が可能なのです。
例えば、ある通販会社がAIによるターゲット選定の仕組みをトライするというシナリオで説明します。
まず最初に、ある期間中、全ての顧客にカタログを送付した場合の予測反応スコアを算出します。それをもとに購入額が増えると期待できる対象に絞り込みます。これらの顧客をターゲットとし、実際にカタログ送付施策を実施しました。
施策の効果検証(2グループの平均値比較)
カタログ送付施策実施後、施策実施前と比較して売上が有意に高かったかを検証します。施策実施前1か月間、実施後1か月間、それぞれの顧客1人当たりの売上(平均値)に差があったのか、SPSS Modelerの平均値ノードを使ってt検定を行います。
- 入力データ
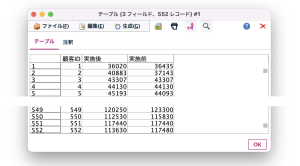
テーブルノードの出力画面(実施後:販売施策実施後の顧客1人当たりの売上金額、実施前:販売施策実施前の選定顧客の売上金額)
- ストリームと平均値ノードの設定
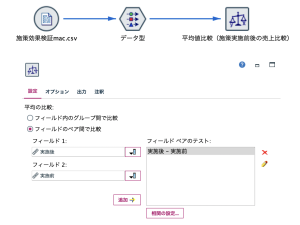
SPSS Modelerの平均値ノードは、2つのフィールドを平均値の差を用いて比較、あるいは1つのフィールドによって独立した集団を平均値で比較することができる機能を持っています。
設定画面から[フィールドのペア間で比較]を選択し、比較対象フィールドを選択・実行することで、次の図のように、すぐに実行結果が表示されます。
結論からすると、今回の施策については、これにより売上に有意な差があったと判断されます。この結論は、今回のサンプルだけでなく、同じ母集団から抽出したサンプルであれば施策前後で同期間に売上に差が出ると推定されます。
ちなみに、同じ母集団から抽出したサンプルで、カタログを送らなかった顧客の同期間の売上を比較したところ、有意な差がなかった、つまり、比較に選んだ期間による季節性などの要因は影響していなかったことが分かっています。
- 平均値ノードの出力
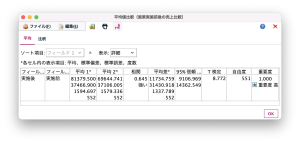
出力結果を見てみましょう。表示項目の[詳細]を選択すると、「T検定」列が表示されます。また、平均値ノードの出力では、有意確率pの代わりに、重要度1-pが算出されます。重要度が0.95を超えていれば(p値が0.05未満)、有意差あり(5%水準で)と判断できます。
ここで、T値を計算式で表すと、以下のとおりです。
※一般的には「t値」と表しますが、平均値ノードの出力表記に合わせて「T値」としています。
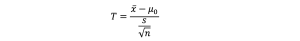
帰無仮説では、同じ顧客に対する施策前後の母平均は差がないと仮定し、対立仮説で差があると設定して、t検定(Paired t-test)を行います。施策による売上の差の平均を x ̅ 、差の母平均を μ₀ 、サンプルの標準偏差を S 、サンプルサイズを n として統計量 T を算出します。施策前後での売上の差が0かどうかを検定するため、μ₀ = 0となります。施策前後の平均値の差が大きければ大きいほど、T値が大きくなります。T値は自由度に応じたt分布(確率分布)に従うため、その値よりも大きな値が得られる確率(p値=有意確率)が計算できます。
自動車製造業:ブランドのイメージスコア比較(3グループ以上の平均値比較)
続いて、分散からデータの傾向を捉える事例を紹介します。
自動車製造業M社が同業他社とのイメージを比較するため、アンケート調査を実施したとします。アンケートでは、「革新的である」(最高100点)と「保守的である」(最低0点)を軸の両極に持つイメージについて点数で回答する質問を設け、また、同様の設問を別の様々な軸で設定しています。(量的変数として扱うことができるよう調整済みの、正規分布に近いスコアを使用したことにしましょう。)
- 入力データ
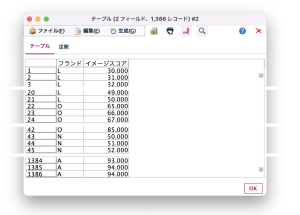
テーブルノード出力画面(6社のイメージスコア回答データ、ブランドごとに0~100のスコアを回答)
- ストリームと平均値ノードの設定
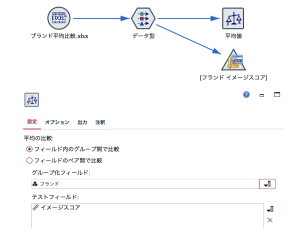
- 平均値ノードの出力
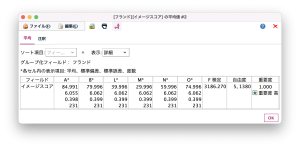
結果をもう少し詳しくみてみましょう。比較値をF値とし、数式で表すと以下のようになります。
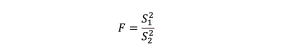
各ブランド平均からの個のばらつきS₂²を分母、全体平均からの各ブランド平均のばらつきS₁²を分子として求められた値がF値です。F検定では、各グループの分散に差がない、という帰無仮説を設定し、各グループの分散に差がある、という対立仮説を設定する統計学的検定手法です。したがって、F値の数値が大きいほど、ブランドとスコアの関係が強いと解釈できます。
ここで、各ブランドとイメージスコアの関係について箱ひげ図を生成すると、次の図のようになります。
- グラフボードノードの設定
- グラフボードノード箱ひげ図の出力
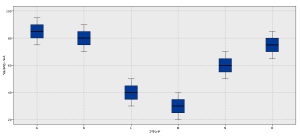
生成された箱ひげ図(X軸がブランド、Y軸がイメージスコア)
ブランド別のイメージスコアの分布が可視化されました。
正確には、箱ひげ図では、箱の下限は分布の第一四分位数(25パーセンタイル値)、箱の上限は第三四分位数(75パーセンタイル値)、箱の中の横線は中央値(50パーセンタイル値)を表しますが、今回は各ブランドの平均値の違いが大きい場合も同様の図になるという前提で観察を続けていきます。
各ブランドについて、回答者の意見がまとまっていて(ブランドの評価にばらつきが少なく)、それぞれのブランド平均値の差が大きいと、上図のようになります。
この例では、M社は他のブランド5社と比較して保守的な印象を抱く回答者が多いことがわかります。同業他社との差別化を図る場合、保守的なイメージを促進するブランディングを企画するとより効果的な施策に繋がるかもしれません。
あるいは、ターゲットや価格、訴求ポイントを変えて、革新的なイメージを普及する必要があるかもしれません。
仮に、各ブランドについて、回答者の意見がまとまらず(ブランドの評価にばらつきが大きく)、それぞれのブランド平均値の差が小さい場合は、次の図のようになります。
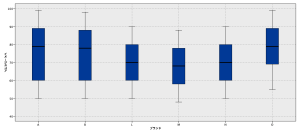
箱ひげ図(X軸ブランド、Y軸イメージスコア)
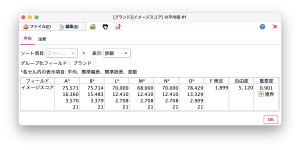
平均値ノード出力結果(6社のイメージスコアの比較、[F検定]の値が小さい)
まとめ
今回はSPSS Modelerの平均値ノードの活用事例を紹介しました。
このように、SPSS Modelerは大量データを加工して精緻化されたデータに対して、多種多様な機械学習を行った結果をアウトプットすることが得意なだけではなく、その結果に従って実施した施策の効果検証までもカバーすることができるツールであることをご理解いただけたのではないでしょうか。データサイエンスの広範囲にわたってワンストップで作業を行い、効率化に役立てていただけるとありがたいです。
さて次回はIBMの西澤さんが「分析のキホン、分割表を制覇する!」を執筆してくださいます。並行連載の「身近な疑問をヒモトク」はIBMの清野さんによる「担当者泣かせの突発的な設備故障。蓄積したデータから予測できるのでは?」です。どちらもお楽しみに。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちらから
→SPSS Modelerノードリファレンス(機能解説)はこちらから
→ SPSS Modeler 逆引きストリーム集(データ加工)

木暮 大輔
株式会社MAI
代表取締役社長

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む