

























SPSS Modeler ヒモトク
ブログで学ぶSPSS_Modeler #07- モデル評価に欠かせない予測変数の重要度!そのカラクリと存在意義
2022年07月05日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
皆様こんにちはIBMの西牧です。
SPSS Modelerでモデルを作成すると大抵の場合、予測変数の相対重要度が出ます。
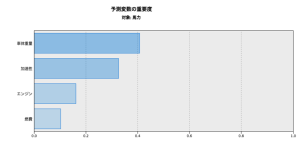
個々のフィールドがどの程度予測に影響を与えたかがすぐ分かるってなかなか良いですよね。重要度を合計すると1になるので直感的です。
でも、ちょっと待ってください。こういう疑問を持たれたことはないですか?
・モデルが独自に算出した寄与度と異なっている。
・モデルを作る度に微妙に変化して再現性が取れていない。
・そもそもこの機能は何のためにあるのだ?
この記事では、よく皆さんから聞かれるこれらについて解説いたします。
なるほど、この重要度分析が「重要」なのだとお分かりいただけると思います(あるいは再確認いただけます)。
予測変数の重要度(Predictor Importance) とは何?
この機能はユーザーマニュアルに記述があるのですが、わかったようで、よくわからないかもしれません。
アルゴリズムガイドのPredicter Importanceの項目に至っては
「予測変数の重要度は,感度分析によって,各予測変数に起因するターゲットの分散の減少を計算することによって決定される」と書かれており
ますます、わからなくなります。
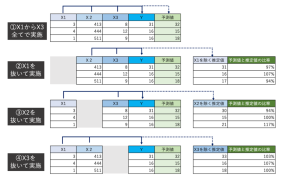
かなり単純に説明すると重要度の算出は次のように行っています(下の図を参照ください)。
まず重回帰を例に取り①全ての予測変数(説明変数)でモデルを作成します。
次に予測変数からX1だけを抜いて重回帰でモデルを作り、最初に作った予測値との違いを計算します(②)。
以降同じようにX2、X3とメンバーを一人だけ抜いたバージョンで実施します。
②③④の推定値の差の分散の合計(正規化)は①の予測値の分散と等しくなるため、X1からX3の重みが判明します。これを予測変数の重要度としています。
つまりサッカーで言うとある選手がレッドカードで欠けたときに、もしチームのパフォーマンスがどれほど減少したかを数値化できれば、その選手の単独での貢献度を推し量れますよね。それと同じなのです。
しかし、よく考えると結構大変な処理です。
重要度を求めるためひとつのモデルにつき入力変数の数だけ内部ではループ処理させなくてはなりません(ロジスティック回帰などは極端に分析速度に影響します)。
この処理の負担を減らすため、大規模なデータセットの場合にはサンプリングされたレコードから計算するので、結果はデータセット内のレコードの順序によって僅かに変化します。
モデルを作り直すと重要度ランキングが下克上する場合があるのはそれが理由なのです。
なぜ予測変数の重要度が存在するのか?
さて、そもそもなぜ重要度を出すのでしょうか?
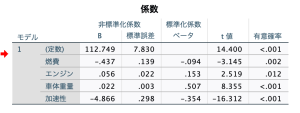
例えば重回帰では入力変数の寄与の具合は独自に求めています。以下の表から標準化係数かt値を確認すればOKですよね。
実はこの機能が登場した当初は「ニューラルネットワーク」はブラックボックスで、同じ機械学習の決定木のような説明能力が足りていないからだと私は勝手に納得していました。2008年のVersion12でまだModelerがClementineという名称だった頃のことです。

さらに白状すると、せいぜい上の図のように「重要度の上位のフィールドの絞り込みを行うのに便利だ」程度にしか受け取っていませんでした。
しかしその後、特に製造業のお客様を中心に冒頭のような質問が相次ぎ、この機能に高い関心とニーズがあることが判明するのです。あるユーザーが
「どれほど予測精度が高くても現場が納得するものではないとモデルは実装されない」と説明してくださいました。
しかも現場は「どのデータを使ってそれを求めたのか」また「どのデータが故障に起因していたのか」という点を自身の経験と照らして納得するまで追求してくるとのこと。
その際に、例えば「モデル甲はaとbの項目を特に重要視しているが、モデル乙はそれとは別にcとdも同じくらい考慮している」と説明できるのは極めて有効だそうです。
つまり個々のモデルに依存しない画一的な入力変数の評価方法は、そのモデルの実装を判断する現場へのうってつけの機能だったのです。
予測変数と実装後のモデルのあり方
もう一つマーケティング系のあるユーザーとの会話中で、重要度の別の側面に気付かされたことがあります。2015年頃のことだったと記憶しています。
そのユーザーは「精度が崩れてからでは損失が大きいため、モデルが重視した入力変数の挙動もモニタリングして手を打っている」のだと言うのです。
今で言う「特徴量ドリフト」です。
2022年の今となっては予測モデルが実装された後、CADSなどで、その精度を検証して必要に応じてリニューアルを行うことが浸透しつつありますよね。この枠組みはMLOpsと呼ばれ別の記事でも詳しく紹介しています。
→なぜMLOpsが必要なのか(IBM ProVision記事)
「MLOps」という言葉が流行する前からその重要性に気づき実践していたのだと今更ながら感服します。
まとめ
予測変数の重要度は、その変数がなかった場合に予測値にどれだけインパクトが起きるかを内部ループで計算させ、モデルに依存しない画一的な方法で評価を行います。精度とは独立して貢献度を比較することは現場への説明に有効であり、実装後のモデルチューニングの材料にもなります。少し値が変動したり、モデル固有の説明を少し食い違いを見せても十分な価値があるとお分かりいただけたでしょうか?
さて次回はMAIの木暮さんが「パッと見地味でもベテラン推し!平均値ノードで示す施策の有効性」を執筆してくださいます。並行連載の「身近な疑問をヒモトク」ではIBMの角田さんが「ニュースでよく見るイケてる地図グラフを自分でもサクッと描いてみたい」を書いてくださる予定です。どちらもお楽しみに。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちらから
→SPSS Modelerノードリファレンス(機能解説)はこちらから
→ SPSS Modeler 逆引きストリーム集(データ加工)

西牧 洋一郎
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス
著書に「実践IBM SPSS Modeler 顧客価値を引き上げるアナリティクス」
共著書に「実践! 異常検知と故障予測―IBM SPSS ModelerによるIoT時系列データ活用」

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む