

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
ブログで学ぶSPSS_Modeler #02- Google BigQueryでSPSS Modelerプッシュバックを実行する
2022年02月21日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
2022年のリレー連載新シリーズ「ブログで学ぶSPSS Modeler」の第2回担当の日本情報通信(NI+C)森山です。
第1回担当のIBM坂本さんからバトンを受けまして、皆様の業務効率化やお悩み解決に繋がる「これぞModeler!」という機能を掘り下げてお届します。
弊社は、SPSS Modelerを中心としたSPSS製品販売からトレーニング・分析業務定着化等の活用に関するご支援を100社以上の企業様に実施しております。
→※日本情報通信(NI+C)のSPSS事例・サポートサービスサイト
SPSS Modeler活用をご支援する中で、大規模なデータを扱った分析処理におけるパフォーマンス面でのお悩みを多くのユーザーからお聞きする機会が増えております。
これらパフォーマンス面でのお悩み解消に向けて、今回はSPSS Modelerが提供する「SQLプッシュバック機能」とGoogle BigQueryを組合せて大規模データを簡単・高速処理を実現する方法について解説します。
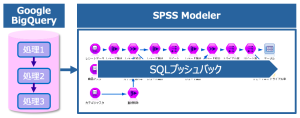
SPSS ModelerのSQLプッシュバック機能とは?
SPSS Modelerでは、作成したストリームにおける条件抽出/結合/集計等の各種処理を自動でSQLを生成してデータベースに発行する「SQLプッシュバック機能」を提供しています。
大規模データを扱った分析において、PC等のローカル環境でファイル(分析データ)を準備してSPSS Modelerの処理を行う場合、「いつまでも処理が終わらない」等のパフォーマンス面での懸念が出てきます。
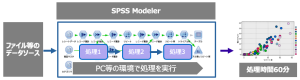
このようなケースでは、SPSS Modelerと大規模データを扱うデータベースを連携して処理を行うことが一般的ですが、「SQLプッシュバック機能」によりSPSS Modelerの処理をデータベース内で完結させ、分析処理の高速化を実現可能です。

「SQLプッシュバック機能」では、SPSS Modelerが自動でSQLを生成し、連携先のデータベースに最適な指示を行いますので、ユーザーは、SQL等の専門知識がなくてもSPSS Modelerのストリームを作成・実行するだけで多くの処理を高速・効率よく実現できます。
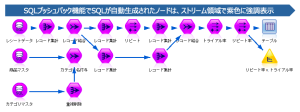
また、SPSS Modelerのストリーム内でSQLが自動生成されたノードは、ストリーム領域で紫色に強調表示されますので、視覚的にもわかりやすい機能です。
※SQLプッシュバック機能が利用可能なノードは、連携先のデータベースノードによって異なります。
過去の関連ヒモトクブログ記事はこちら
→SQL魔法使い「データベースノード」がとどめの呪文で運用処理速度を向上
Google BigQueryとSPSS Modelerプッシュバックでさらに高速化・効率化!
SPSS Modelerの「SQLプッシュバック機能」では、作成したストリームの各種処理を自動でSQLを生成・データベース側で分析処理を実行することになりますので、連携先データベースのパフォーマンスが非常に重要となります。
今回SPSS Modelerの連携先データベースとして紹介するGoogle BigQueryは、データ容量・処理量に応じて自動でスケールするため、データベースのチューニング等の運用負荷なしで効率的に高速・安定したパフォーマンスを発揮するデータベースです。
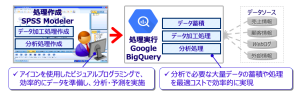
Google BigQueryは、分析に集中したいSPSS Modelerのユーザーにとって、とても相性がよいサービスのため、SPSS Modelerの連携先データベースとして非常に多くのユーザーが利用しています。
以下では、Google BigQueryを使用したSPSS Modelerの「SQLプッシュバック機能」の利用手順を紹介します。
Google BigQueryでSPSS Modelerプッシュバックを実行する手順
Google BigQueryを使用したSPSS Modelerの「SQLプッシュバック機能」は、以下手順で利用可能です。
ステップ1.事前準備
ステップ2.SPSS Modelerストリームを実行して結果を確認
事前準備として、Google BigQuery等のデータベースへ接続用のODBCドライバ導入が必要となりますが、非常に簡単なステップで「SQLプッシュバック機能」を利用いただけます。以下では各ステップの詳細をご案内します。
ステップ1.事前準備
・データベース接続用のODBCドライバ導入
まずは、データベース接続用のODBCドライバ導入を行います。
SPSS ModelerがGoogle BigQuery接続でサポートするODBCドライバは、「Simba ODBC Driver」です。
ダウンロードサイトから「Simba ODBC Driver」をダウンロードし、データベース接続を行うSPSS Modeler環境上に導入します。
※Google BigQuery以外のデータベースに接続する場合、SPSS Modelerがサポートする各データベース接続用のODBCドライバを導入ください。
※SPSS Modelerバージョンによりサポートする「Simba ODBC Driver」のバージョンが異なります。
・データベース接続用のODBCドライバ設定
データベース接続を行うSPSS Modeler環境上に「Simba ODBC Driver」を導入した後は、データベース接続に必要な各種設定を実施ください。
Windows環境の場合、「ODBCデータソース」画面から各種ODBC設定が可能です。
・SPSS Modelerストリームで「SQLプッシュバック機能」関連設定を確認
「SQLプッシュバック機能」によるSQL自動生成結果等の詳細は、以下詳細設定によりSPSS Modelerストリーム領域のストリームメッセージでログを確認可能です。
まずは、SPSS Modelerを起動し、メニューバーから「ツール」>「ストリームのプロパティ」>「オプション」を選択ください。
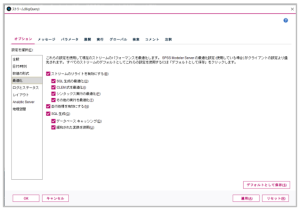
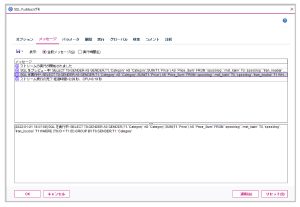
選択後、「オプション」タブ内の「最適化」を選択すると以下の画面が表示されますので、各項目にチェックが付与されていることを確認ください。
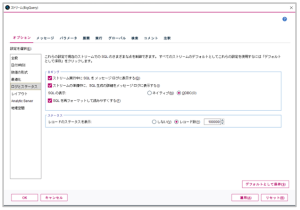
次に「オプション」タブ内の「ログとステータス」を選択すると以下の画面が表示されますので、各項目にチェックを付与してください。本設定でSPSS Modelerストリーム領域の「ストリームメッセージ」で生成されたSQL等のログが表示されます。
ステップ2.SPSS Modelerストリームを実行して結果を確認
・Google BigQuery内の購買/会員データを使用した結合や集計処理を「SQLプッシュバック機能」を使用して高速に実行
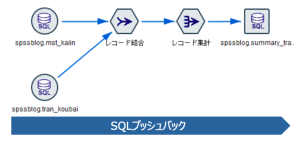
今回は、Google BigQuery内の購買/会員データを使用した各種データ加工処理を「SQLプッシュバック機能」を使用して実行します。
「SQLプッシュバック機能」により、大量の購買/会員データを使用する際に処理時間を要する結合や集計処理が、Google BigQuery上で処理実行されるため、処理の高速化を実現可能です。
・データベースノードからGoogle BigQuery内のテーブルに接続
「入力」パレット内の「データベース」ノードをストリームキャンバス上に配置し、プロパティを開きます。
「データソース」にGoogle BigQueryの接続情報を入力し、「テーブル」に接続先のGoogle BigQueryテーブル名を指定します。
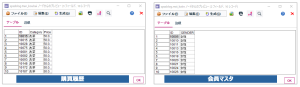
指定したテーブル内のデータはプレビューから確認可能です。今回は、Google BigQuery内に蓄積された以下の購買履歴と会員マスタを使用します。
・購買履歴と会員マスタの結合と集計処理を「SQLプッシュバック機能」で実行
今回は、購買履歴と会員マスタの結合処理を行った後、集計処理により性別ごとの購買金額を算出します。これらのデータ加工処理は「SQLプッシュバック機能」を使用してGoogle BigQuery上で高速に実行可能です。
※購買履歴と会員マスタの結合処理は、「レコード設定」パレットから「レコード結合」ノードを配置し、「レコード結合」ノードの結合キーにIDを指定します。その後、購買履歴と会員マスタを参照している「データベース」ノードから接続します。
※集計処理は、「レコード設定」パレットから「レコード集計」ノードを配置し、集計キー等を設定した後、「レコード結合」ノードから接続します。
性別ごとの購買金額を算出するための「レコード集計」ノードに「テーブル」ノードを接続・実行すると以下の結果が表示されます。
「SQLプッシュバック機能」を使用してGoogle BigQuery上で処理が実行されている場合、各ノードがストリーム領域で紫色に強調表示されます。
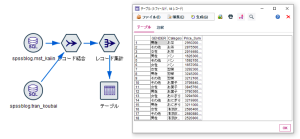
また、ストリーム領域の下部「ストリームメッセージ」から、「SQLプッシュバック機能」によるSQL自動生成結果等の詳細を確認可能です。
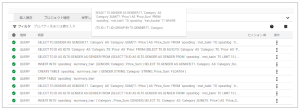
今回実行した結合・集計処理の内容は、「ストリームメッセージ」に表示されたSQLが自動生成・Google BigQuery上で処理が実行されています。
「SQLプッシュバック機能」により自動生成されたSQL内容や処理結果は、Google BigQuery環境のログからも確認可能です。Google BigQueryのコンソール画面から、今回の処理内容が以下のイメージで表示されます。
ここまで紹介した手順で、Google BigQueryを使用したSPSS Modelerの「SQLプッシュバック機能」を利用・実行確認までが可能です。
まとめ
今回は、Google BigQueryを使用したSPSS Modelerの「SQLプッシュバック機能」を紹介しました。
手順内で紹介した結合や集計処理だけではなく、さまざまな処理をSPSS Modelerが提供する「SQLプッシュバック機能」で高速化可能ですので、大量データの処理パフォーマンスでお困りのユーザー様で是非ともご活用ください。
また、SPSS Modelerでは、Google BigQuery以外のデータベース製品を使用して「SQLプッシュバック機能」を使用可能ですので、みなさまが利用中のデータベースと連携してご活用いただけると幸いです。
→ODBCを介してデータベースを読み込むデータベースノードの記事はこちら
また、今回ご紹介したSPSS ModelerとGoogle BigQueryの連携やご利用に関するご相談は、Google Cloudのプレミア パートナーの弊社までお気軽にお問い合わせください。
→※日本情報通信(NI+C)のGoogle Cloud関連サービス
次回ブログで学ぶ#03はIBMの山下さんが、SPSS Modelerを利用した「名寄せ」を解説。
そして身近な疑問にヒモトク#02は気象予報士でもあるIBM西川さんが「気象データの誤解」について執筆されます。。
どちらもお楽しみに!
→これまでのSPSS Modelerブログ連載のバックナンバーはこちらから
→SPSS Modelerノードリファレンス(機能解説)はこちらから

森山 隼
日本情報通信株式会社
バリューインテグレーション本部
データテクノロジー部
More SPSS Modeler ヒモトク stories

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む
