SPSS Modeler ヒモトク
ブログで学ぶSPSS_Modeler #01- 予測モデル安定化のためのN分割交差検証をPythonスクリプトでチャレンジ
2022年01月05日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
皆様こんにちはIBMの坂本です。SPSS はじめデータサイエンス系のソリューションを担当しています。
いよいよ2022年の新シリーズ「ブログで学ぶSPSS Modeler」が始まりました!僭越ながら第1回のトップバッターを務めさせていただきます。このシリーズでは過去の連載「わたしの推しノード」と「Modelerデータ加工Tips」を通じて触れてきた「これぞModeler!」という機能を掘り下げてお届します。並行して日常の疑問をデータで解決する「身近な疑問にヒモトク」も連載を予定していますのでお楽しみに!
さて、「Modelerデータ加工Tips」連載のアンカー、本田技研工業の小川様にはGUIループを解説いただきました。私は、それに関連して「Pythonスクリプト」をN分割交差検証を例にして紹介してみたいと思います。
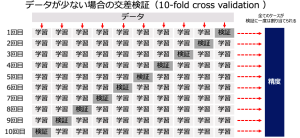
N分割交差検証 (N-fold cross validation)とは
交差検証の目的は、訓練データによるモデルの過学習を防ぐと同時に、テストデータでの汎化性能を高め、モデルの精度を安定化する、ということで、いくつか手法があります。
今回取り上げる、N分割交差検証は、データが少ない場合に特に有用な手法です。元データを N個にランダム分割し、順番にテストデータとして使用し、残りの N-1個のデータを学習に使用し、それぞれが1回ずつテスト対象となるよう合計N回計算します。
その交差検証のロジックを Python スクリプトでコーディングして、Modeler に実行させるのが今回の目的です。
Pythonスクリプトを用いた交差検証の手順
使用するストリームとデータ
利用するストリームは、以下です。入力パスを2箇所、出力パスを1箇所変更する必要があります。
https://github.com/yoichiro0903n/blue/blob/main/10fold_py2.str?raw=true
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
以下の内容を動画でも説明しています!
SPSS Modeler のストリーム内で Python スクリプトを実行して、実際に、交差検証の流れを確認していきましょう。
試しに、データ区分ノードを配置して確認してみると、デフォルトで学習データとテストデータが50%ずつに分割されています。この区分と比率のままでもいいですし、ここに検証データを加えて、3分割してデータを使用することもできます。いわゆる「ホールドアウト検証」ですが、今回は N分割交差検証ですので、データ区分ノードは使用しません。なお、テストデータと検証データの違いはこのリンクを参考ください。
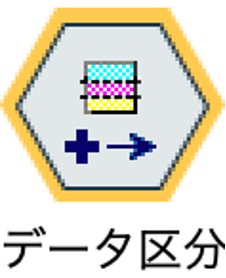
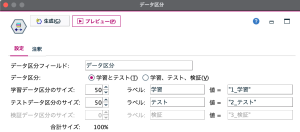
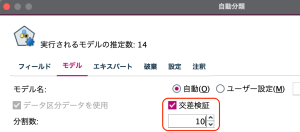
今回のようなケースでは、通常、自動分類ノードを使うこともあるかと思います。実際、自動分類ノードの中で、交差検証できるようになっており、分割数も指定できます。今回、自動分類ノードを使えば、スクリプトなしでも実現できるのですが、ここでは、交差検証と同時に、Python ループ処理の解説を目的にしているので、あえて自動分類ノードを使わずにストリームを作成してみます。

それでは、Modeler ストリームの流れに沿ってみていきましょう。
対象データは Modeler 同梱のサンプルで ‘Drug’ というファイルを使います。目的変数を「コレステロール」とし、値の ’High’ と ‘Normal’ を予測するモデルを作ります。説明変数は「コレステロール」以外の列です。
このデータに①「グループNo」列を追加しています。ここであとから交差検証が可能なように、各レコードに対して、0から9までの10のグループ番号を割り当てます。番号割り当てにはランダム関数を使っていますが、のちに Python ループを廻す(=ストリームを複数回実行する)関係で、毎回処理のたびにランダムにケースが入れ替わるのを阻止するために、キャッシュをオンにしています。(何回データを表示しても同じグループ番号がケースに割り当てられます。)
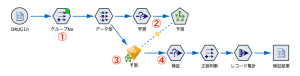
元データを10に分割した中で、例えばグループ番号9を捨てて0から8までで学習し、取り置いた9で検証しています。(「学習」「検証」の各ノード内の計算式:グループNo=9を’破棄’ or ‘含める’ でコントロールしています。)
②で「予測」ノードを実行してみましょう。ニューラルネットワークの実行結果がナゲット③として表示されます。(サンプルではすでに実行済み)
‘$X−’の予測結果が返っています。(グループNo = 0〜8までで学習した結果)

今度は、この学習モデルを使って、グループNo = 9のレコードを対象にして④で検証してみましょう。
その後の「正誤判断」としているのは、実際の値と予測結果が合致している割合、いわゆる正解率(Accuracy)です。精度分析ノードを接続して、一致行列にチェックして確認してみるとわかりますが、混同行列の正解に該当する1と5の和が行列に占める割合、今回の例では6/9 =66.67%が正解率になります。(ランダム関数のグループ番号割当てにより正解率は変わります。)
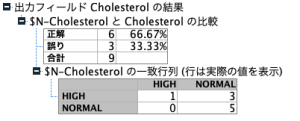
レコード集計で番号9の検証グループでは66.67%の正解率が計算されて、あとはグループを入れ替えながら10回繰り返してレコードを追加していきます。
ここで、実行されている Python スクリプトを確認しましょう。ストリームのプロパティから実行タブを開きます。Python スクリプトがこのように用意してあります。下記メニュー遷移(’ツール’->’ストリームのプロパティ’->’オプション’)もしくは画面下部の … アイコンをクリックします。
’実行’タブに切り替えると、 Python スクリプトが表示され、同時に、ストリームの実行時にこの Python スクリプトが実行されるように設定されています。
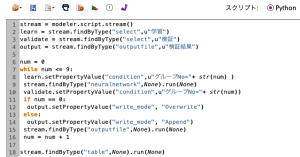
ループのカウンター num=0 からコロンまでの句でループの開始を定義しています。ループ内では if else によって、1回目の処理は Overwrite、2回目以降は Append と定義してあります。
それでは、いよいよ再生ボタンを押してみましょう。
ゼロから9までの10回処理がループされ、最後に一つのファイルにまとめてから、今回の目的だった全体の精度の平均(最終的には、この例では、58.5%) が出力されます。
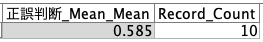
Python スクリプトを使ったループ処理による 10分割交差検証のご紹介は以上となります。
まとめ
今回は、Python スクリプトをModeler のさまざまな機能(キャッシュ、ランダム関数、ニューラルネットワーク)と組み合わせて、あえてデータ区分ノードや自動分類ノードを使わず、やや力技でしたが交差検証に挑戦してみました。いかがでしたでしょうか?
Modeler の提供する豊富な機能を最大限活用しつつ、Python で提供されるオープンなライブラリはもちろん、蓄積された自社独自の分析資産を組み込んで、データサイエンス・ソリューションの可能性が無限に、高度に拡大するのを感じていただけたら幸いです。
柔軟にオールマイティーな分析ができてしまう一方、注意点としては、Modeler 単体、Python単体でそれぞれ実装している場合と比較して、適材適所にどのロジックをどちらが担っているか、コメント等を活用し見える化しておくことは従来以上に重要になってきます。
次回ブログで学ぶ#02は2月初旬に日本情報通信の森山さんが、SQLプッシュバックを取り上げてくださいます。
そして「身近な疑問にヒモトク」連載は1月下旬に第1回「幹事の悩み!オンライン飲み会の部屋割りは最適化で解決」をIBMの阪本正治さんと中島文さんがお届けします。
どちらもお楽しみに!

坂本 康輔
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む