

























IBM Watson Blog
Watson Discoveryで隠れた洞察を簡単に見い出す
2020年04月13日
カテゴリー IBM Cloud Blog | IBM Data and AI | IBM Watson Blog | 人工知能
記事をシェアする:
世界経済フォーラムの予想によれば、日々生成されるデータは463エクサバイトを上るといわれています。大局的に見ると、これまで人間が交わしてきた語数の約90倍ものデータに相当します。これほどのデータをすべて理解しようとすると、気が遠くなります。
2019年、IBMではこの課題に対し、Watson Discoveryコンテンツ・マイニングのリリースで対応できるようになりました。これは、世界で最もパワフルな、AIを活用したテキスト・マイニング・ツールで、ビジネス・ユーザーやテクニカル・ユーザーは文書内の異常、傾向、関係を分析し、隠れた洞察を見い出すことができます。
Watson Discoveryのコンテンツ・マイニングに備わる優れた特徴や機能をすべて並べ立てるよりも、実際にどうすればたった数回のクリックで洞察を見い出すことができるのかをご覧いただきたいと思います。
Watson Discoveryが扱うのはお客様の独自のビジネス・データですが、このブログでは、消費者金融保護局(CFPB)が公表しているデータ・セット[1]を使用して、Watson Discoveryの機能を実証します。CFPBは、銀行、融資会社、およびその他の金融会社に対する消費者の苦情を受け付ける、アメリカ合衆国の政府機関です。ここで使用するCFPBデータ・セットには、2016年から2019年までの370,000件近くの苦情が含まれています。
コンテンツ・マイニングの適用方法
新たな洞察を見いだすための手助けとなるコンテンツ・マイニングのいくつかのサンプル・シナリオを通じて、苦情のデータ・セットを掘り下げながら見ていきましょう。
シナリオ1: 米国企業全体について寄せられた上位の苦情を特定する
コンテンツ・マイニングの「Pairs View (ペア・ビュー)」を使用すると、米国の企業に寄せられた上位の問題を容易に特定できます。「Pairs view (ペア・ビュー」」を使用して、任意の2つのファセットを比較し、各ファセット(検索候補)の関連性と件数を確認できます。下の画面では、CFPBデータ・セットから、CompanyとIssueという2つのファセットを選択しました。米国の主要な3つの信用調査所(Equifax、Experian、TransUnion)に対して、上位3つのタイプの苦情が寄せられたこと、またそれらが信用報告書に記載された情報の誤りに関連するものであることが分かります。

シナリオ2: 州間の苦情の関係を特定する
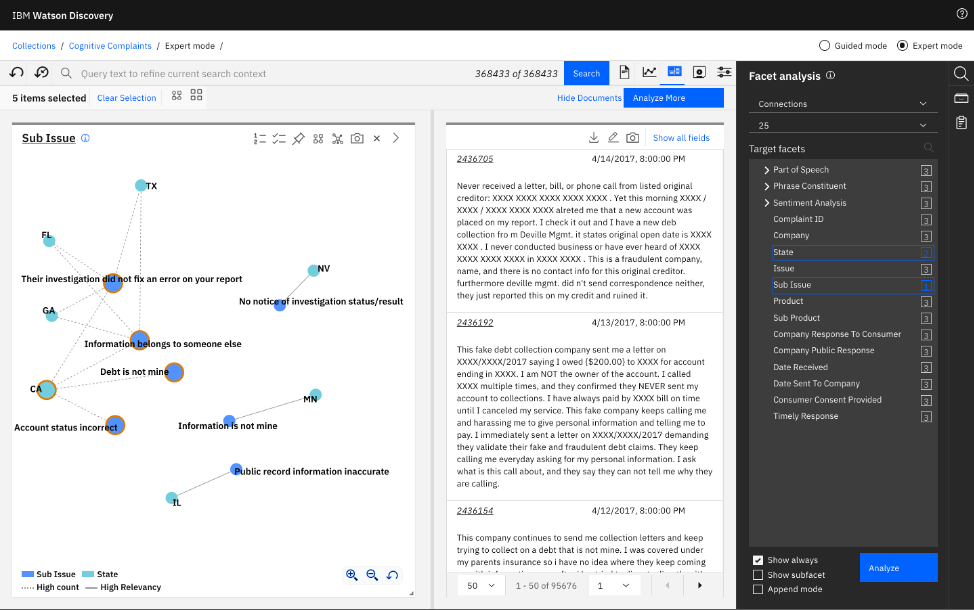
コンテンツ・マイニングの「Connection view (コネクション・ビュー)」を使用すると、異なるファセット間の関連性がグラフィック形式で示され、ほかの方法では見つかりにくい相関関係を見つけることができます。下の画面では、多数のファセットを選んで可視化できる、コンテンツ・マイニングの「Connections view (コネクション・ビュー)」を使用しました。この例では、ファセットとしてState(州)とSub-issue(問題の詳細)を選択しました。グラフィックには、この2つの関連性が示されており、ここから関心のあるエンティティー(例えば、カリフォルニア州と、関連する問題の詳細など)を簡単に選択できます(この事例では、データ・セットから95,000件を超えるエントリーが得られました)。「Analyze More (さらに分析)」をクリックして内容をクエリに追加することができます。これにより、手動でクエリを作成する場合に比べ、少ない労力で、クエリの一貫性も向上できます(コンテンツ・マイニングでは、必要に応じて、最上部のバーに手動でクエリを入力することもできます)。
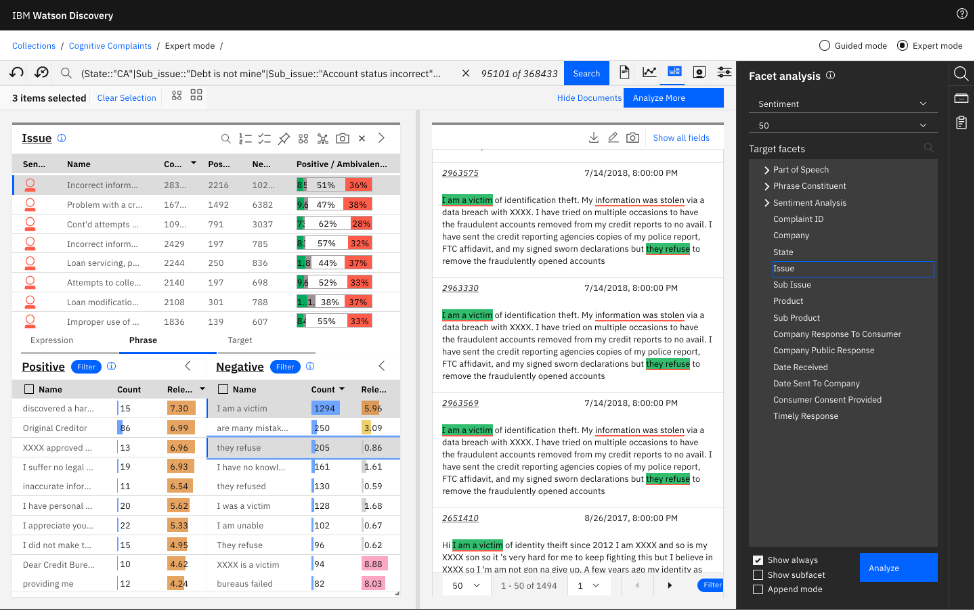
シナリオ3: 最も否定的なセンチメントに分類された苦情および企業を特定する
コンテンツ・マイニングの「Sentiment view (センチメント・ビュー)」を使用すると、入手可能なあらゆるファセット全体でのセンチメントを分析できます。このシナリオでは、画面の最上部にあるクエリバーに示されているように、直前のシナリオで選択された項目である、カリフォルニアの消費者によって報告された4つのタイプの問題の詳細をそのまま保持しました。ここで、すべての問題にわたって消費者の全体的なセンチメントを見てみましょう。下の画面を見ると、好意的(緑)、好意的でもあり否定的でもある(グレー)、どちらでもない(白)、否定的(赤)という、問題ごとのセンチメントの分布が、左上のウィジェットで分かります。リストの最初の問題「Incorrect information on credit report(信用報告書に記載された情報が誤っている)」を見ると、センチメントを示す具体的なテキストを分析できます。例えば、左下のウィジェットで否定的な語句を抜擢してみると、人々の苦情が、なりすまし犯罪の被害者となったことや、企業が不正に開設されたアカウントの除去を怠っていることに集まっていることが分かります。
シナリオ4: 苦情の傾向および急激な増加を特定する
「Trends view (傾向ビュー)」と「Relevancy view (関連性ビュー)」を使用すると、データをさまざまな角度から理解できます。構造化された一部のデータの内訳を知ることで、数カ月あるいは数年にわたる苦情の傾向の全体像だけでなく、(苦情の中の関連語句を特定することにより)苦情の理由が分かるとともに、受けた苦情の数が最も多い企業も特定できます。
下の画面では、「Trends view (傾向ビュー)」で、月ごとの詳細結果の傾向を見ていきます。信用報告書関連の結果を展開すると、2017年の後半にかけて苦情の報告件数が急増しています。この特定の月を選び、クエリに追加してみました。
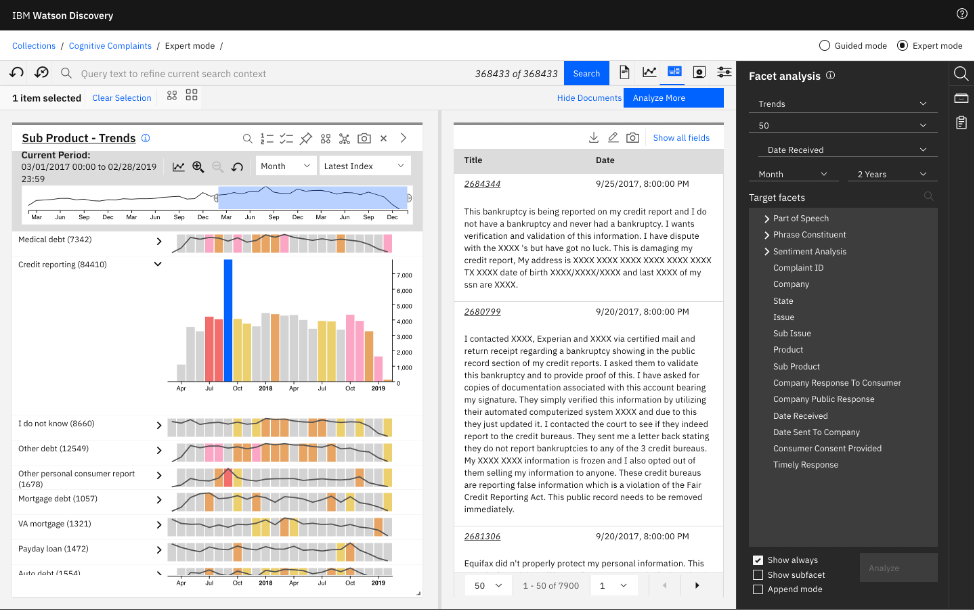
「Relevancy view (関連性ビュー)」に戻り、企業名(次の画面に示されています)を見ると、その特定の月に受けた苦情の大半はEquifaxに向けられており、同じ期間に苦情を受けた他のすべての企業の合計を上回っていることが分かります(既にその理由についてもお気付きかもしれませんが、引き続き掘り下げていきましょう)。

次に、コンテンツ・マイニングによって特定された語句を使用して、苦情の理由を見つけることができます。例えば、使用可能な複合名詞を選択することで、「セキュリティー・ブリーチ」や「データ・ブリーチ」といった語句があることが分かります。これらの語句はまさに、2017年にEquifaxが被った、数百万件の顧客情報が漏えいしたデータ侵害事件に関連するものであり、数ある苦情の中でも群を抜いてCFPBに苦情が殺到することになった原因であり、上記の「Relevancy view (傾向ビュー)」でも急増している様子がわかります。

おわりに
データおよび分析の分野では、「百聞は一見にしかず」という格言ほど、的を射たものはありません。可視化こそ、洞察を見いだし、理解し、共有するためのパワフルな方法です。ここでご覧いただいた方法は、Watson Discoveryのコンテンツ・マイニングを使用してデータをさまざまな角度からの切り口で捉え、さまざまな疑問に答え、新たな洞察を見いだすための、ほんのいくつかにすぎません。
原文:One Does Not Simply Find Hidden Insights … Until Now (https://medium.com/ibm-watson/one-does-not-simply-find-hidden-insights-until-now-22201872a25a)

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

セキュリティー・ロードマップ
IBM Cloud Blog
統合脅威管理、耐量子暗号化、半導体イノベーションにより、分散されているマルチクラウド環境が保護されます。 2023 安全な基盤モデルを活用した統合脅威管理により、価値の高い資産を保護 2023年には、統合された脅威管理と ...続きを読む

量子ロードマップ
IBM Cloud Blog
コンピューティングの未来はクォンタム・セントリックです。 2023 量子コンピューティングの並列化を導入 2023年は、Qiskit Runtimeに並列化を導入し、量子ワークフローの速度が向上する年になります。 お客様 ...続きを読む