IBM Cloud Blog
第24回『Kubernetesで実装されたサービス品質が、すぐに向上する新しい管理手法とは』
2023年04月10日
カテゴリー IBM Cloud Blog | IBM Partner Ecosystem
記事をシェアする:
こんにちは。継続的な最適化(Continuous Optimization-CO)という管理手法をご存知でしょうか?
今回は、日本IBM Turbonomic TechSales笹原、中島よりコンテナ環境のアプリケーション性能とその環境のITリソース管理において、標準Kubernetes機能では実現できない課題をどう解決できるか、”継続的な最適化(CO)”という管理手法の説明とメリットをご紹介します。
アプリケーションサービス開発CI/CDフェイズの次で必要となるCOフェイズ
サービスをユーザに提供するために迅速かつ高品質なアプリケーション開発をする手法として、クラウドネイティブコンテナ開発において、CI/CDがかなり普及してきていると実感しています。
では、アプリケーションサービスを展開後に実際には何をしますか?運用部隊にサービスを引き継いで、運用管理(障害、性能・品質管理)フェイズに移行するかと思います。最近では、DevOpsという運用手法との融合により円滑に、タイムギャップ無く運用管理フェイズに移行できる組織も増えました。
しかし、実際のサービス品質とアプリケーション性能の維持、改善にはKubernetesの仕様制限や人材的な組織課題・その他によって、継続してサービス品質を維持、より良くしていくループへの移行が困難な場合があります。
そのサービス品質を維持、改善するために特にコンテナ環境のITリソース・性能に注目した”継続した最適化(CO)”と呼ばれる管理手法があります。
運用の人的リソースがそもそも不足している、スキルの高い人材に依存した属人的な対応をしている組織的な課題も解決できる管理手法と考えています。
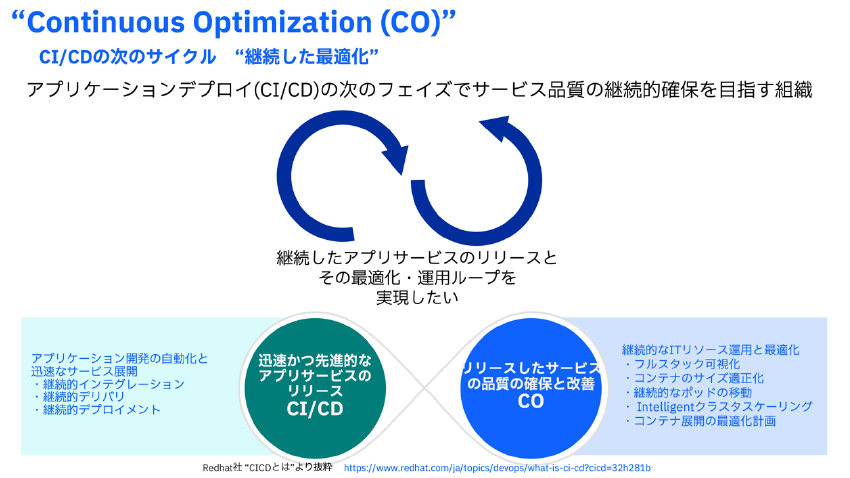
図1:継続した最適化(Continuous Optimization)の概念
可観測性と融合した実際に利用できるCO管理手法
CNCFでは、”可観測性と分析/継続的な最適化(Observability and Analysis Continuous Optimization)”という管理手法を推奨しています。
サービスの継続的な最適化をするためには、可観測性の監視と分析手法と密に連携する事でユーザの課題解決や導入の容易さ、更なる実効果を提供できます。
図2は、実際にCNCFで公開されている” 可観測性と分析/継続的な最適化”を実現できるツール群です。

図2:CNCFでも紹介されている“可観測性と分析/継続的な最適化”ソリューション
可観測性と分析/継続的な最適化”イメージ
具体的に、この”可観測性”と連携した”継続した最適化”で何ができるかを説明します。しっかりとビジネス成果を出し、継続的な最適化をするために3つの観点を含む事が重要です。
- 可観測性(アプリを含むフルスタック環境の網羅的な可視化と監視)
- 実際に実行できる最適化アクションとその洞察
- 運用自動化の連携
です。
この視点で、各ツールの利用、多種ワークフロー運用自動化の連携まで実現できているユーザはアプリ性能20%アップ、パブリッククラウドの支出を30~50%削減、チームの生産性35%向上、アプリ市場導入までの時間40%短縮と劇的な効果実績があります。
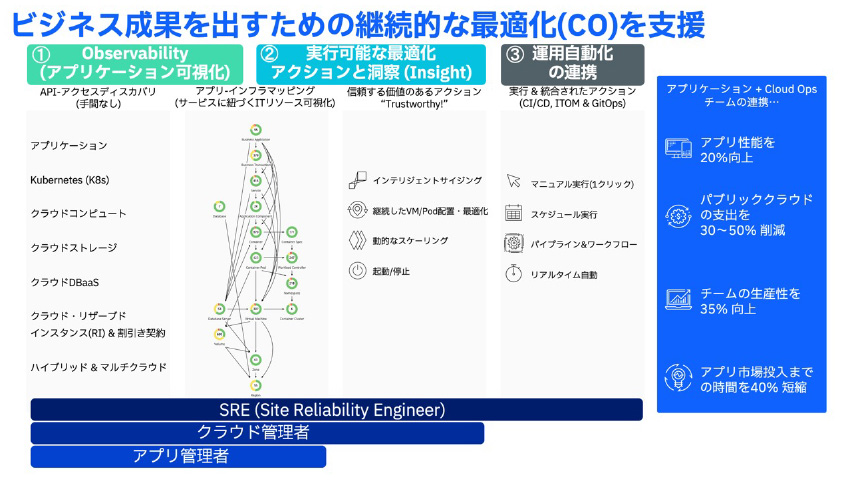
図3:COを実現する3つの運用アプローチ
では、Kubernetes環境に対して管理ツールを利用した場合、どのようなITリソース最適化ができるかご紹介します。
IBM Turbonomicツールでは、CNCF準拠のKubernetes環境であればオンプレミス、各パブリッククラウドKubernetesでも、OpenShiftのような商用パッケージKubernetesでも図5のようなITリソース最適化が実現できます。
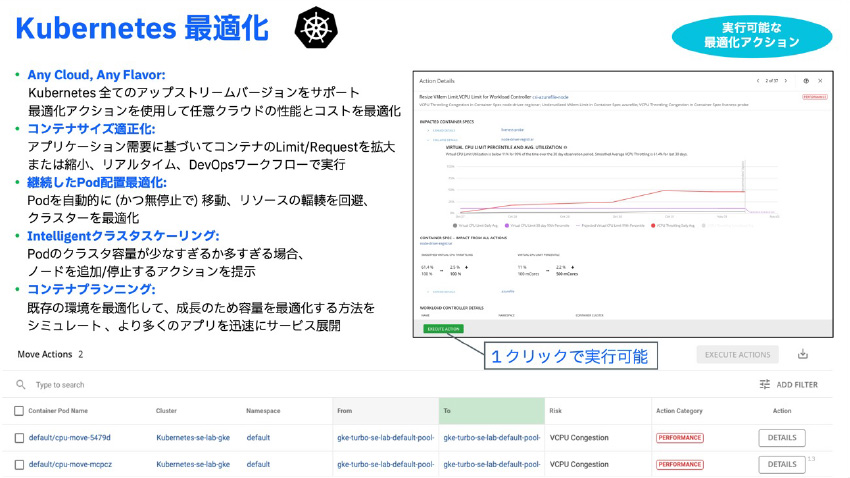
図4:IBM TurbonomicによるKubernetesのリソース最適化
この内容なら、Kubernetes環境をすでに運用しているユーザ様でしたらKubernetesネイティブ機能と運用の連携で実現できているとご指摘されるかもしれません。
実は、ネイティブKubernetesのHPA(水平Pod自動スケーリング)や名前空間クォータ機能だけで実現できない課題があります。
私が好きなIBM Turbonomicが訴求するメッセージとして、“Kubernetesは、自己回復(Self-Healing)できるが、自己最適化(Self-Optimizing)するものではない”があります。
自己回復はあくまで、受動的・事後対応であって自己最適化の能動的・事前対応ができないという意味です。具体的に説明致します。
Kubernetes”自己回復 ”機能、Kubernetes標準のリスケジュール(再配置)、スケーリングを利用した場合
1)Pod配置:最初のPod配置のみを行い、リソース需要の変化に対応できない
2)水平Pod自動スケーリング:Pod Eviction(強制立ち退き)でのみPodの再配置が行われ、性能保証が困難
3)名前空間クォータ:コンテナPod内静的リミット値割り当ての制限、Workerノード間のリソース使用量が均等ではなく、リソースの有効活用ができない(固定リソース割り当て)
IBM Turbonomicとの連携で実現するKubernetes ”自己最適化”機能の場合
4)動的Pod配置:Requestや実リソース使用率、Pod密度に基づいたPodの再配置(ノード間移動)をリアルタイムかつ継続的に実施可能
5)予防的水平Pod自動スケーリング:Podの停止を伴わないWorkerノードリソースの輻輳を未然に防止(事前対応・能動的)
6)垂直スケーリングとリバランス:コンテナPod内実利用に応じたCPUリミット値調整、Workerクラスタ内、Namespace間のリソースのリバランスと新しく追加されたWorkerノードの有効利用
具体的に、説明をしたイメージは以下になります。
1), 4)Podの再配置(ノード間移動)
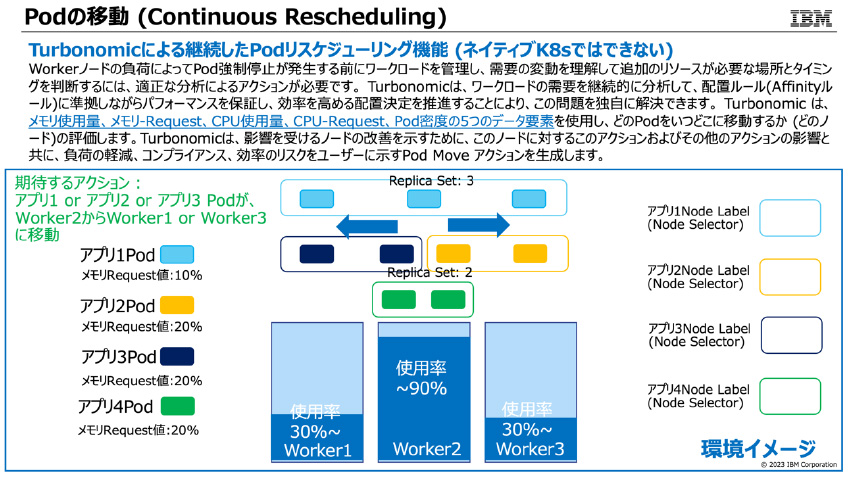
図5:Podの移動(Continuous Pod Rescheduling)とは
*図5の説明:Workerノード間のPod移動を説明します。Worker2Worker1 or 3上でPodイメージがコピーされて、PV上で同じデータを保持してコピー先のWorkerノードでそのPodが”Ready”になった時、ラベルの変更もされてオリジナルWorker2のPodイメージが削除されます。管理者からは、サービス影響無くあたかもPodがWorker2から移動しているように見えます。
2)Workerノードのリソース輻輳(CPU利用率、メモリ利用率が設定したしきい値超えを検知)してから対処
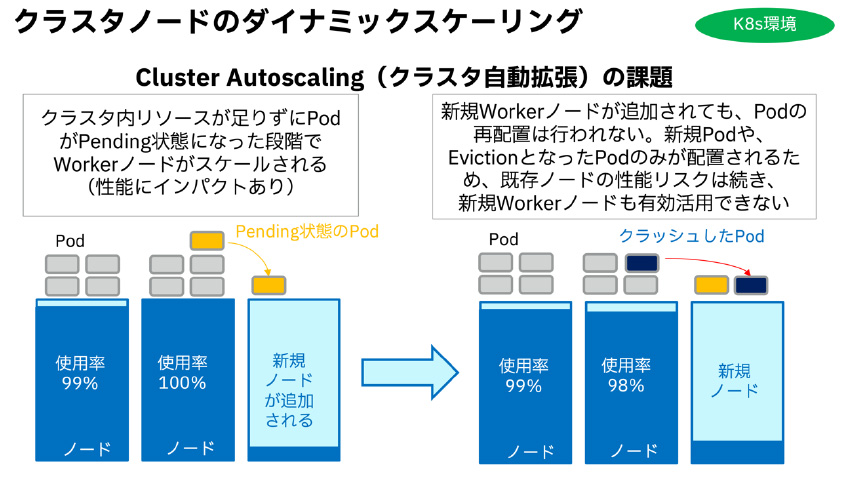
図6:Workerノードクラスタ自動拡張 自己回復のイメージ
5) Workerノードリソースをリアルタイムに管理し、アプリ(Pod)の性能劣化を伴わずに事前対応可能
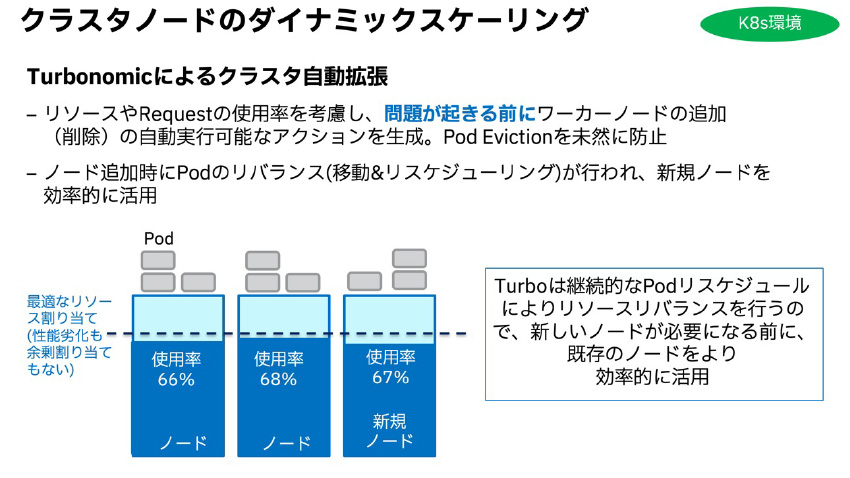
図7:Workerノードクラスタ自動拡張 自己最適化のイメージ
2), 6)コンテナPod実利用に応じた垂直スケーリング、Workerクラスタ内、Namespace間のリソース利用の把握とキャパシティ割り当てリバランスと新規追加Workerノード割り当てシミュレーション

図8:Turbonomicによるクラスタ間リソース容量シミュレーション
*図8説明:事前に設計した静的キャパシティ(Spec Size: リクエスト, リミット)だけではなく、現在稼働しているWorkerクラスタの実リソース利用量(リソース余剰割り当てを考慮した)に基づいてWorkerノード間のPod移行ができます。また、レプリカPodのスケールアップに基づいたWorkerノードクラスタ内のリソース割り当て、Kubernetesクラスタの移行(⇆オンプレミス間、⇆パブリッククラウド間)を、CPU、メモリ、Pod密度の複数メトリックをベース(多次元的)に分析してリソースの最適化が可能になります。
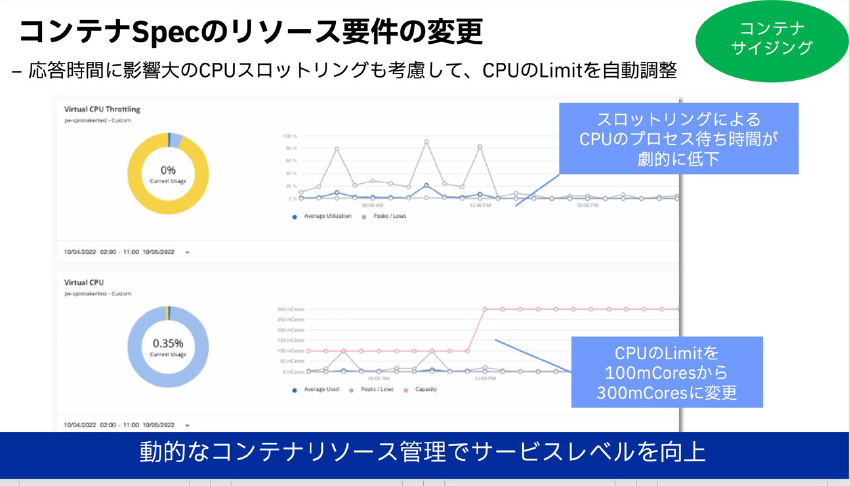
図9:TurbonomicによるコンテナSpecのリソース割り当て最適化
*図9説明:垂直スケーリング、アプリ応答時間に影響を与えるコンテナのCPU輻輳(オーバープロビジョニングに伴う多重利用)問題が解消されます。実リソース利用量、過去の履歴に応じたCPUリミット値割り当ての自動調整が可能になります。
如何でしょうか? Kubernetes標準機能の以下課題
- Pod配置が静的
- 水平自動スケーリングがPod停止を伴う、未然対応ではない
- 名前空間クオータが、実リソース需要に基づいていない
をIBM Turbonomicで改善し、自己回復→自己最適化ができるイメージを持って頂けたと思います。
パートナーNEC様によるKubernetes環境最適化PoCについて
ここで実際に、本観点でKubernetes環境のPoCを実施して頂いたNEC様のPoCをご紹介します。
検証時の環境について、構成は以下になります。
- AWS上Turbonomic管理マネージャの稼働環境:
OpenShift(AWS):Master x 3、Worker x 3上にTurbonomic Operatorにより
Turbonomicを構築
管理対象の環境:
稼働環境のOpenShift(AWS)を管理
- オンプレ上Turbonomic管理マネージャの稼働環境:
Hyper-V (オンプレ): Turbonomic VM x1
管理対象の環境:
Kubernetes(オンプレ):ノード構成(クラスタ1) Master x1, Worker x15、
ノード構成(クラスタ2 ) Master x1, Worker x3
検証シナリオと結果イメージ(NEC様許可を頂いて検証レポートより掲載)

図10:NEC様検証シナリオ概要

図11: NEC様検証実施内容
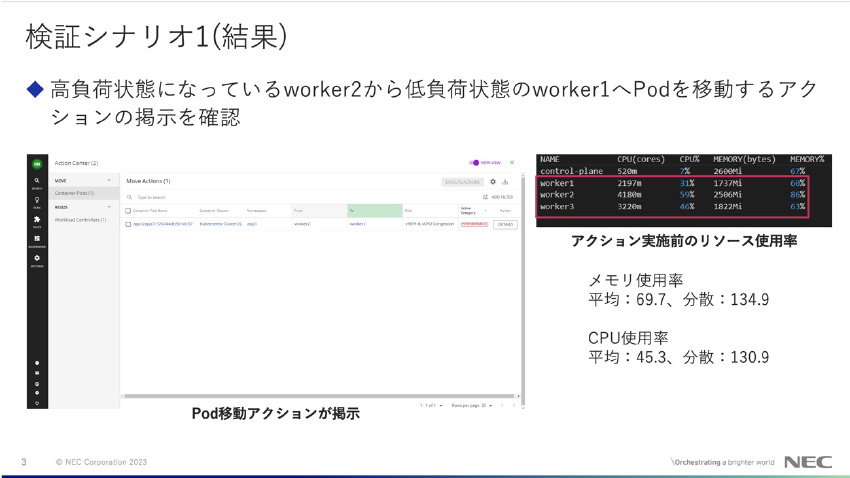
図12: NEC様検証結果1
*図12説明:Turbonomicが提示したPod移動アクションを、ツールより実行して頂きました。(上記画面にて、アクションにチェックを入れて「EXECUTE ACTION」を押す。)
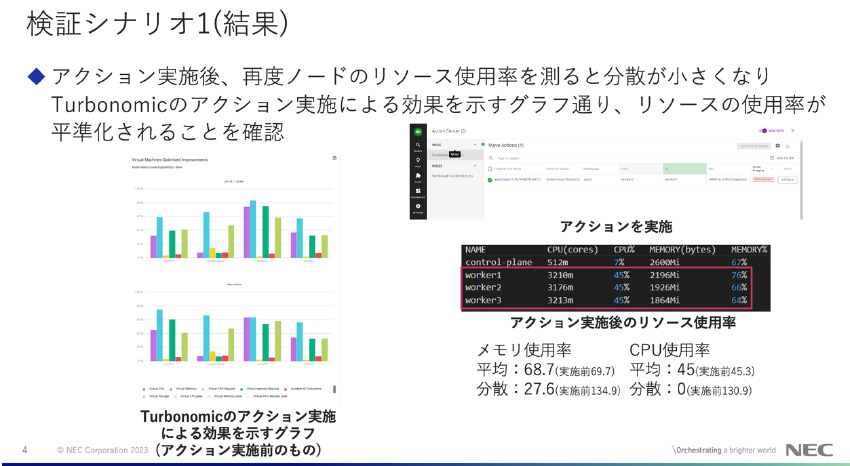
図13: NEC様検証結果2
*図13説明:左下のグラフは、1つのMasterノード、3つのWorkerノードのITリソース(vCPU、vMem、vStorage、Pod数)を表しています。上:アクション前、下:アクション後のノードのリソース変化を表示しており、下グラフの方がリソース平準化しているのが分かります。
NEC様による検証された上で特に実感頂いたメリットなど
KubernetesにはないTurbonomicのリソース平準化機能が、今回の検証を通して一番メリットだと実感することができました。
近い機能として存在するKubernetesのDeschedulerとは違い設定等は最小限ですみ、Turbonomicが自動で高負荷状態に近づいたノードからPodをそうでないノードに移動することで、KubernetesのOOM Killが起きる前に未然に予防することができるのは、Kubernetesの運用者としてありがたい機能だと感じました。
また、TurbonomicがPodの移動やコンテナに割り当てるリソースのリサイズ、ノードの起動・停止などを自動で判断してくれる点は、対応が必要になった時のみ対象のコンテナについてどう対処するかを考えれば良いため、ノード数・Pod数が多い環境において運用効率化が期待できると検証時に実感しました。
(NEC佐藤様コメント)
“可観測性と分析/継続的な最適化”、IBM InstanaとTurbonomicの連携 による更なる先進的な管理手法事例
可観測性によるユーザ体感、目に見えるサービス影響を可視化してサービス(アプリケーション)とそれを稼働しているITインフラリソースの相関を把握したサービスレベル(SLO)管理手法が Kubernetes環境には有効で、多数の実績があります。
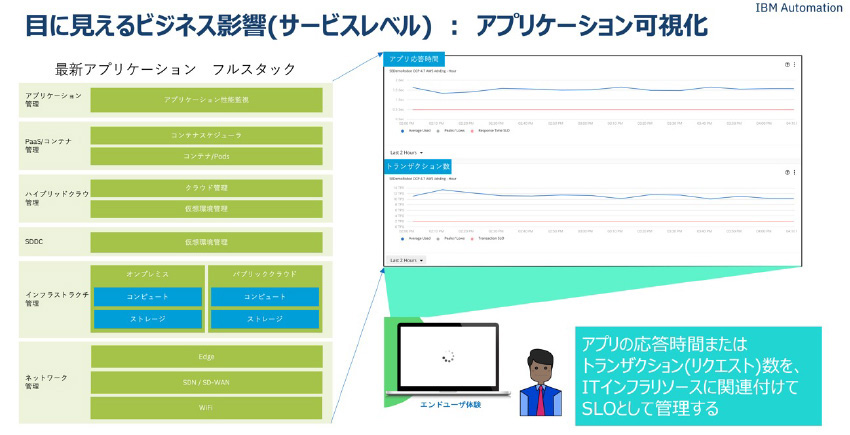
図14:ビジネス影響(サービスレベル)の可視化イメージ
今まで紹介した内容を組み合わせて、サービスレベル(SLO)を管理したKubernetes環境、継続したITリソースの最適化(CO)運用の更なるメリットを紹介致します。
本SLO管理とITリソース最適化ユースケース例では、可観測性はInstana, 継続的な最適化はIBM Turbonomicのツール連携で実現しています。
*可観測性ツールとして、IBM Turbonomicと連携する可観測性ツールはInstanaに限らず多数の3rd Partyツールが利用できます。
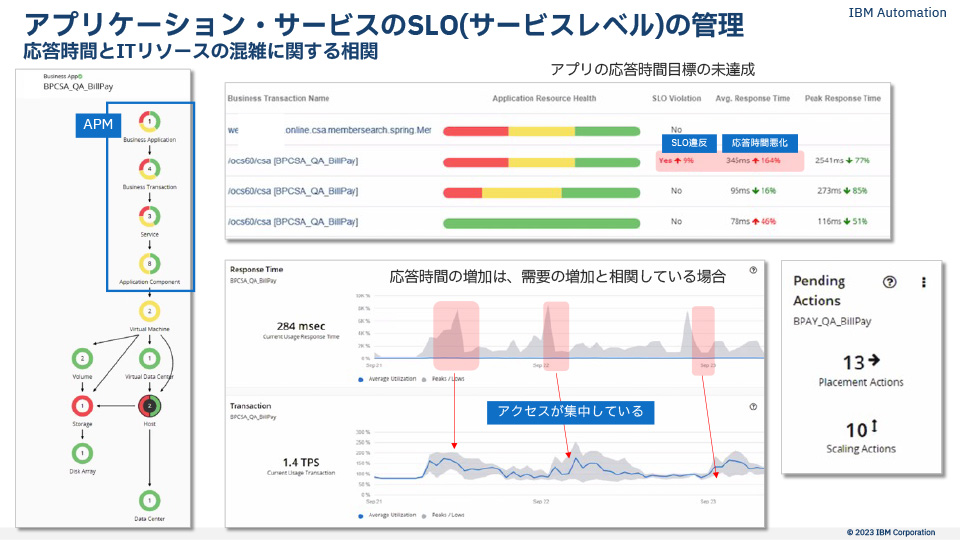
図15:Instana-Turbonomicによる可観測性と分析/継続的な最適化イメージ
すでにInstanaを導入して可観測性観点での監視機能をKubernets環境に提供しています。Instanaは、APMとしてサービスレベルに関する品質情報(アプリ応答時間やトランザクション数)、ゴールデンシグナルと呼ばれる各種アプリ性能、サービス基盤の構成情報を取得してTurbonomicと情報連携をします。*Turbonomicに、InstanaとのAPI連携設定(Instana管理マネージャのIP/ホスト名)を登録する1ステップのみの手順です。)Turbonomicは、Instanaからアプリケーションサービス構成、Javaヒープサイズ等の詳細情報を取得してTurbonomicが保持しているインフラを中心とした構成情報との相関を分析します。その結果、アプリケーション構成とITインフラリソースを自動で関連づけリソースマップを構成します。また、そのアプリケーション応答時間、トランザクション(リクエスト)数をInstanaからアプリ性能として取得して、SLOとして可視化・管理ができるようになります。
Turbonomicは、そのアプリケーション応答時間とトランザクション数をSLOしきい値として監視をし、アプリケーション応答時間がSLOしきい値(例えば2秒)を超過した場合、サービスレベルを保持するためにKubernetesのPodのHPA(水平Pod自動スケーリング)によりPodレプリカを追加したり、必要があればそのPodを展開するWorkerノードVMの追加起動をしたりします。
また、前段で紹介したPod移動によるリソースのリバランスアクションも生成してサービスレベルを維持するように働きます。*逆にITリソースが余剰の場合には、Podを減らすアクションを生成します。具体的なイメージは、次のようになります。
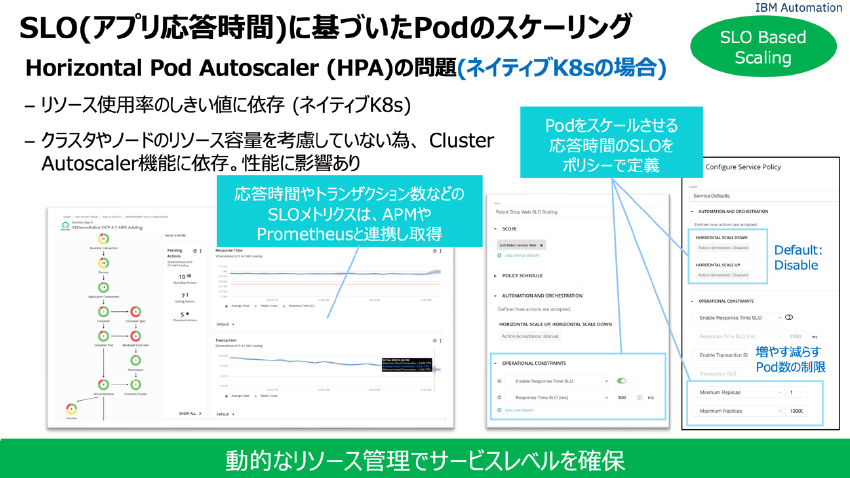
図16:SLO(アプリケーション応答時間/トランザクション数)に基づいた水平Podスケーリングの課題と、Turbonomic設定パラメータ
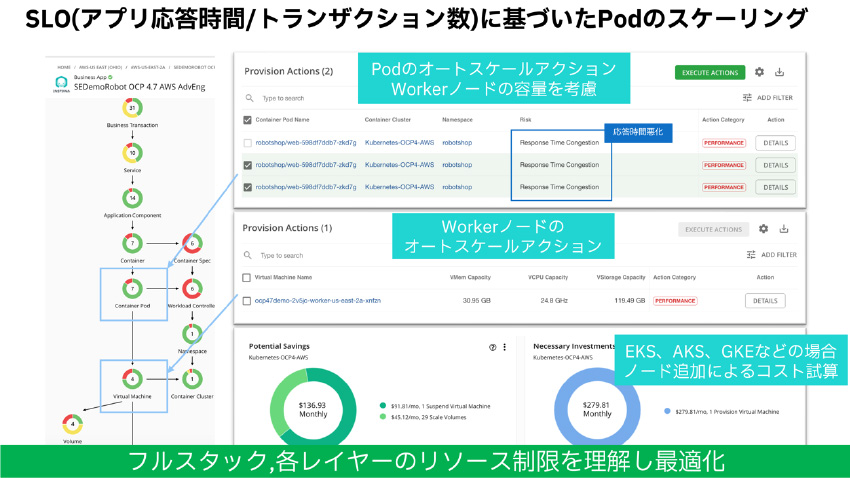
図17:SLO(アプリケーション応答時間/トランザクション数)に基づいたPodスケーリング、最適化イメージ
*図17説明:SLO(アプリ応答時間、トランザクション数)に応じたPodの水平自動スケリングの自動化ができるのは、IBM TurbonomicとInstana連携のみ提供している機能になります。
最後に
改めて、継続した最適化(CO)、さらに可観測性(Observability)と融合した“可観測性と分析/継続的な最適化”の管理手法、メリットのイメージを持って頂けましたでしょうか?
この“可観測性と分析/継続的な最適化”を体験できるIBM InstanaとTurbonomicの連携デモ・サンドボックス環境は以下URLからどなたでもアクセスする事ができます。
少しでも興味を持って頂いた方は、ぜひこの契機に触って体験頂ければ幸いです。
【参考リンク】

佐藤 功一
日本電気株式会社
プラットフォーム・テクノロジーサービス事業部門
テクノロジーサービスソフトウェア統括部
エッジマネジメントSWグループ
2020年NEC入社。コンテナ・クラウド技術を活用したSW製品の開発を経験。高校~大学ではロボットを製作し、特にロボットへ搭載するプログラムの作成・改良に注力。その経験を活かせるよう現在はエッジ向けのSW開発に向けて調査およびデモ作成に奮闘中。

笹原 修一
日本アイ・ビー・エム株式会社
テクノロジー事業本部
データ・AI・オートメーション事業部
Turbonomic・テクニカル・セールス
2022年より現職。インフラストラクチャ・NWデプロイメントエンジニアからキャリアをスタート。NWベンダー、DCプラットフォームベンダーでプリセールスアーキテクト、DevOpsソリューションベンダーにてシステム管理ツールの製品コンサルタントをしておりました。Turbonomicテクニカルセールスとして、Turbonomicの価値を日本に普及するべき、日々邁進しております。

中島 洋平
日本アイ・ビー・エム株式会社
テクノロジー事業本部
データ・AI・オートメーション事業部
Turbonomic・テクニカル・セールス
2022年より現職。これまで20年以上に渡り、外資系ITベンダーにてポスト・プリセールスエンジニアとして従事。主にお客様の重要なデータを管理するHW・ソフトウェア製品を中心に、ソリューション提案からトレーニング、トラブルシューティングまで、製品活用に関わるあらゆるシーンに携わる。現在はTurbonomicの専属のテクニカル・セールスとして、ITリソースの自動最適化の有用性を広めるべく、日々活動しております。

「みんなみんなみんな、咲け」ローランズ代表 福寿満希さん 講演&トークセッション(前編)[PwDA+クロス11]
IBM Partner Ecosystem
日本IBMは、毎年12月初旬の障害者基本法による障害者週間に重ねて、「PwDA+ウィーク」を開催しています(「PwDA+」は「People with Diverse Abilities Plus Ally(多様な能力を持 ...続きを読む

新しい社会経済の在り方を考え、真の社会課題解決を実現するビジネス構築ワークショップ
IBM Partner Ecosystem
「あらゆるビジネスは、なんらかの課題を解決するために存在している」——。誰しも一度くらい、この言葉を聞いたことがあるだろう。 だが一切の留保なしで、この言葉を掛け値なしに信じることができる人は、一体どれくらいいるだろうか ...続きを読む

「第2回ベジロジサミット」レポート後編 | ベジロジシステム討論会
IBM Partner Ecosystem, IBM Sustainability Software
ベジロジ倉庫とベジロジトラック、そしてキャベツ食べ比べを中心にご紹介した「第2回ベジロジサミット」レポート前編に続き、ここからは第二部、場所を屋内に移して開催されたベジロジシステム討論会の様子をご紹介します。 目次 前編 ...続きを読む