IBM Cloud Blog
第18回『自動車業界におけるクラウドネイティブ技術の活用例』
2022年10月31日
カテゴリー IBM Cloud Blog | IBM Cloud News | IBM Partner Ecosystem
記事をシェアする:
こんにちは。クラウド・テクニカルセールスを担当している坂田です。
自動車業界は今100年に一度の変革期にあるといわれています。このなかでクラウドの技術をどう活用していくかというテーマで話を進めていきます。
自動車業界の動向
100年に1度の変革期にあるといわれる自動車業界ではCASEという新しい領域でのサービス技術開発が急速に進められています。CASEとは4つの英語の頭文字をつなげた造語です。それぞれ「Connected(繋がる車)」、「Autonomous(自動運転)」、「Shared & Service(共有)」、「Electric(電動化:電気自動車)」を指します。
「Connected」は車に通信機器を搭載して常時インターネットに接続するもので「Autonomous(自動運転)」「Shared & Service(共有)」の前提になるものです。
「Shared & Service」の言葉が示すように車がステータスシンボルでなく移動する手段として捉えられるようになり所有から共有へと価値が変化していくとともに、自動車メーカーもモビリティサービスのプロバイダーへの変身を目指します。そこでは個人にクルマを販売するということから、移動全般のシステムをサービスとして販売するという方向にシフトしていく、価値の源泉は、もはや製品・ハードウエア・技術ではなくなり、これらを組み合わせてどんなサービスやユーザー体験を提供できるかに移っていくのです。
業界の潮流を示すもう一つのWordとしてSDV(Software Defined Vehicle)があります。サーバー、ネットワーク、ストレージなどを仮想化技術で抽象化してコンピュータリソースをソフトウェアで管理する「Software Defined」という概念は、ITの世界では広く認知されています。近年、自動車開発においてソフトウェア開発が占める領域が目立って増えてきたころから、自動車においても「Software Defined」という言葉が使われるようになりました。ここではSDVの特徴を3つ挙げます。
まず、これまで車にはECU(Electric Control Unit)が100個以上搭載されソフトウェアは各々のchipに組み込まれていましたが、このソフトウェアをハードウェアから切り離します。つまり、車両の物理的な安全性・耐久性を担保するハードウェアの領域と、クルマの機能・特徴を定義付ける様々なサービスを実装するソフトウェアの領域が切り離されます。
二番目に情報システムと常時つながっているコネクテッドが当たり前となり、OTA(Over-the-air:無線通信)によるソフトウェアアップデート技術が普及すると、携帯電話のように、ユーザーがクルマをアップグレードすることができるようになります。SDVでは、クルマを買い替えなくても、OTA (Over-The-Air)により、常に最新機能を装備したクルマを利用できます。
三番目の重要な特徴はSDVはクラウドと連携するコネクテッドが前提になっている点です。クラウドだからこそ提供できる膨大なコンピューティング・リソースを活用しながらクルマ単体では実現できなかった多様な機能を実現できるようになります。過去携帯電話が計算能力/メモリの制限で限られた機能やサービスしか利用できなかったものが常時インターネットに接続することでクラウドの無尽蔵なリソースを利用できるようになりスマホへと大きく進化を遂げたのと同様です。
クルマとクラウドが商品として一体化しソフトウェアで機能や特徴が決まるクルマです。繋がる車がSDVになる時代は機能サービスが柔軟かつ頻繁にアップグレードでき、車とクラウドがリアルタイムに連携・一体化されます。まさにイノベーションを運ぶ車です。
EV (Electric Vehicle)メーカーのTeslaはSDV/OTAの対応では先頭を走るメーカーの一つです。
FSD (Full Self Driving: EVのSoftware)をサブスクリプション契約することで,そのソフトウェアはOTA アップグレードされるようになります。現時点では完全な自動運転には対応していないですが毎月・サブスクリプション分の金額を支払えば機能がどんどんアップグレードされて、自動運転もできるようになります。車を買い替えなくてもディーラーにいかなくてもいつの間にか自分の車が自動運転対応しているというものです。またTeslaの車ではクリスマスシーズンになるとメーター&ディスプレイ内の自分の車がサンタのソリになり雪の降る道を疾走し、センサーで検知した他車が白いトナカイとして表示され、ウィンカーを出したときの音はジングルベル(鈴)の音に変わるサンタモードを楽しめます。SDV時代に提供する新しいクルマの価値について大変参考になるものです。
システム要件
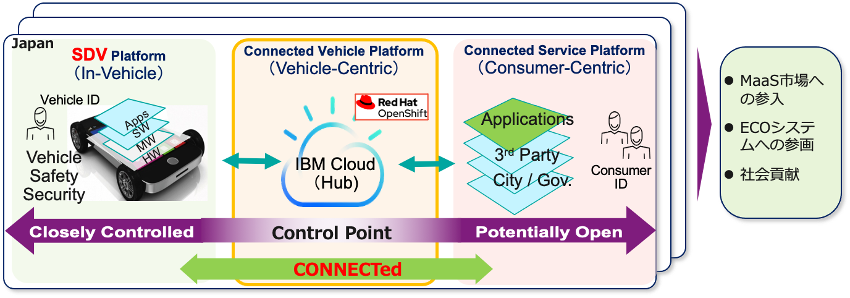
上記で書いたようにクルマがSDVになり繋がる時代はクルマとクラウドが一体化するのでクラウドネイティブの対象スコープも車にまで拡がります。アプリケーションのポータビリティはマルチクラウド、ハイブリッドクラウドだけでなく車にまで拡がり、他のコンシューマー向けサービスと同様にスケーラブルでかつ市場ニーズへの迅速な対応が求められます。クラウドネイティブの技術要素であるコンテナ、オーケストレーション、マイクロサービス、DevOps等が車載ソフトウェアでも利用される可能性が出てきました。

車ではこれまで組み込み型ソフトウェアを利用しておりハードウェアに緊密に連携されていましたが(ソフトウェアはその特定のハードウェアでしか動かない)近年ハードウェア抽象化レイヤー(Hardware Abstraction Layer)の導入によりソフトウェアがアプリとして緩やかに連結できるようになりました。またLinuxベースのGPOS (汎用OS)も利用され始め車載ソフトウェアのポータビリティは一層高まっています。車内の機能ブロック/ECUの統合が進めば、異なる車種や世代でコードを再利用でき、この動きはますます加速するでしょう。
今でも車が「Connected」により繋がることにより、より高いリアルタイム性、安全性が求められない (通知、運転者補助系)サービスはクラウドで処理することも可能になっています。ここでは私が関わったプロジェクトから2つのエリアにフォーカスして話していきます。
1.ビッグデータ基盤について
Connected Vehicle (繋がる車)の主要な機能は繋がる車から大量データ(車両走行状況等)を収集し、地図や天気、その他外部ソースからのデータと統合、ビッグデータ解析を実施した結果、知見を抽出し新たな価値、サービスを提供するものです。具体的には車の走行状況及び天気や交通情報などをクラウド上で収集・分析し、道路ネットワーク情報に基づく位置情報サービスや運転者補助サービスを提供するものです。
このビッグデータ基盤に関していうと車の台数の増加、収集データ量の増大に伴いスケーラブルで、コスト効率が良く、高いパフォーマンスのストレージおよび、ビッグデータアクセス/分析の仕組みが求められます。
2.DevOps開発基盤について
OTAにより車へのソフトウェア配布が速くなると、ソフトウェア開発プロセス自体の短縮/高速化が求められます。クラウドネイティブの世界では開発ワークフローと導入オペレーションが結合されているDevOpsがベストプラクティスとして利用されます。DevOpsでは開発/導入の一元化や、アプリケーションの継続的な改善を実現することが可能です。
継続的なプロセスであり、デプロイメント内のコンテナの運用をモニタリングした結果が次の開発サイクルに活用されます。
こうして、実行されるソフトウェアの質は継続的に改善されます。時間が経つにつれ、この プロセスが全体のクオリティを高めるとともに、製品開発期間の短縮とコスト削減に貢献し ます。
将来的にはOTAと連携して車へのソフトウェアアップグレードにも活用することでサイバーセキュリティや、OTAによるバグ修正、機能的なソフトウェア・アップデート、自動車の製品寿命全体にわたって車載ソフトウェアを管理する上で、重要な役割を果たしていくものになるでしょう。
ビッグデータ (データレイク)アクセス基盤
ビッグデータ (データレイク)アクセス基盤としてIBM CloudサービスであるData Engineを活用します。
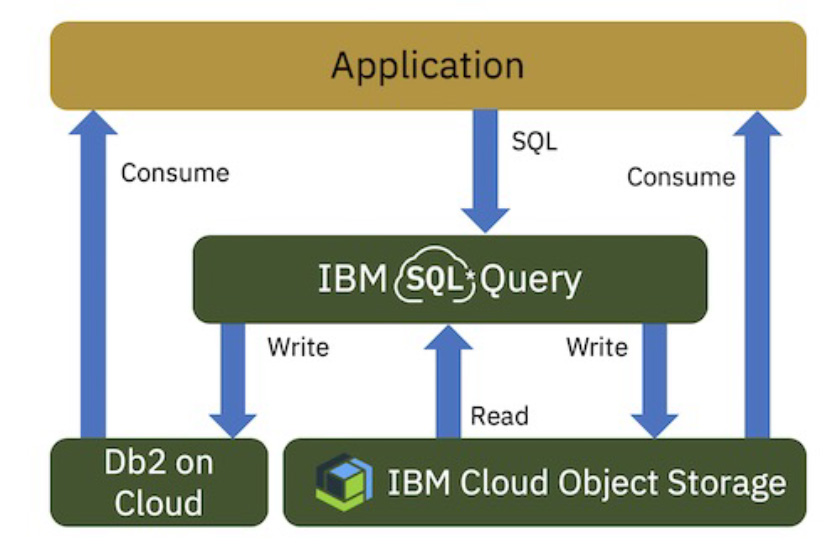
IBM Cloud Data Engine (旧称:SQL Query)はICOS (IBM Cloud Object Storage)上のファイルをサーバレスでANSI標準の SQLにより検索、変換するサービスです、通常結果はICOS に保管されますがDB2テーブルへ出力することも可能になっています。スキャン量に応じて課金されParquetファイルを利用することでリーズナブルな価格で利用できます。オブジェクト・ファイルへの事前のスキーマ定義も不要です。ユーザーからのアクセス・インターフェースとしてはSQL文が直接入力可能なWebコンソール、CLI/APIコマンド、クライアントSDK(Python, Node.js, Java等)が提供されます。
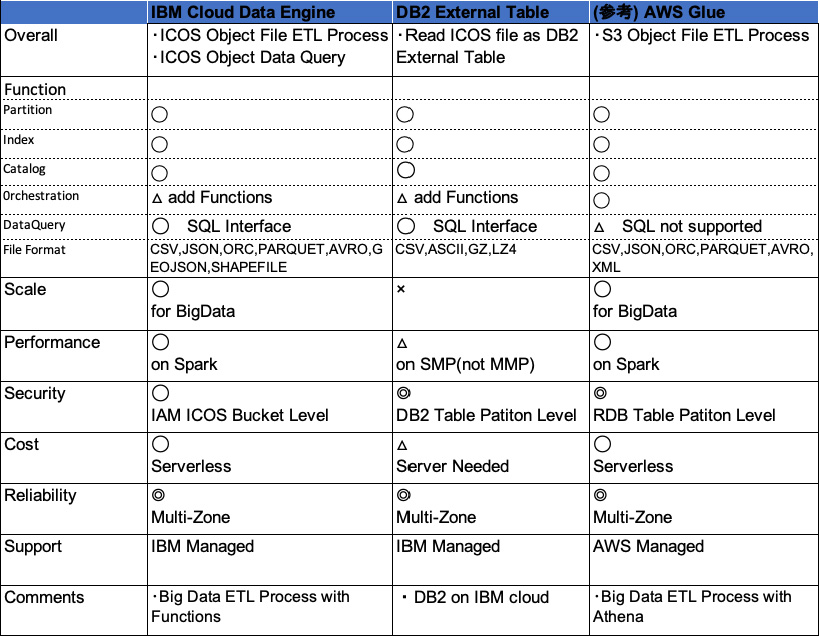
類似サービスの比較検討表をつけました、DB2の外部表の機能によりICOS Fileも扱えますがペタバイト級のビッグデータには不向き、ビッグデータの並列処理と相性の良いParquet Data Formatのサポートは現時点ありません。Data EngineはAWSでいうとGlue/Athenaに相当しますがここではより大規模処理向きのGlueを取り上げました。
ビッグデータ (データレイク)ソリューション
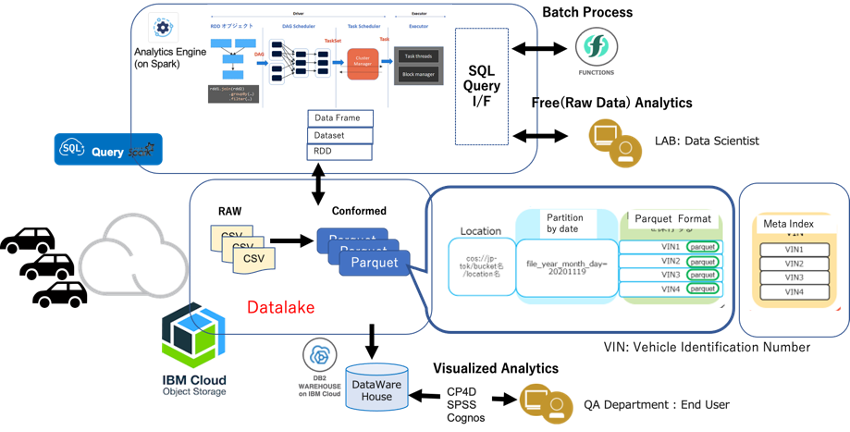
車両からCSVファイルがIBM Cloudに送られてきてICOSに保管/蓄積されます。どんどん溜まっていきデータレイク状態になるのでこれをFunctions (サーバレスなイベント駆動型のFaaS: AWSのLambdaに相当)により起動されたData EngineジョブでETL処理(データ整形加工)をしてDWH(Data Warehouse)を構築します。当職の知るプロジェクトでは50以上のジョブを夜間バッチで同時並行に走らせています。Data Engineは内部ではSpark/SQLが稼働しておりDAG (Directed Acyclic Graph) によるジョブのStage/Taskの最適化、Catalyst Optimizerの最適プランへの書き換えなどインメモリー型の分散処理テクノロジーが利用されます。またICOS上のFileはSparkやビッグデータと相性の良いParquetで管理されておりColumnar フォーマットなのでスペース保管効率もよく、IO数も少なくて済むのでパフォーマンスに優れます。CSVに比べて実際5,6%近くまで保管スペースが少なくて済みました。ICOS上のデータはHive Style(後述)でパーティション化されてBacket直下に階層管理されています。また車両に一意に振られるVID(Vehicle Identification Number)でメタインデックスが張られます。ICOS上のデータと言って決してカオス状態ではなくパーティション化/ インデックス付与/カタログが作成されておりユーザーからは容易にアクセスできるようになっています。ユーザーはこれをData Queryにより直接参照する、または必要なデータをDB2に抽出してデータマートを作成してからCognos/SPSSを利用してビジュアライズな検索、データモデリングを実施しています。
ここでは実際のイメージを摑んでいただくために
データレイク基盤で利用されたData QueryのサンプルSQL文を紹介します。
SELECT * FROM cos://jp-tok/raw-data/*.csv INTO cos://jp-tok/conform-data/ stored as PARQUET PARTITIONED BY (date)
FROM,INTO節は入力,出力となるICOS上のファイル名を指定します。
Rawデータの複数CSVファイルをParquet形式に変換するとともに、日付の列(date)でパーティション化します。具体的にはICOSのBucket
cos://jp-tok/conform-data/
配下に、同じdateの値をもつ行をまとめてdate=yymmddという名前で同じObject として出力します。(Hive Style) partition化することで日付で条件指定した後続の検索処理の際に不要なファイルのスキャンを回避して必要なデータのみ抽出されコストが抑えられるとともに性能が向上します。下記に詳細な説明をつけましたので参考ください。
cos://<エンド・ポイント>/<バケット>/[<プリフィックス>] [stored as フォーマット]
エンド・ポイント – 使用するICOSのバケットのエンドポイント名
例:s3.jp-tok.cloud-object-storage.appdomain.cloud
バケット – ICOSで作成したバケット名
プリフィックス – 出力先の1オブジェクト、または宛先が複数(区分化)になる場合にはその接頭句
フォーマット – サポートされるCSV, JSON,PARQUET,AVRO等,デフォルトはCSV
PARTITIONED BY (フィールド名) – 一つ以上のフィールド名を指定し、同じ値を持った行をまとめて同じオブジェクトに出力
DevOps基盤
DevOps(開発)基盤はIBM CloudサービスであるContinuous Deliveryを活用して構築します。
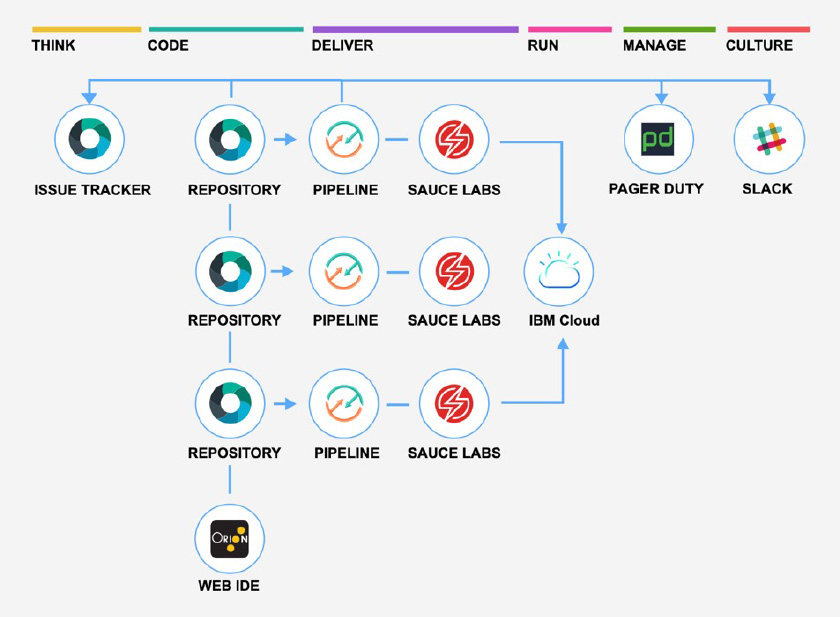
GitやパイプラインなどCI/CD機能をManaged Serviceとして提供するものです,
DevOpsツールチェーンを作成することで、Gitリポジトリー(GitLabベースのManaged Service), ICR (IBM Cloud Container Registry)その他OSSツールを取り込み、開発、デプロイメント、操作のタスクをサポートするツール統合が可能になります。反復可能で管理しやすい開発と操作を実現します、Delivery Pipelineではクラッシック・タイプとTektonタイプの2種類から選択できます。最終的にビルド、単体テスト、デプロイメントなどを自動化可能です。
DevOpsソリューション
クラウドアプリケーション開発に必要なDevSecOps環境をIBM Cloud Continuous Delivery上に構築し、ソースコード管理からビルド、単体テスト、コンテナイメージ作成、統合テストの自動化を実現しました。クラウドを活用したので短期間で開発環境を構築できました。 Tool Chainでは各種OSS Toolが利用されています。
コードの品質チェツクをするSonarQube, Browserアクセステストを実施するSeleniumを取り込んでいます。DevSecOpsのSecurity面ではBuildしたイメージのPushの際ICRの脆弱性Checkが実施されるとともに,Toolchainの最後のステージでOWASPのZAPテストを実施して、セキュリティを向上させています。自動化により生産性向上するのはもちろんですが、ヒューマン・エラーの削除によりアプリの品質が向上しています。この結果、プロジェクトメンバーからは”ビルド/デプロイの作業時間が短縮され、1日当たりのデプロイ回数が大幅に増加した” “自動打鍵によるテスト実施が可能になり工数を削減できた”という声も聞かれました。
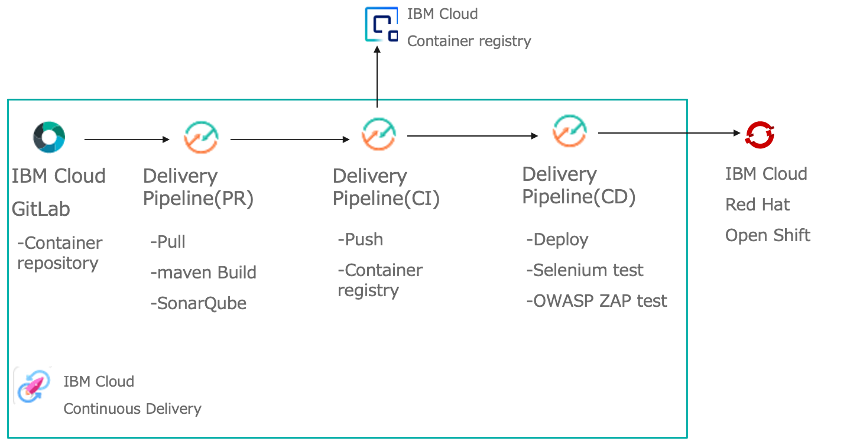
ここでは実際のイメージを摑んでいただくためにDevOpsPipeLine構築で利用されたContinuous Delivery設定画面を紹介します。
IBM Tool ChainのDelivery Pipelineの画面になります。Build/Deploy/TestのPhase毎に定義していきます。これはDockerイメージをBuildし、ICRにPushするフェーズを定義する画面です。左から順番に入力,ジョブ,環境プロパティのタブを表しています。
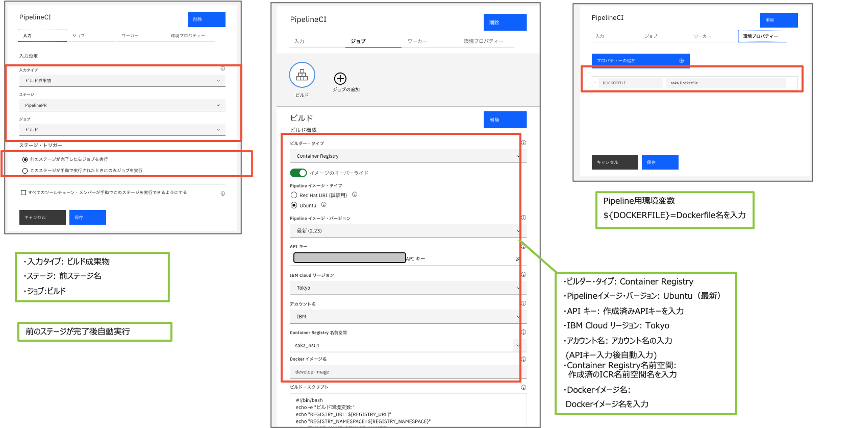
入力
起動条件を指定します、前フェーズが完了したら起動されます
ジョブ
Registry名,Dockerイメージ名等を入力します、
ICR利用の場合はRegion/名前空間も指定
環境プロパティ
ここではDockerFile名を入力します。
最後に 〜 将来図
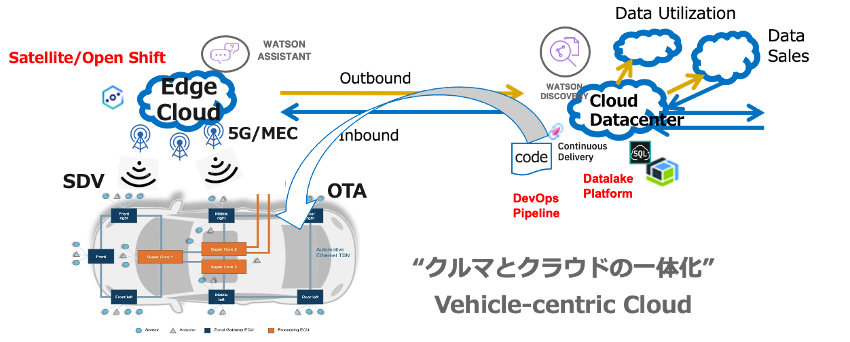
5G/MECの通信機器が設置されたエッジクラウド (通常のクラウド・データセンターより小規模だが拠点数は多い)にIBM Cloud Satelliteを導入すれば、データの発生元となる車からより近いところでデータ分析サービス(Watsonなど)を利用することもできます。車とクラウドが文字通り一体化する日も、そう遠くない将来に訪れることでしょう。
<参考資料>

坂田 直紀
日本アイ・ビー・エム株式会社
テクノロジー事業本部
クラウドプラットフォーム・テクニカルセールス
シニア・アーキテクト
IBM 入社以来製造、製造/金融のお客様担当の SE として多くのプロジェクトに参画、 インフラ IT アーキテクトとしてシステム基盤更改、インフラ最適化等の提案/計画立案/構築に従事、2012年よりCloud に特化した IT Architect として Cloud 移行に関わ る提案/ソリューショニング活動をリード、これまで培った Infra/Cloud IT Skill を 生かした CRM 活動全般にあたり、お客様システムの Cloud 化推進を支援する。

ラウンドテーブルを通じてPwDA+Week2024を振り返る(後編) | インサイド・PwDA+9
IBM Partner Ecosystem
日本IBMグループのダイバーシティー&インクルージョン(D&I)活動の特徴の1つに、当事者ならびにその支援者であるアライが、自発的なコミュニティーを推進していることが挙げられます。 そしてD&Iフ ...続きを読む

ラウンドテーブルを通じてPwDA+Week2024を振り返る(前編) | インサイド・PwDA+9
IBM Partner Ecosystem
日本IBMグループのダイバーシティー&インクルージョン(D&I)活動の特徴の1つに、当事者ならびにその支援者であるアライが、自発的なコミュニティーを推進していることが挙げられます。 そしてD&Iフ ...続きを読む

風は西から——地域から日本を元気に。(「ビジア小倉」グランドオープン・レポート)
IBM Consulting, IBM Partner Ecosystem
福岡県北九州市のJR小倉駅から徒歩7分、100年の歴史を刻む日本でも有数の人気商店街「旦過市場」からもすぐという好立地にグランドオープンしたBIZIA KOKURA(ビジア小倉)。 そのグランドオープン式典が2024年1 ...続きを読む