IBM Cloud Blog
第15回 可観測性?Observabilityって?
2022年07月15日
カテゴリー IBM Cloud Blog | IBM Partner Ecosystem
記事をシェアする:
こんにちは。日本アイ・ビー・エム AIOpsエバンジェリストの岩品です。
今回のブログでは、最近耳にすることが多くなった可観測性(Observability)についてお話ししたいと思います。
可観測性(Observability)と監視(Monitoring)
可観測性(Observability)とはなんでしょうか?従来のモニタリングとはなにが違うのでしょうか?
これまでの監視(モニタリング)は、基盤的な観点が中心でした。プロセス監視やCPUやメモリーのメトリック監視。そして閾値で監視を行い、アラートがあがり、問題があったあとに対応を行う。対応は事後的で、Passive 受身的な アプローチでした。
基盤的なレイヤーだけでなく、アプリケーションにまで踏み込んだ監視を行うのがAPM(Application Performance Management)の世界です。提供するアプリケーションの応答性能やエラー数、スループットなど、ゴールデンシグナルを中心に、サービスの提供状況を理解するアプローチです。
可観測性(Observability)は、これらモニタリングやAPMのアプローチをベースとして、システムの複数層のデータをリアルタイムで解析し、複雑化したシステムにおいて 問題点を「積極的に」理解し、問題状況の把握をおこなうアプローチだと言えます。
これまでの監視が、問題が起きたあと「調べれば分かる」に対して、「いま起きていることをデータに基づいて説明できる、改善できる」状況に持っていくものが 可観測性(Observability)だと考えます。

図1:可観測性と監視
クラウド・ネイティブ開発の中では、エラー・バジェットとサービスレベル管理の考え方が重要になっています。100%のサービスレベルを求めた場合、リスクを伴う新規機能のリリースはできなくなってしまい、ビジネスに貢献しないシステムになってしまいます。一方でシステムに問題が発生した場合には、ユーザー体験が損なわれユーザーの離反にもつながりかねません。
システムの安定性とビジネスの創造性のバランスを採るために、応答性能やエラー率といった 数値化可能なメトリックのサービス・レベル指標(Service Level Indicator)を取得し、具体的に ビジネス・オーナーとサービス・レベル合意(SLA)を定義し管理することが求められています。これらの サービス・レベル指標を可視化するためにも、APM Observabilityは必須のテクノロジーとなっています。
可観測性(Observability)の3つのシグナル
Kubernetesを管理するCNCFの中に可観測性の Technical Advisory Group 専門家のグループ があります。ここが出している可観測性のホワイトペーパーでは、「可観測性とは 外部出力の情報からシステムの内部状態をどれだけうまく推測できるか」だといっています。
マルチクラウド、ハイブリッド・クラウドが進展し、クラウドは責任共有モデルで提供され、システム管理者は 従来持っていたようなシステム全体にわたる管理権限を持ちません。そのような中で、取得できる情報を元にシステムを理解していくことが求められ、可観測性の技術が進展してきました。
ホワイトペーパーでは、可観測性を実現する3つの重要シグナルとして、メトリック、トレース、ログをあげています。
メトリックはこれまで取得してきたような数値で表現できるデータの履歴です。
トレースは、分散トレーシングです。システムに入ってきた要求が 複数のコンポーネントを渡りどのように応答を返すか、各要求のライフサイクルを理解することです
ログは、人間が読める形で表現された発生したイベントの記録です。
ホワイトペーパーでは、さらに2つ、プロファイルとダンプを 有益なシグナルとしてあげています。
プロファイルはこれまでもパフォーマンスのボトルネックを追求するために利用されてきましたが、現在、サンプリング・プロファイラーが普及し、本番環境での取得も現実的になってきたといっています。
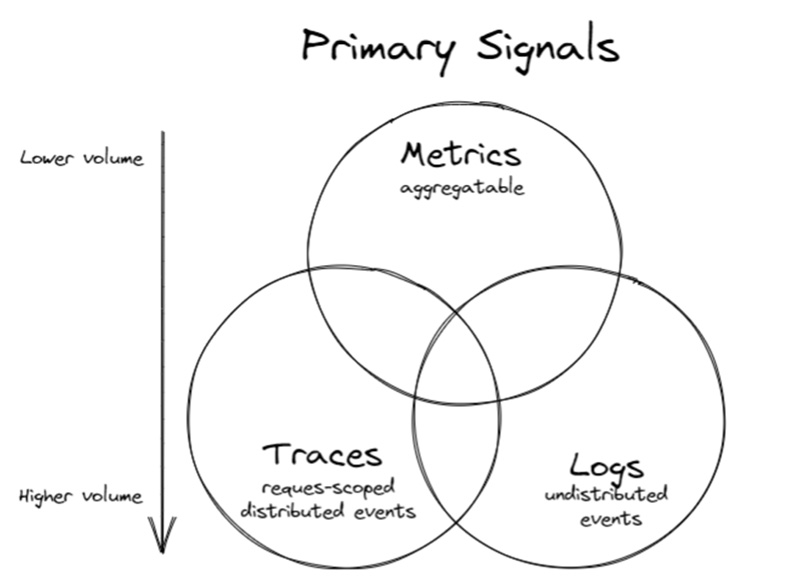
図2:可観測性の主要シグナル(画像引用 https://github.com/cncf/tag-observability/blob/main/whitepaper.md)
可観測性(Observability)を提供する テクノロジー
Kubernetes の領域において Observability を提供するテクノロジーとしては、Prometheus が代表的かと思います。Prometheus で取得した膨大なメトリック・データをグラフィカルに把握するためのツールとして Grafana も非常に人気があります。OpenShift においても OpenShift Monitoring として提供されていますね。マルチクラスター環境でのPrometheusメトリクスを集約する Thanosというテクノロジーもあり、こちらは OpenShift Advanced Cluster Managementで提供されています。
トレーシングは、Zipkinや Jaeger といったテクノロジーの名前がよく上がります。OpenShift でも OpenShift Distributed Tracing として Jaegerを提供しています。
またOpenTracing や OpenCensus というプロジェクトがありましたが、それぞれ個別の開発を終了し、両者が統合された OpenTelemetry というテクノロジーに注目が集まっています。
ログは、FluentdやLogStash といったログ収集のテクノロジーが有名です。アプリケーションのログに加え、アクセス・ログやシステム・ログなども収集し、統合されたダッシュボードで解析可能です。OpenShift においては、OpenShift Logging として EFK (ElasticSearch, Fluentd, Kibana)のスタックが提供されています。
OpenShiftであれば、これらの可観測性技術もOperatorで管理され導入や構成も比較的容易に実施可能です。
一方で、それぞれのオープンソース技術が提供するコンソールが提供されており、問題発生時には 複数のコンソールを行き来しながら問題判別をしないといけません。
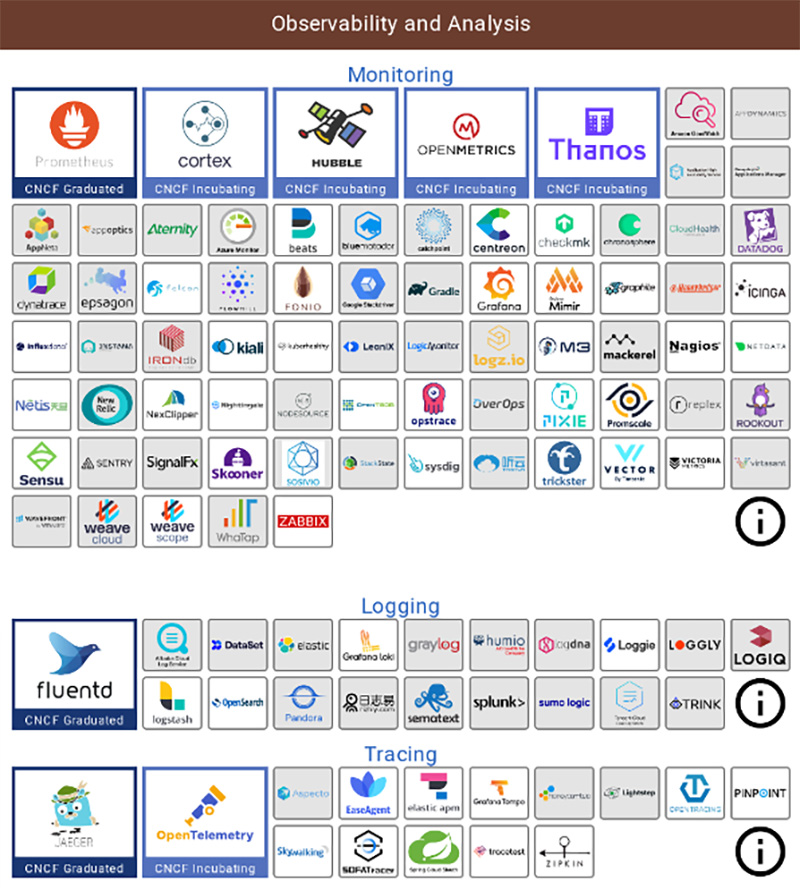
図3:Observabilityを提供するテクノロジー( CNCF LandScape https://landscape.cncf.io/ から抜粋 )
可観測性を自動化しシンプルに提供 IBM Observability by Instana
最後に、Kubernetes/OpenShiftをご利用いただいているお客様にご好評いただいている IBMの可観測性製品 IBM Observability by Instanaについて紹介させてください。
IBM は新進気鋭のベンチャー企業であった Instana を2020年12月買収し、現在はIBM Observability by Instanaとして 提供しています。
Instanaは 可観測性の3つの主要シグナル(メトリック、トレース、ログ)を、1ホストに1つのエージェントで、できる限り自動で取得できるようにする製品です。
Kubernetes の環境であれば、WorkerNode に DaemonSet として Instana エージェントを導入すれば、その環境で稼働する多様なコンテナーのテクノロジーについて 自動的にDiscovery(検知)して、それらに対してセンサーをロードし監視を開始します。各テクノロジーに対応したセンサーには、「通常こういったものを監視するよね」といったメトリックの取得設定や監視設定があらかじめ組み込まれていますので、Out Of Box ですぐに監視を開始できます。Instanaエージェントは、常にノード上のテクノロジーの変化を監視していますので、Kubernetesのような動的な環境でも自動的に追随して監視可能です。
マイクロサービスの呼び出し関係を可視化するための分散トレースは、Instana AutoTrace™️として JavaやPHP、Python、.Netといった言語は、アプリケーション改修不要、サイドカー不要でトレーシング可能です。.Net Core, Node.js, Ruby といった環境も、Kubernetes のAdmission Controller の仕組みと連携することにより(Instana AutoTrace Webhook)、アプリケーション改修不要で 自動的にトレーシングが行えます。Instanaは ランタイムで処理されるすべての要求をトレースし解析しています。これら取得した要求を解析することで、マイクロサービスの呼び出し関係、依存関係を自動的に可視化してくれます。
また、Instanaは 解析した結果、個々のサービスやエンドポイントの スループット(処理数)、エラー率、応答性能 といった ゴールデン・シグナルをダッシュボードで可視化します。これにより、どのアプリケーションのどのサービスに問題が発生しているのかを把握できるようにします。
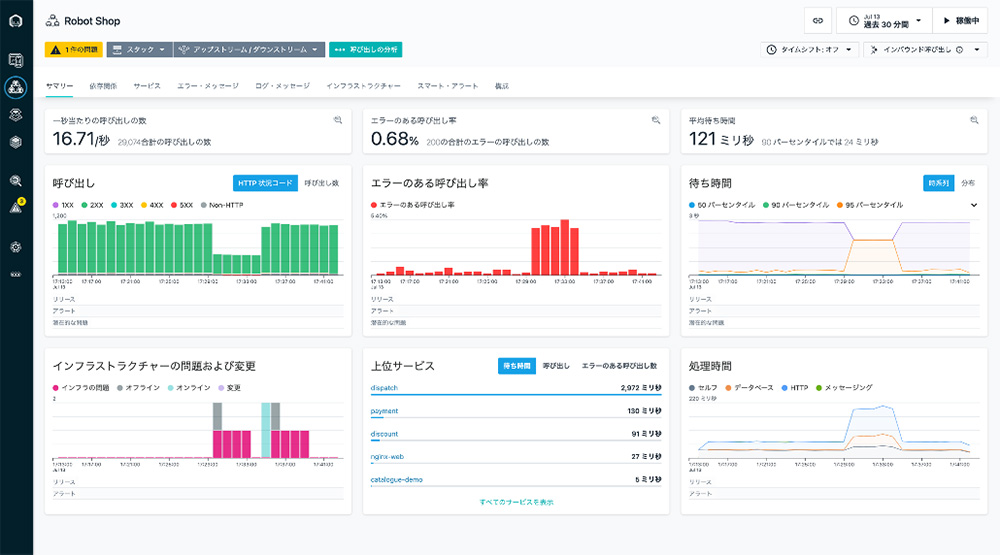
図4: Instanaのゴールデン・シグナルをベースとしたダッシュボード
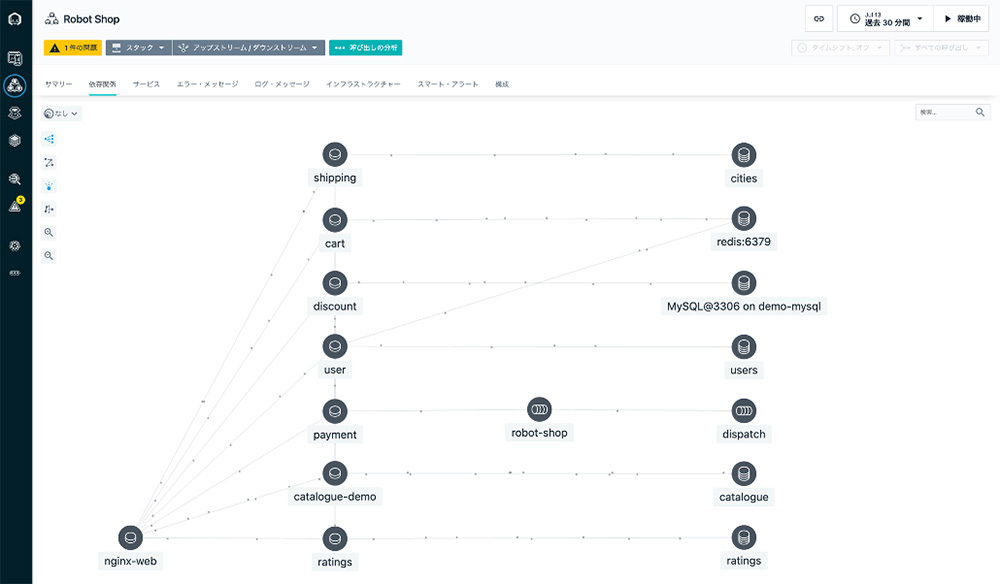
図5: Instanaにより自動で可視化される依存関係ビュー
Instanaは ゴールデンシグナルの変化、たとえば 要求数の急減、急増、エラー数の急増、応答性能の悪化など サービスに影響を与える変化があった場合、さきほどの依存関係マップに 表示します。
各テクノロジーのセンサーが検知した メモリーが枯渇しているとか、ファイルが溢れているとか、接続プールが枯渇しているといった問題も依存関係マップに表示します。これらの異常は、SlackやMS Teams、メール、Webhookなどで 通知連携することが可能です。
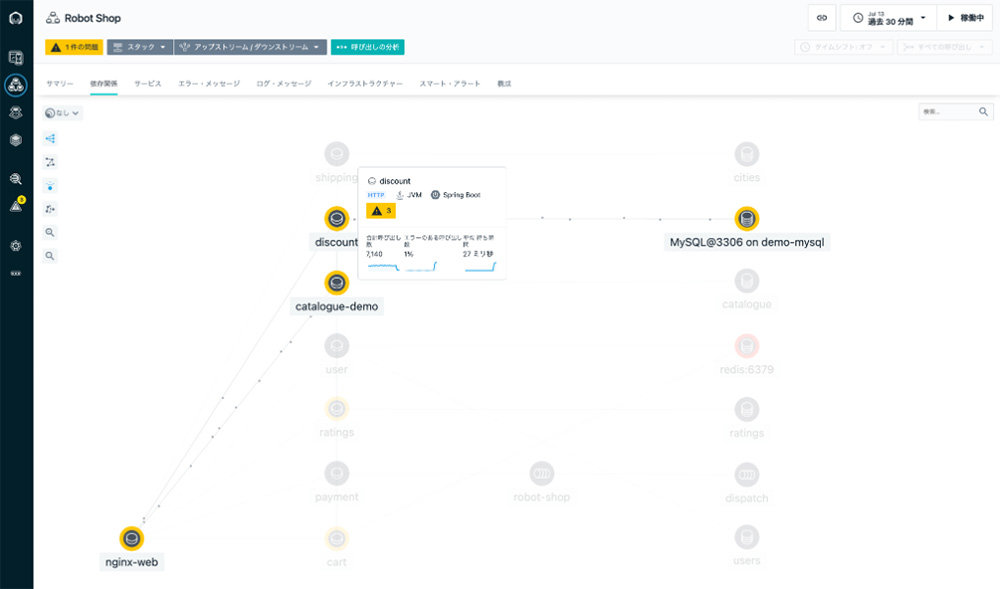
図6: 依存関係にマップされた 問題発生状況
トレースの解析により、一連のシステムの呼び出しのなかで どこのコンポーネントで処理を行っている中でエラーとなったかも自動的に解析してくれます。スタック・トレースからどのクラスの処理でエラーになったか、どんなエラー・メッセージが出ていたかも即座に把握できます。
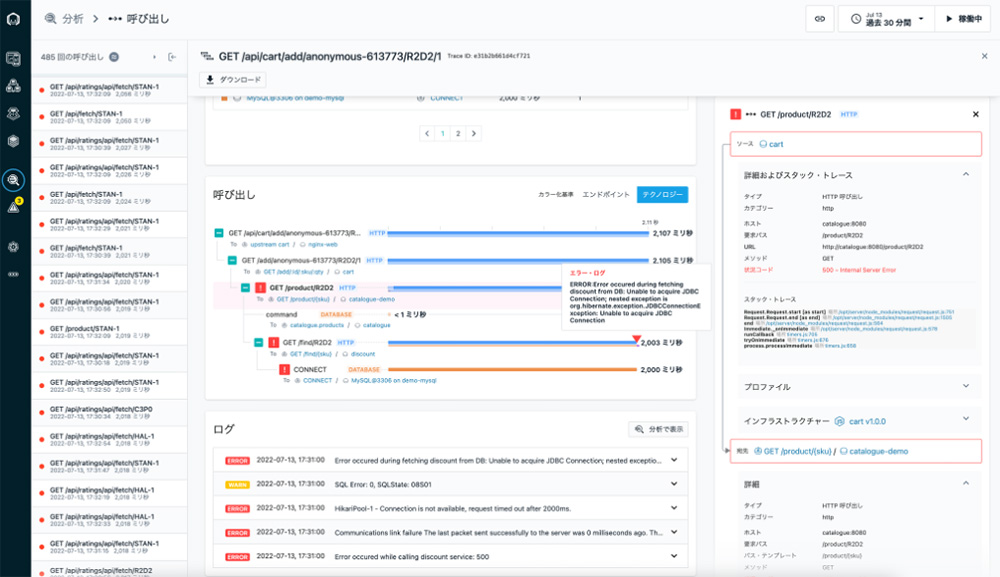
図7: エラー要求が含まれる処理の解析画面
Instana は、市場調査会社の調査でも、実際のユーザーの方からも、市場で高く評価されている製品です。
Instana Named a 2021 Gartner Peer Insights Customers’ Choice for Application Performance Monitoring
こちらの デモ・サイト(英語)で実際に動く環境を自由に触って見ていただけますので、Instana によって システムがどのように見えるのか確認してみてください。あなたのエンジニア・ライフの クオリティを 大きく向上させてくれる技術だと思います。

岩品 友徳
日本アイ・ビー・エム株式会社
テクノロジー事業本部
オートメーション・テクニカル・セールス
AIOpsエバンジェリスト

セキュリティー・ロードマップ
IBM Cloud Blog
統合脅威管理、耐量子暗号化、半導体イノベーションにより、分散されているマルチクラウド環境が保護されます。 2023 安全な基盤モデルを活用した統合脅威管理により、価値の高い資産を保護 2023年には、統合された脅威管理と ...続きを読む

量子ロードマップ
IBM Cloud Blog
コンピューティングの未来はクォンタム・セントリックです。 2023 量子コンピューティングの並列化を導入 2023年は、Qiskit Runtimeに並列化を導入し、量子ワークフローの速度が向上する年になります。 お客様 ...続きを読む

ハイブリッドクラウド・ロードマップ
IBM Cloud Blog
コンポーザブルなアプリケーション、サービス、インフラストラクチャーにより、企業は複数のクラウドにまたがるダイナミックで信頼性の高い仮想コンピューティング環境の作成が可能になり、開発と運用をシンプルに行えるようになります。 ...続きを読む