IBM Cloud Blog
【NTTコミュニケーションズ様との共同実証報告】AI時代のネットワーク運用高度化に向けた取り組み
2024年07月03日
カテゴリー IBM Cloud Blog | オートメーション
記事をシェアする:
システム障害と聞くだけで緊張してしまうのは私だけでしょうか?心理的にも体力的にも負荷が高いこの仕事をAIによって、なんとか楽にならないのか、と誰しもが思っています。そこで、IBMのAIによる運用支援ソリューションであるAIOpsがどのぐらい効果があるのかNTTコミュニケーションズ様と共同で実際のリアルな環境を用い実証をしました。今回は、その結果と考察をご紹介します。
ネットワーク・インフラ運用監視の課題
ネットワークに限らず、インフラストラクチャーは変化が常態化しています。クラウドやハイブリッド環境、コンテナやサイト・リライアビリティ・エンジニアリング(SRE)など従来のIT環境を変革する技術が多く登場して、一般化しています。新技術が採用されていく一方で、ITサービスを安定稼働させる仕事はさらに複雑性を増していると言えるでしょう。稼働品質が不安定なサービスは、サービス内容がいかに素晴らしいものであったとしても、評価を下げて、他の競合に取って代わられてしまいます。そのため、運用品質の維持はITサービスにおいて大変重要な領域といえますが、手作業が多く介在し、属人的な技術によって支えられているのが現実です。今後厳しさを増すと思われる人材獲得を考慮すると、どのようにして品質を維持しながら運用の生産性を向上させるかということが大きな課題となっていると言えるでしょう。定型的な運用ではすでに自動化が多く活用されており、ツールも進化してきています。しかし、運用現場における障害対応、問題修復では依然として多くの時間と労力が必要な状況です。生産性改善を実現するための運用高度化は様々な視点から整理できます。ここではもっとも大きな課題である障害対応、問題修復に焦点をあてて、いままでとは異なるアプローチによって障害対応や問題修復にかかる時間を低減すること、またサービス提供の品質の変化にいち早く気付き、先取り対応を可能にさせる技術や仕組みについてNTTコミュニケーションズ様と共同で行った実証実験をもとに取り上げたいと思います。
実証の概要とねらい
NTTコミュニケーションズ様では広域ネットワークを中心としてデータセンターやクラウドサービスなどの多様なITサービスやネットワーク・サービスをご提供されています。ネットワークは機器の相互接続によって機能を提供しており、物理ネットワーク、論理ネットワークなど複雑な依存関係を包含している基幹となる基盤です。NTTコミュニケーションズ様においては、複雑化するネットワーク運用において、お客様へ提供するサービスの品質を高いレベルで保持しながら、属人化や運用者の負荷の軽減を目指しています。その実現のために、さまざまな技術の評価を行い模索しています。IBMは2023年11月よりNTTコミュニケーションズ様と共同でIBM Cloud Pak for AIOps(CP4AIOps)の機能によるネットワーク運用の高度化の実証実験(PoC)を行いました。実証では実際に運用されている自社の検証環境のネットワーク機器を対象として、擬似的な障害を発生させて分析するなど、CP4AIOpsによる運用高度化のソリューションが運用品質の向上にどのように寄与するか実証する目的で実施いたしました。
運用高度化の概要
運用高度化は下図の全体像があります。「AIによるインシデント対応高度化」、「システムの可観測性基盤」、 「資源の継続的最適化」が、運用高度化の三本柱と考えます。これらの高度化施策が、障害の未然防止、影響範囲の極小化、資源の効率的活用、運用に関わる人の働き方改革に寄与します。今回とりあげるのはAIによるインシデント対応高度化を提供するIBM Cloud Pak for AIOps(CP4AIOps) およびネットワークの可観測性基盤に対応するIBM SevOne NPM(SevOne)となります。

図1 運用高度化概要
CP4AIOpsソリューションの概要
IBM Cloud Pak for AIOps(CP4AIOps)は、IBM Researchによる120以上の特許によって支えられ、自然言語理解(NLU)、機械学習(ML)、自然言語処理(NLP)などのテクノロジーで強化されています。 また、強力なイベント管理、異常検出、イベント・グループ機能も含まれています。 IBM Automationプラットフォームの一部であり、ユーザーがアプリケーション関連とITインフラストラクチャー関連の問題を正確に検出および診断して、ダウンタイムを削減します。今回の実証ではCP4AIOpsの機能のうち、イベント管理・高度化とログの異常検知機能を用いました。またCP4AIOpsのみではなく、SevOneを用いて対象ネットワーク機器の構成接続情報をCP4AIOpsに連携するとともにSNMPなどのイベント情報を連携させることで対象ネットワーク機器とCP4AIOpsを連携させています。概要を下図に示します。CP4AIOpsおよびSevOneについては以下のリンクに詳細が記載されております。
CP4AIOps: https://www.ibm.com/jp-ja/products/cloud-pak-for-aiops
SevOne: https://www.ibm.com/jp-ja/products/sevone-network-performance-management
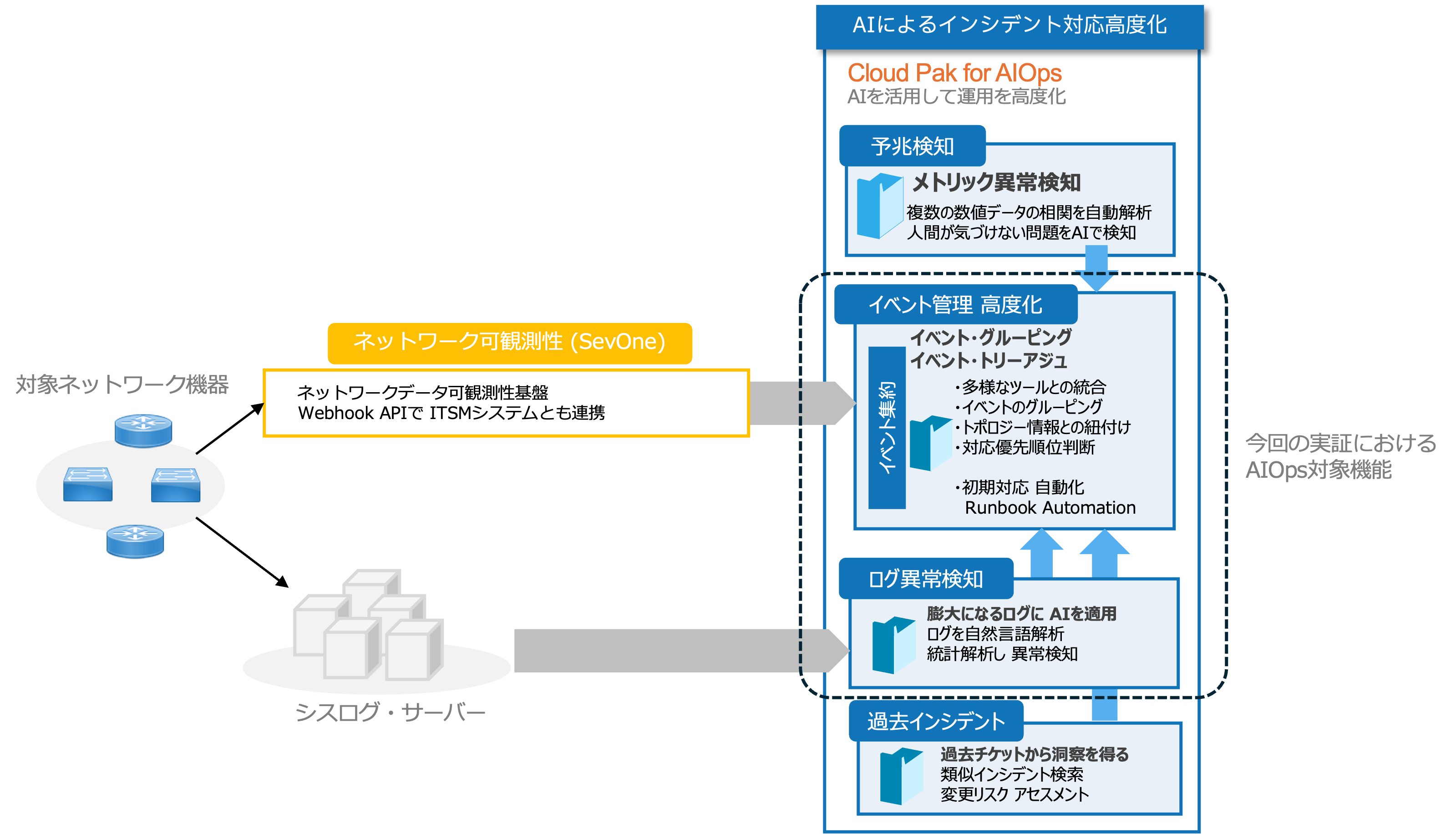
図2 実証におけるCP4AIOpsおよび関連ソリューション
イベント・グルーピングと根本原因分析の概要
CP4AIOpsのうち、今回の実証における対象機能の概要を説明します。一つ目はイベント・グルーピングと根本原因分析となります。
IT環境ではさまざまなイベント情報が非常に大量に発生しており、単なる状態の変化を通知するものから問題を含むものまで多様なものが、さまざまな資源から発生しています。それら個々の事象をCP4AIOpsではイベントと呼びます。イベントは障害発生時には多量に発生しますが、その多くが単一の障害に起因した派生的なイベントになります。たとえばサーバーのメモリーの障害により稼働するOSやアプリケーションに問題が波及する場合は、メモリーに関するイベントに加えてOSやアプリケーションのイベントが大量に発生することになりますが、つきつめれば原因は一つです。問題を共有する派生的なイベントをグループ化して問題の根本の原因となっている事象を特定することができれば、大量の情報を精査する時間を大幅に短縮することになり障害からの回復の時間を大きく低減することができます。CP4AIOpsではイベント・グルーピンングと根本原因分析(RCA: Root Cause Analysis)という機能として提供しています。下図にCP4AIOpsのイベント・グルーピングの流れを示します。

図3 イベント・グルーピング化の流れ
CP4AIOpsでは、さまざまな資源から発生する情報はイベント、そのなかで対処の必要があると考えられるものをアラートと定義します。そして一つ以上のアラートを同一の問題を共有するグループとしてまとめたものをインシデントと定義しています。グループ化は以下の分析ロジックを組み合わせて実現しています。
表 1 グルーピングの原則

最終的にグループ化されたアラートをインシデントとして提示することで、多量の情報から少量の情報へと絞り込んでいきます。そしてCP4AIOpsは、このインシデントに対して根本原因の推定を行います。すべてのアラートに対して原因可能性をスコア化して評価し、スコアの高い順から疑わしい原因として提示します。CP4AIOpsが根本原因を推定するロジックは単一ではなく複数の要因を組み合わせてスコア値を出しています。下表にて推定原因の判定ロジックの概要を整理しています。合計スコア値が高いほど推定原因の中で高いランクとなります。
表 2 推定原因のロジック

ログ異常検知の概要
実証におけるCP4AIOpsの対象機能としてログ異常検知の概要を説明します。ログの分析は運用における定番の作業ですが、セキュリティ目的の監視を除くと、ほとんどの場合は障害があった時に過去を振り返って障害の起因となったものを判別し、何がいつ起こったのかなど事象の時間軸を整理する目的で用いられています。これらの従前のアプローチと異なりCP4AIOpsは独自の手法によりログを活用することができます。システムの状態変化がログに現れた場合、その異常を察知して知らせるログ異常検知というものです。CP4AIOpsには2つの異常検知メカニズムが提供されています。ひとつは自然言語分析というものです。CP4AIOpsは事前に ログデータ(期間1ヶ月で対象機器ごとに最低2,000行)を読みこみ正常時のログ出力の「モデル」を生成します。一般的にログは定型部分と変数部分に分けることができます。変数部分には数値やエラーコードなどが入ります。下図にシンプルな解析パターンの例を示しています。

図4 パターン認識の例
これらのパターン認識をログから学習しますが、学習するのはこれだけではなく、これらのログがどのぐらいの頻度で発生するか時間軸における分布の仕方も学習します。これによりどのようなログがどんな頻度で現れるのか、ログの出力元ごとに学習していきます。この学習結果から逸脱すると異常なログとして通知する仕組みとなっています。
CP4AIOpsのもう一つの異常検知メカニズムが統計ベースラインというものです。エラー コードや例外を示す短い文字列などの特定のエンティティをログから抽出してエラーの種類ごとに 10秒間のウィンドウ内でのエラー数がカウントされ、エラーごとの頻度分布モデルが作成されます。このモデルから逸脱するようなログが検知されると異常なログとして通知します。
NTTコミュニケーションズ様における実証環境
NTTコミュニケーションズ様のご協力を得て、データセンターのVMware仮想基盤にRed Hat OpenShiftを構築し、CP4AIOpsおよびSevOneを構築しました。下の図が構築された環境の概要となります。
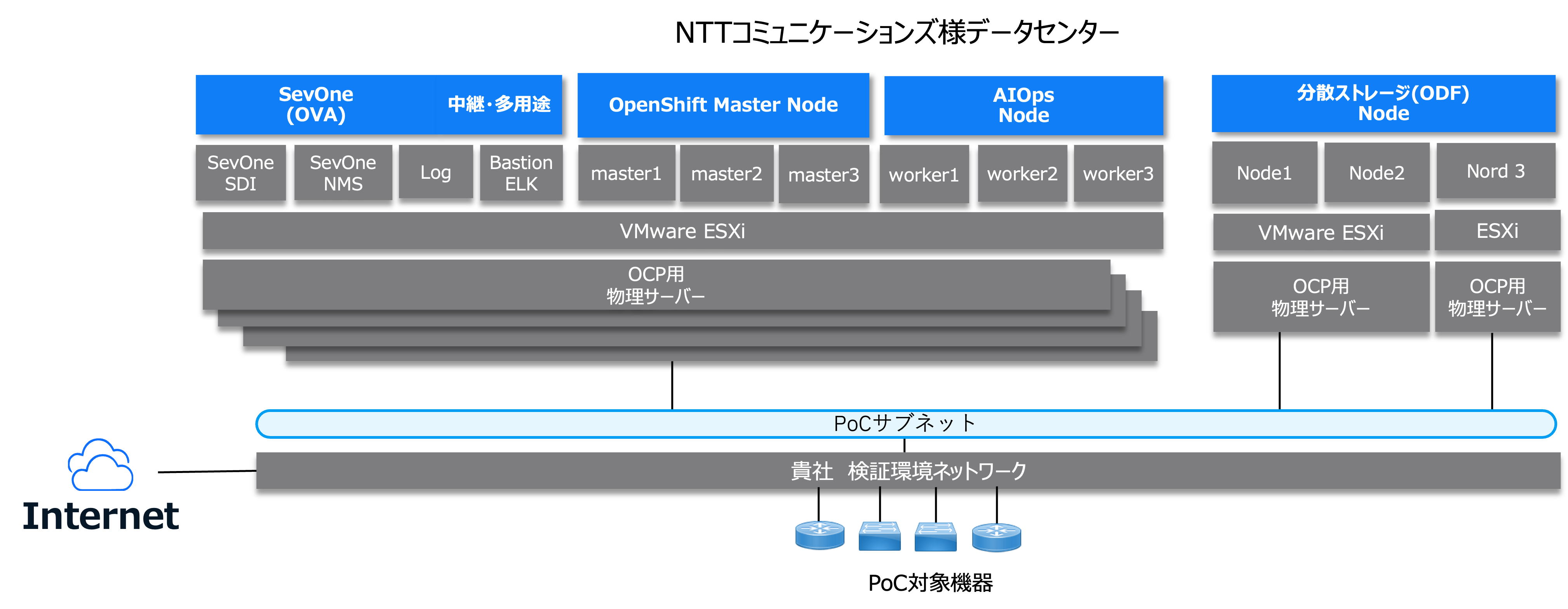
図5 実証環境
実証におけるデータの流れの概要は下図のようになります。ネットワーク機器の情報収集とイベント連携はSevOneを介して行い、ログデータは対象機器から既設のパケットブローカーというサーバーに送信し、そこからCP4AIOpsへリアルタイムで取り込めるように構成しました。
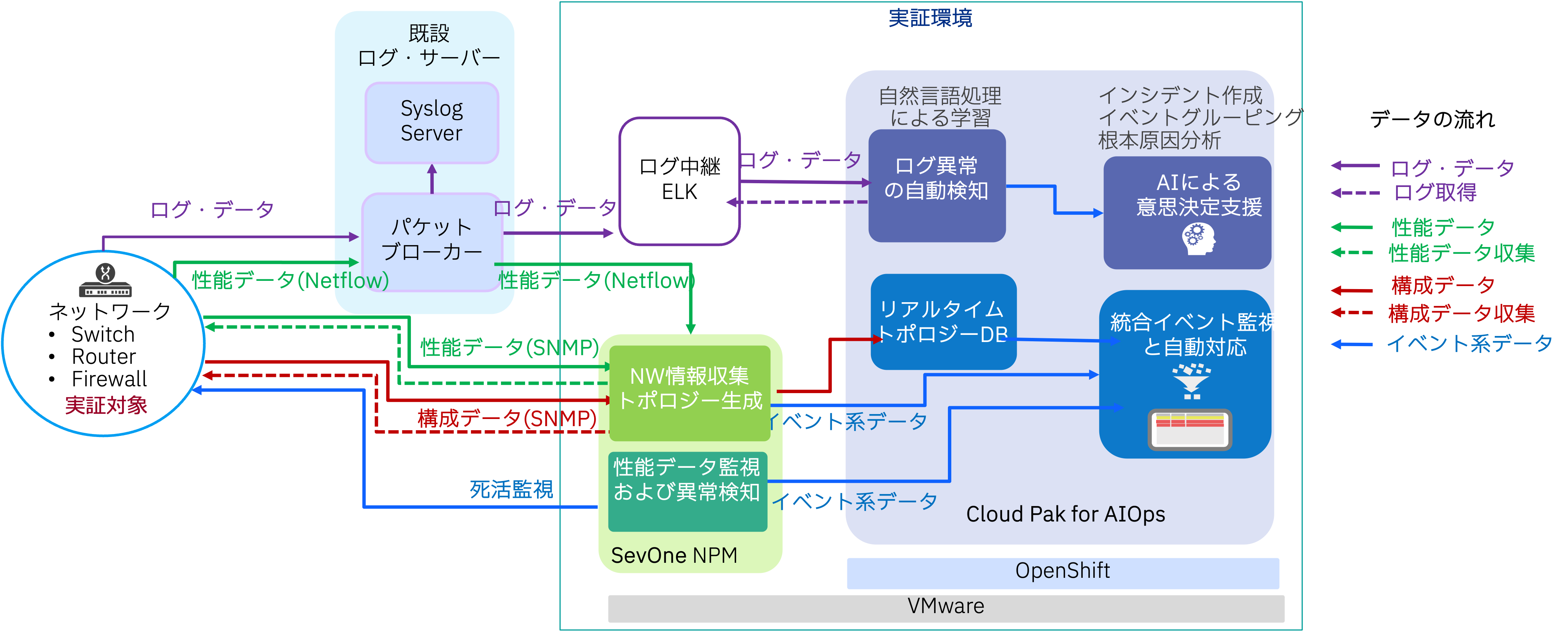
図6 構成要素
イベント・グルーピングと根本原因分析の実証
実証では、NTTコミュニケーションズ様の検証環境のネットワーク機器を対象として意図的に障害を発生させてCP4AIOpsによる機能の有効性の有無を確認しました。まずはさまざまな接続のゲートウェイとして構成している機器の電源を意図的に遮断したときの検証を行ってみました。
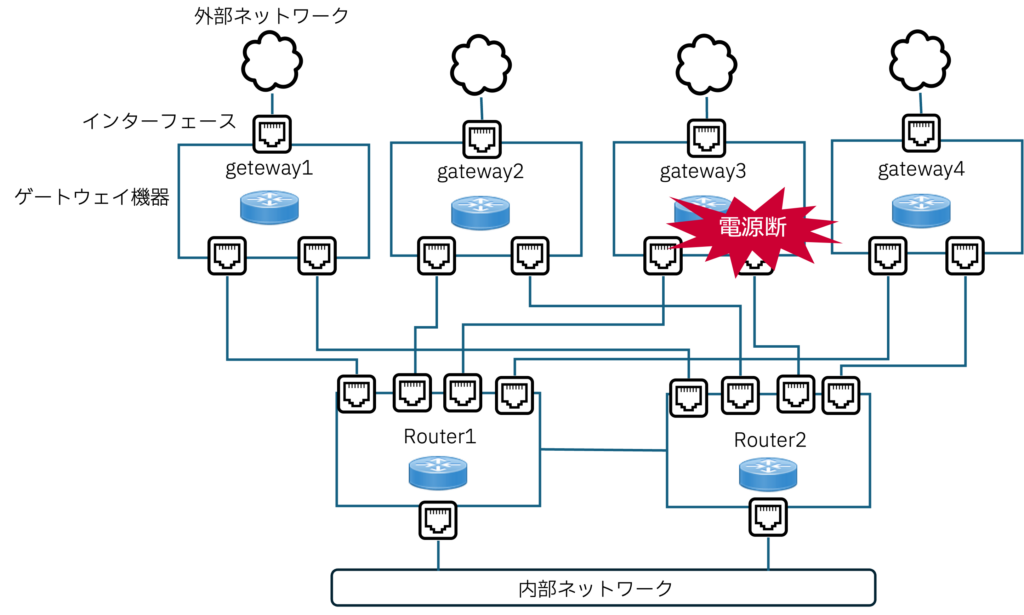 図7 電源断テスト
図7 電源断テスト
ネットワーク機器gateway3はゲートウェイ機能を提供し、多数の機器と接続されています。電源ダウンにより接続断のイベントが接続している機器から発生し、かつ経路制御プロトコルであるOSPFやBGPの接続情報が変化するため多数のイベントが他のネットワーク機器から発生します。これらのイベントについて電源断を起因とする一つのグループとしてCP4AIOpsがまとめられるのか検証してみました。
実際の検証における結果を下図にまとめています。CP4AIOpsはgateway3の電源ダウンによって副次的に発生する隣接接続機器のインターフェース・ダウンをグループ化して一つのインシデントとしました。低いレイヤーの障害によって引き起こされる上位レイヤーの障害、OSPFやBGPの障害をgateway3の電源ダウンのイベントにグループ化して、根本原因分析ではgateway3の障害を考えられる原因として挙げています。
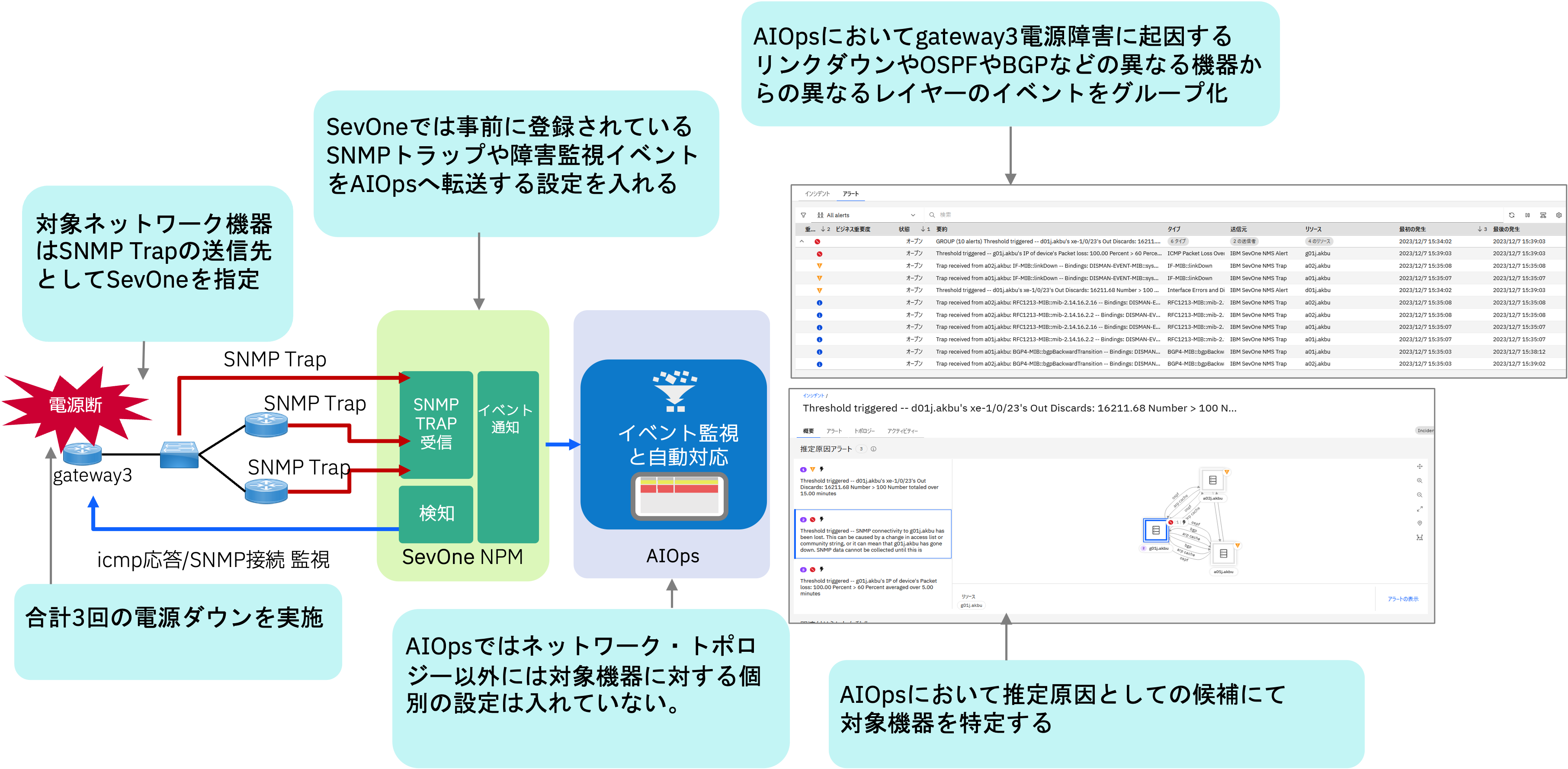
図8 電源断におけるCP4AIOps動作
もうひとつの実証では意図的にネットワークのループ構成をして高いトラフィックを発生させてCP4AIOpsに推定原因の分析をさせています。ループ構成のネットワークでは存在しない宛先にpingコマンドを打つとブロードキャスト通信がループ内で増殖して大量の負荷を発生させます。現在ネットワーク機器にはループ構成を検知してブロードキャスト通信を抑制する機能を有していますが、今回検証ではCP4AIOpsの機能を確認するためにあえてその機能をオフにしています。大量のブロードキャストはループを構成する機器すべてで循環しますので、どこが発生源か判別しづらい特性があります。構成は下図のように、末端の機器で物理的な回線をつかってループを構成します。

図9 ループ構成
意図的にブロードキャスト通信の大量発生による高負荷状態を作り出し、ブロードキャスト通信の量をSNMP経由でSevOneによって収集しました。そこからブロードキャスト通信の暴発をイベントとしてCP4AIOpsへ連携しています。CP4AIOpsは複数機器で発生したイベントを1つのインシデントとしてグループ化を行いました。根本原因分析ではループを発生させた機器を挙げることができました。ループのような障害ではなく、単にデータ量が多い高トラフィックを発生させた場合では障害として報告しませんでした。下図に検証結果の概要を記載しています。

図10 ループ構成検証におけるCP4AIOps 動作
イベント・グルーピングと根本原因分析の実証では、SNMPなどの接続設定以外には検査対象の機器には設定を追加しておらず、CP4AIOpsのパラメーターも、ほぼデフォルトの設定の状態でした。
イベント・グルーピングと根本原因分析の実証まとめ
実証ではある程度、想定結果通りにグルーピングと根本原因分析を実証することができました。今回の実証では実際の環境で検証を行うことができましたが、限られた検証環境での結果でもあります。イベント・グルーピングと根本原因分析は運用者の負荷軽減に寄与することが期待されますので、さらに実績を積み信頼度を上げていくことが必要と考えます。
ログ異常分析の実証
ログ異常分析の実証では、対象機器のログを学習させたあと、過去に起こった障害時のログを抽出し、ログの発生時刻を未来の日付と時刻に変更させてログサーバーに投入しCP4AIOpsがそのログを読み取ってログの異常を検知できるかどうか確認しました。実証時の動作概要を下図に示します。

図11 ログ異常検知の検証の動作概要
実証には2件の過去の障害のログを用意してありました。最初にファイアウォール機器の内部エラーにより、動作不全を起こした時のログを読み込ませたところ、CP4AIOpsは、障害の発生した時間帯から発生した、いままで発生しなかった内部エラーログをログ異常として検知しました。
もう一件は、具体的な障害に結び付かなかったが、ネットワーク機器のなんらかの不具合によりエラーメッセージが発生したログをCP4AIOpsに読み込ませましたが、これについては検知しないという不可思議な状況となりました。この状況についてCP4AIOpsのログの異常検知の動作を深掘りしていきました。
ログ異常検知の深掘りでわかったこと
CP4AIOpsが検知しないログは下図のような形で出力されていました。一定量のエラーらしきログが秒まで同じタイムスタンプで連続して出力され、間隔をおいてまた一定量出力されるというものでした。

図12 異常を検知しなかったログ
CP4AIOpsの自然言語処理によるパターン分析により当該機器のログのパターンが学習されているので、パターンに合致しないログを発見したら検知するものと考えていましたが、CP4AIOpsは未知のパターンの発見だけではログ異常として報告しないことがわかりました。ログの異常検知という機能は、指定する文字列に反応して報知する単純なフィルターではありません。学習時にログの発現頻度を正規分布で学習し、未知のログのパターン発見に加えて、そのパターンの発生頻度が正規分布からの逸脱していることを確認すると、「何かおかしなことが起こっているのではないか」と判断する動作をします。CP4AIOpsはこの他にも異常と判断する基準があり、これらの組み合わせで誤検知の割合を低減させているとのことです。しかし、対象のエラーのログはかなり多くの発生していたため頻度も逸脱していそうですが、これを検知しなかったのは、CP4AIOpsはログの頻度を10秒間隔でサンプリングをしており同じ時刻の複数のログが一件のログに丸められてしまって頻度の逸脱にいたらなかったと考えられます。検証時のCP4AIOpsバージョンの仕様からくる制約ですが、このあたりは最新のバージョンではログ異常検知の動作が改善されているとのことですので、今後再度確認をしていきたいと考えています。
ログ異常検知の実証まとめ
ログの異常検知ではNTTコミュニケーションズ様のご協力を得て、実際の環境における実証を行うことができました。実証では検知の動作まで踏み込んで深掘りをしたことで、ネットワーク機器におけるログ異常検知についての利用の仕方や課題についても把握することができ、貴重な検証を行うことができました。
NTTコミュニケーションズ様が実証を経て実感されたこと
共同で実証を行ったNTTコミュニケーションズ様より本件に関する所感をいただいています。以下に掲載します。
弊社では運用を改善させる可能性があるソリューション、ツールを常に模索しています。今回は、机上や疑似環境での確認ではなく、弊社の検証ネットワークにCP4AIOpsを導入するという、本格的な実証に共同で取り組みさせていただき、実装例を確認することにより社内でのノウハウを溜めることができました。実証の中では異常の検知やネットワークトポロジーの可視化機能などは便利な機能と感じました。特に、トポロジーの可視化では、発生した障害と対応付ける機能があるため、発生箇所の特定が迅速になることを実感しました。 根本原因推定では、同一の原因と推定されるものが一つのグループに入り、運用担当者の補助機能として活用できると考えております。今回、SevOneとCP4AIOpsというツールを組み合わせて検証していますが、運用の目的に合わせて、さまざまなツールをどう組み合わせていくべきかという点も重要なポイントになると思いました。一方で多くの気付きもありました。ネットワーク機器では、ログを単一の情報源として異常検知を行うだけでは、情報が足りないことが多く、ネットワークの異常を早期に検知するのは難しいとわかりました。ログだけではなく、多様な情報を総合して異常の早期検知が可能になることがわかり、さまざまなアプローチが必要と感じました。こうした認識も一つの成果と考えております。実証期間中にCP4AIOps開発チームとも質疑応答をさせていただきましたが、開発スピードが早く、実証の最中に感じた改善点が次のアップデートで実装されていることが印象的でした。 今回は、短期間で監視対象を限定しており、個別環境へのチューニングは最小限に留めていました。より踏み込んだ運用を行うことが出来れば、新しい発見が見込めるかと期待しております。
見えてきた課題と今後の方向性
管理ツールとしてのCP4AIOpsは、何が起きているのか(イベント・グルーピング)、何が影響を受けているのか(トポロジーによる影響表示)、考えられる根本原因は何か(推定原因分析)、正常時と異なる状態の検知(ログ異常分析)など統合的な視点を提供して、複雑で大規模なネットワーク環境の運用高度化に寄与できる可能性を示したと言えます。同時に課題も見えてきています。ネットワーク機器は自身の状態を記録するログについては、あまり多くの情報を与えてくれないことがわかりました。これは当然のことで、ネットワークは個々の機器が相互接続されてはじめて機能を提供できるため、単一の個体の情報からは全体の状況が見えてこないからでしょう。ネットワークの状態の変化察知にはネットワークの運用状況の可観測性を高い解像度で取り出して分析することが必要となります。どのような方式でどのような可観測性を獲得・分析ができるか、さらなる研究が必要です。
ネットワーク運用の高度化について長期的な展望として考えてみます。CP4AIOpsは運用担当者の負荷軽減と生産性向上に寄与しますが、運用担当者を代替するものではありません。問題解決のために何をするべきか監視システム側から提案することができれば、運用管理という領域で新たな次元に踏み出すことができるでしょう。将来的には検知から開始された事象は、分析を経て対策を立案して実装にいたるまで、連続した流れで人手の介入を最小限に抑えた自動化を実現することが理想となります。下図に流れをまとめています。現在、実証実験として対策用のスクリプトについて自然言語プロンプトを用いて生成することも試行されていることから、実現については遠い未来ということでもなさそうです。
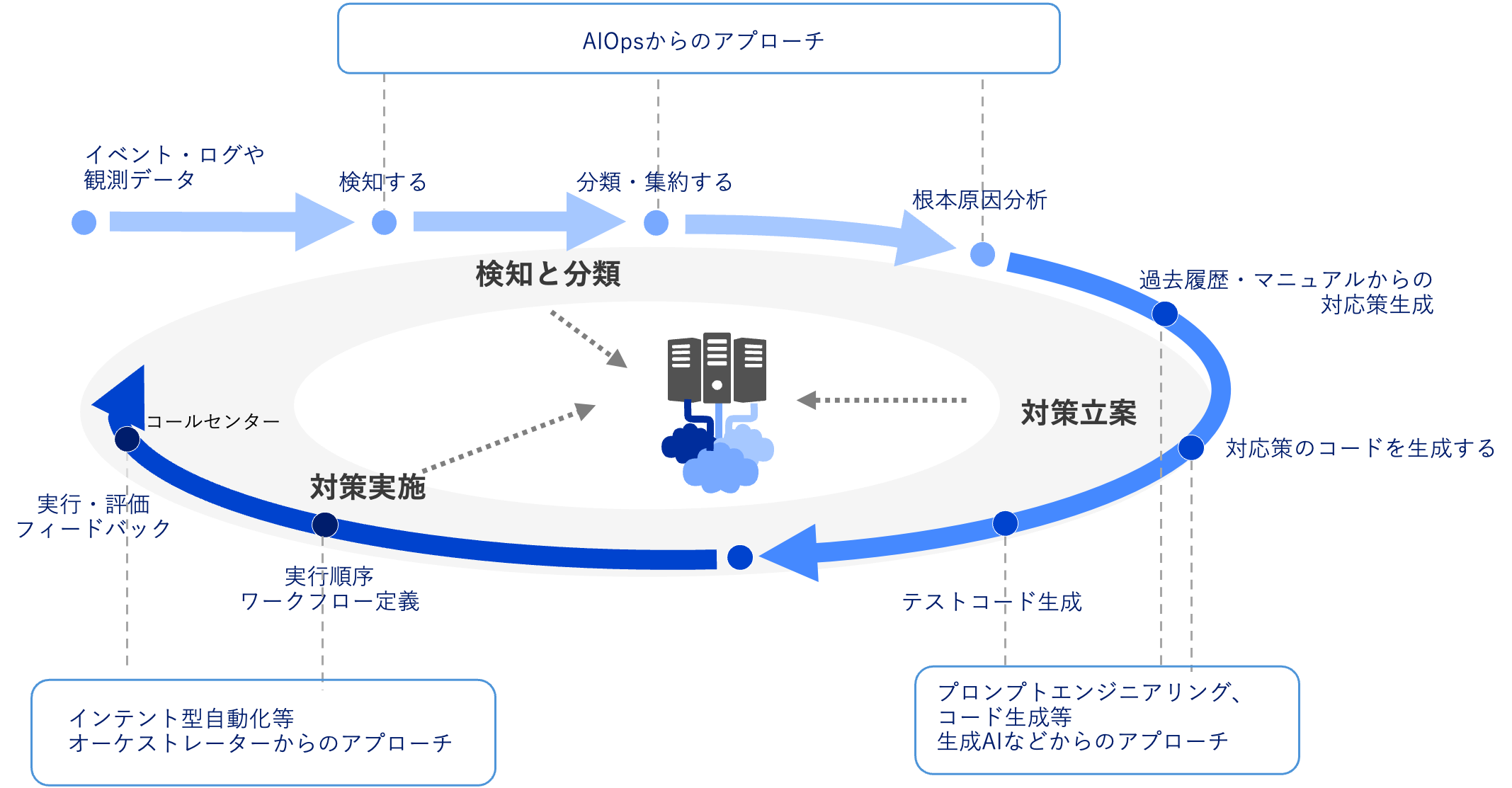
図 13 運用の高度化の将来像
末尾になりますが、本記事の作成にあたりご協力いただきましたNTTコミュニケーションズ様に心より御礼申し上げます。
本記事に関するお問い合わせはこちら
Cloud Pak for AIOps製品ページ

木村 安宏
NTTコミュニケーションズ株式会社
イノベーションセンター テクノロジー部門
担当課長

工藤 聡倫
NTTコミュニケーションズ株式会社
イノベーションセンター テクノロジー部門
主査

吉田 晴信
NTTコミュニケーションズ株式会社
イノベーションセンター テクノロジー部門

板場 幹夫
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
クラウド・オートメーション
IBM認定ITスペシャリスト

増田 健
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
クラウド・オートメーション
IBM認定ITスペシャリスト

宮野 隆正
日本アイ・ビー・エム株式会社
NTT事業部
アカウントテクニカルリーダー

セキュリティー・ロードマップ
IBM Cloud Blog
統合脅威管理、耐量子暗号化、半導体イノベーションにより、分散されているマルチクラウド環境が保護されます。 2023 安全な基盤モデルを活用した統合脅威管理により、価値の高い資産を保護 2023年には、統合された脅威管理と ...続きを読む

量子ロードマップ
IBM Cloud Blog
コンピューティングの未来はクォンタム・セントリックです。 2023 量子コンピューティングの並列化を導入 2023年は、Qiskit Runtimeに並列化を導入し、量子ワークフローの速度が向上する年になります。 お客様 ...続きを読む

ハイブリッドクラウド・ロードマップ
IBM Cloud Blog
コンポーザブルなアプリケーション、サービス、インフラストラクチャーにより、企業は複数のクラウドにまたがるダイナミックで信頼性の高い仮想コンピューティング環境の作成が可能になり、開発と運用をシンプルに行えるようになります。 ...続きを読む