IBM Data and AI
IBMがクラウド上にAIスーパーコンピュータを構築した理由
2023年06月21日
カテゴリー Data Science and AI | IBM Data and AI | IBM Watson Blog | IBM クラウド・ビジョン
記事をシェアする:
IBM初のAIに最適化されたクラウドネイティブ・スーパーコンピューター「Vela」をご紹介します。
![]()
図:AIシステムの構築を検討されている方や、もっと詳しい情報をお知りになりたい方は、ぜひお問い合わせください。
AIモデルは、私たちの生活や仕事のあらゆる場面にますます浸透しています。年を追うごとに、AIへの高まる需要に応えるため、より複雑なモデル、新しいテクニック、新しいユースケースが生み出され、より多くの計算能力が必要となってきています。
その最たる例が基盤モデル、すなわち、ラベルなしの多種多様なデータで学習し、最小限のファインチューニングでさまざまなタスクに使用することができるAIモデルです。しかし、この種のモデルは巨大で、場合によっては数十億を超えるパラメータで表現されることもあります。このような規模のモデルを学習するためには、強力な個々のコンポーネントで構成され、大規模な計算課題を高い計算能力で解く、いわゆるスーパーコンピューターが必要です。
従来、スーパーコンピューターの構築には、ベアメタルノード、高性能ネットワークハードウェア(InfiniBand、Omnipath、Slingshotなど)、並列ファイルシステムなど、ハイパフォーマンスコンピューティング(HPC)専用に通常用いられる構成要素が必要でした。しかし、従来のスーパーコンピューターはAI用に設計されたものではなく、米国の国立研究所が定義するようなモデリングやシミュレーションのタスク、あるいは特定のニーズを満たしたい他のお客様に対して優れた性能を発揮するように設計されていました。
これらのシステムは確かにAIにも適しており、多くの「AIスーパーコンピューター」(たとえばOpenAIのために構築されたマシン)はこのパターンを踏襲していますが、そのような従来の設計ポイントは、歴史的に、高いコストと限定的な柔軟性が伴うような技術選択となってしまっていました。それに対し私たちは、「もし大規模なAIに特化した場合、どのようなシステムを設計するべきだろうか?」という問いを設定しました。
その問いの結果、IBM初のAIに最適化されたクラウドネイティブのスーパーコンピューター「Vela」を構築することになりました。2022年5月からIBM Cloud内で稼働し、現時点では一般公開せず、利用はIBM Researchコミュニティー内だけにとどめられています。このスーパーコンピューターで採用した設計により、自由にスケールアップできる柔軟性を持ち、同様のインフラを世界中のどのIBM Cloudデータセンターにも容易に展開できるようになっています。 Velaは現在、IBMの研究者が、基盤モデルに関する研究開発など、最も高度なAI機能を開発するための主要な環境であり、また、パートナー様とのコラボレーションにより、様々な種類のモデルを学習する場となっています。
なぜAIスーパーコンピューターをクラウドで構築するのか?
IBMはスーパーコンピューターを長年手がけており、世界のトップ500リストにランクインする最高性能のシステムを何世代にもわたって設計してきました。この中には、現在世界のスーパーコンピューターでトップレベルにあるSummitやSierraも含まれています。私たちは、システムを設計するたびに、目的ワークロードでの性能、耐障害性、コストを改善し、研究者の生産性を高め、顧客やパートナー様のニーズを満たす新しい方法を発見してきました。
昨年、私たちは、ワールドクラスのAIモデルの構築と展開にかかる時間を可能な限り短縮することを目標に掲げました。するとこの一見シンプルな目標設定で、社内の活発な議論が始まりました。すなわち、従来のスーパーコンピューティングモデルでオンプレミスにシステムを構築するのか、それともクラウドにシステムを、いわばクラウドを兼ねたスーパーコンピューターを構築するのかという議論です。後者の場合、性能は少し落ちるかもしれませんが、生産性はかなり向上します。クラウドでは、必要なリソースをすべてソフトウェアで設定し、確立され堅牢なAPIインターフェースを使用することで、統合したいサービスの幅広いエコシステムにアクセスすることができます。ストレージのバックエンドを独自に構築する代わりに、IBMのCloud Object Storeにあるデータセットを活用することができます。IBM Cloud の VPC 機能を活用し、高度なセキュリティー実装を使用してパートナー様と共同作業をすることができます。生産性向上の点で、そのような数えきれないメリットが考えられました。そして議論が進み、クラウドネイティブのAIスーパーコンピューターを構築する必然性が明らかになりました。その構築方法は以下の通りです。
鍵となる設計ポイントとイノベーション
AI中心のインフラを構築する際、どうしても必要なのがGPU(AIアクセラレータ)を多数搭載したノードです。このようなノードを構成するのに、各ノードをベアメタルで提供するか、ノードを仮想マシン(VM)として構成できるようにするかという2つの選択肢がありました。†一般的に、AIの性能を最大限に引き出すにはベアメタルが適していると言われていますが、VMの方がより柔軟性があります。VMを採用すれば、AIユーザーごとに、異なるソフトウェアスタックでインフラをプロビジョニング・再プロビジョニングすることが、サービス提供チームには可能になります。例えば、このシステムが稼働した当時、研究者の中にはSpectrum LSFのようなHPCソフトウェアやスケジューラーを使用していた人がいることが分かっていました。一方で、多くの研究者がOpenShiftをベースとした当社のクラウドネイティブなソフトウェアスタックに移行していることもわかっていました。VMを使えば、当社のサポートチームがAIクラスターを柔軟かつダイナミックに拡張し、さまざまな種類のワークロード間でリソースを数分でシフトすることが容易になります。従来のHPCソフトウェアスタックとクラウドネイティブのAIスタックの比較を図1に示します。問題点は、通常、仮想化を用いたクラウドネイティブスタックは、ノードのパフォーマンスが低下するということです。
そこで私たちは、「どうすればVM上でベアメタル同様のパフォーマンスを実現できるのか」と考えました。多くの研究と発見を経て、私たちは、ノード上のすべての機能(GPU、CPU、ネットワーク、ストレージ)をVMに公開する方法を考案し、仮想化のオーバーヘッドを5%未満に抑えることに成功しました。これは、私たちが知る限り、業界で最も低いオーバーヘッドです。この作業には、Virtual Machine Extensions(VMX)、シングルルートIO仮想化(SR-IOV)、巨大ページのサポートを備えた仮想化用のベアメタルホストの構成が含まれます。また、どのネットワークカードがどのCPUやGPUに接続されているか、GPUがどのようにCPUソケットに接続されているか、GPUがどのように互いに接続されているかなど、VM内のすべてのデバイスとその接続を忠実に表現する必要がありました。そのような作業と、その他のハードウェアとソフトウェアの設定により、ベアメタルに近い性能を実現することができました。

図:HPC AIシステムスタックとクラウドネイティブなAIシステムスタックの比較
2つ目の重要な選択は、AIノードの設計です。Velaを使用して大規模なモデルを学習することを想定し、GPUのメモリは80GB、ノード上のメモリとローカルストレージは大容量(DRAM 1.5TB、NVMeドライブ3.2TB×4台)を選択しました。大容量のメモリとストレージは、AIの学習データ、モデル、その他の関連成果物をキャッシュして、GPUにデータを供給し続けるために重要と予想されました。
システムの性能に影響を与える3つ目の重要な点は、ネットワーク設計です。Velaをクラウドの一部として運用することを考えると、このシステムのためだけにInfinibandのようなネットワークを別途構築することは、このプロジェクトの目的にはそぐわないものです。そこで、クラウドで一般的なイーサネットベースのネットワークにこだわる必要がありました。しかし、従来のスーパーコンピューティングの常識で言えば、高度に専門化されたネットワークはまさに必要なのです。そこで、「標準的なイーサネットベースのネットワークが、深刻なボトルネックにならないようにするためにはどうすればいいのか?」という問題が生じました。
私たちはまず、各ノードのネットワーク・インターフェース・カードでSR-IOVを有効にし、それぞれの100Gリンクを仮想機能経由でVMに直接アクセスできるようにすることから始めました。これにより、IBM CloudのVPCネットワーク機能をすべて使用することが可能になりました。それらのネットワーク機能には、セキュリティーグループ、ネットワークアクセス制御リスト、カスタムルート、IBM CloudのPaaSサービスへのプライベートアクセス、Direct LinkへのアクセスやTransit Gatewayサービスが含まれます。
そして私たちが最近発表したPyTorchでの実験結果では、PyTorchレベルでワークロードの通信パターンを最適制御することで、ネットワーク通信時間をGPUで発生する計算時間の裏に隠すことができることを示しました。このアプローチは、前述の通り80GBのメモリを搭載したGPUを選択することによって40GBモデルと比べて大きなバッチサイズを使用し、完全分割データ並列(FSDP)な学習戦略をより効率的に活用することができるようにしたことで、さらに効果を発揮します。こうすることで、100億以上のパラメータを持つモデルについて、最大90%の効率で分散学習実行にGPUを使用することができます。次に私たちは、RoCE、すなわち、大規模なコンバージド・イーサネット上のリモート・ダイレクト・メモリ・アクセス(RDMA)の実装と、GPU Direct RDMA(GDR)を実装し、他のトラフィックへの悪影響を最小限に抑えながらRDMAとGDRのパフォーマンスメリットを提供する予定です。当社のラボでの測定では、これでレイテンシーを半分に減らせることが示されています。
Velaのアーキテクチャーの詳細
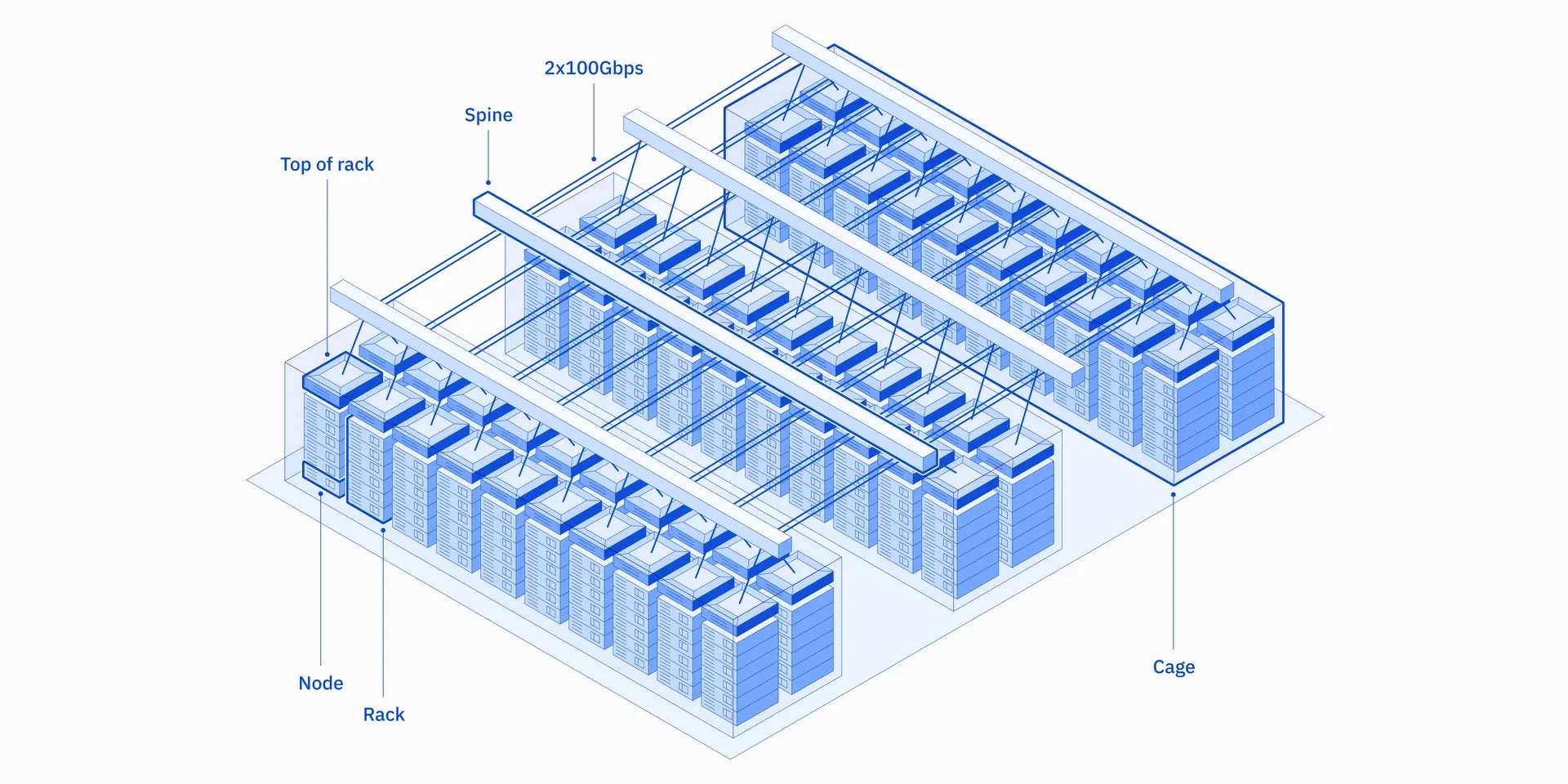
Velaの各ノードは、80GBのA100 GPUを8基搭載し、NVLinkとNVSwitchで相互に接続されています。さらに、各ノードには、第2世代Intel Xeon Scalableプロセッサ(Cascade Lake)2基、1.5TBのDRAM、3.2TBのNVMeドライブ4基が搭載されています。分散学習をサポートするため、計算ノードは複数の100Gネットワークインターフェースで接続されており、オーバーサブスクリプションのない2レベルのClos構造で接続されています。高可用性をサポートするため、冗長性を次のようにシステムに組み込んでいます。すなわち、ネットワークインターフェースカード(NIC)の各ポートは、異なるトップオブラック(TOR)スイッチに接続され、各TORスイッチは2本の100Gリンクを介して4台のスパインスイッチに接続され、1.6TBのクロスラック帯域幅を確保し、任意のNIC、TOR、スパインスイッチに障害があってもシステムの運用を継続できるようにしています。iperfやNVIDIA Collective Communication Library (NCCL)を含む複数のマイクロベンチマークでは、アプリケーションがノード間TCP通信の回線速度に近い速度で駆動できることが示されています。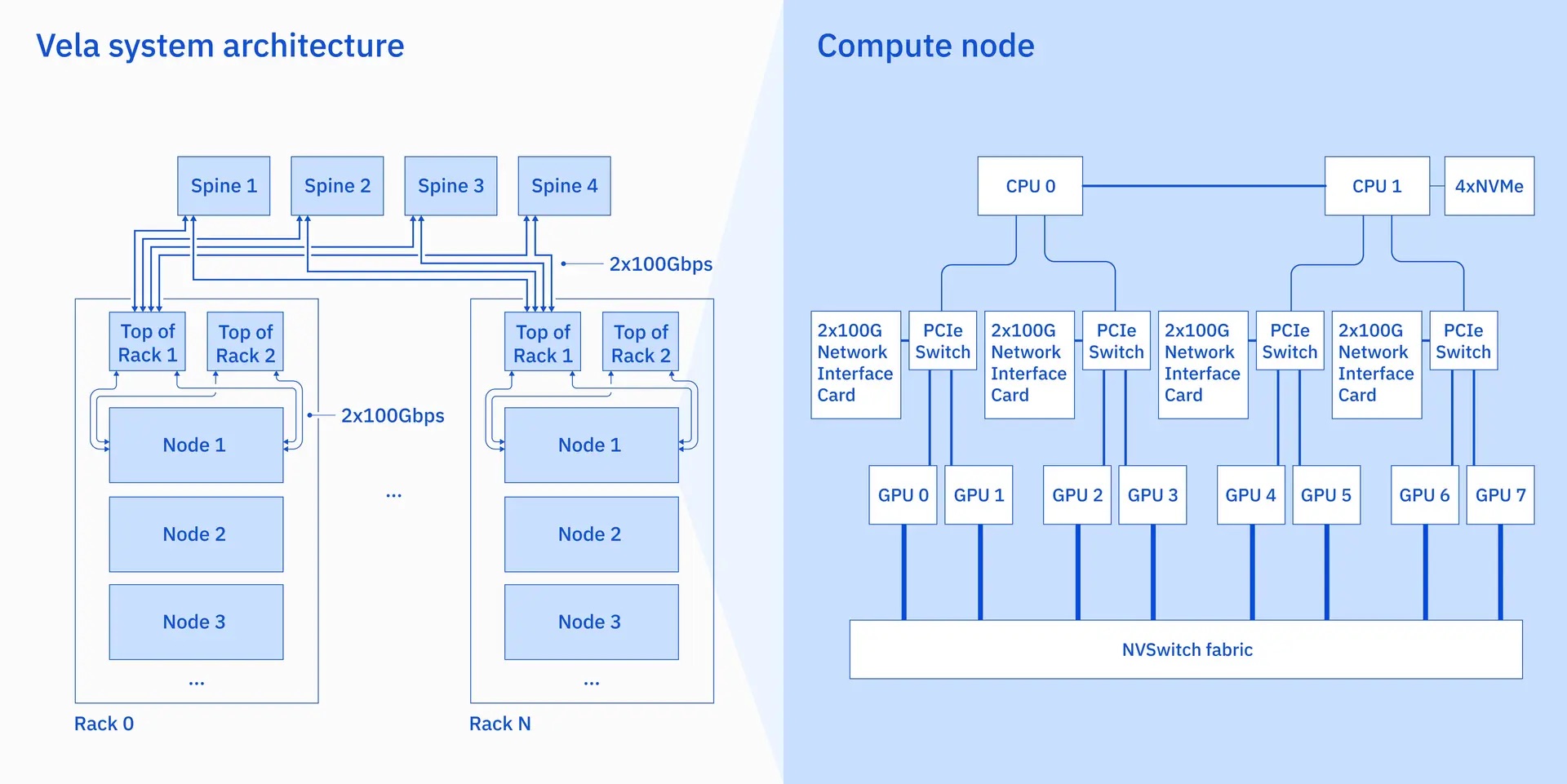
この設計と実装は、大規模なAIワークロードのパフォーマンスと柔軟性を実現することを念頭に置いて行われましたが、このインフラは、世界中のどのデータセンターでも、どんな規模でも展開できるように設計されています。また、IBM CloudのVPC環境にネイティブに統合されているため、AIワークロードは現在利用可能な200以上のIBM Cloudサービスも使用することができます。今回の作業はパブリッククラウドの文脈で行われましたが、このアーキテクチャはオンプレミスのAIシステム設計に採用することも可能です。
Velaが重要な理由と次なる課題
適切なツールとインフラを持つことは、研究開発の生産性を高めるために重要な要素です。多くのチームは、AI用に従来のスーパーコンピューターを構築するという「実証済み」の道を選びます。このアプローチに問題がないことは明らかですが、私たちは、ハイブリッドクラウドの開発経験によって可能になる、ハイパフォーマンス・コンピューティングとエンドユーザーにとっての高い生産性という2つのメリットを同時に提供するという、もっと良いソリューションに取り組んできました。
‡Velaは2022年5月から稼働を開始し、IBM Researchの数十人のAI研究者が数百億のパラメータを持つモデルの学習に実利用されています。私たちは、新たなシステムとソフトウェアの革新によって実現される、エンドユーザー生産性とパフォーマンスの両方に対する今後の改善について、より多くのことを共有できることを楽しみにしています。‡また、AIに最適化されたプロセッサーであるIBM AIUによって実現される機会にも期待しており、これについては今後、詳しくお伝えする予定です。クラウドネイティブなAIスーパーコンピューティングの時代は、まだ始まったばかりです。AIシステムの構築を検討されている方、もっと詳しく知りたい方は、ぜひ弊社までご連絡ください。
この記事は英語版IBM Researchブログ「Why we built an AI supercomputer in the cloud」(2023年2月7日公開)を翻訳し一部更新したものです。
†How to Deploy a High-Performance Distributed AI Training Cluster with NVIDIA A100 GPUs and KVM, at GTC 2022 ↩
‡Seetharami Seelam, Keynote Talk – Hardware-Middleware System co-design for foundation models, at the 23rd ACM/IFIP International Middleware Conference, Quebec City, Quebec, Canada.↩

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

データ・ロードマップ
IBM Data and AI
生成AIによるビジネス革新は、オープンなデータストア、フォーマット、エンジン、製品指向のデータファブリック、データ消費を根本的に改善するためのあらゆるレベルでのAIの導入によって促進されます。 2023 オープン・フォー ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む