

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
SPSS Modeler ヒモトク
自治体や企業が大注目!外国人観光客のインバウンド消費をSPSS Modelerで予測分析してみた
2016年09月09日
カテゴリー SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:
~ データサイエンティストを目指す大学生のブログ ~
データサイエンス系のメモとか備忘録とか。

みなさんこんにちは。慶應義塾大学、湘南藤沢キャンパス4年の石原智哉と、中島有希大です。普段はRを使ってPOSデータや選挙における投票行動の分析をしています。このたび研究室のプロジェクトの一環でSPSS Modelerを使えるようになったので、備忘録や学習用としてブログを書いていくことにしました。SPSS Modelerを使って、これまで学んできた予測の手法を実践していくとともに、仮説構築、分析している間に感動したこと、困ったことを共有できればと思います!

今回分析するテーマ
まず、第1弾として、最近僕たちが気になっているトピックの一つ「インバウンド消費」について考えてみました。
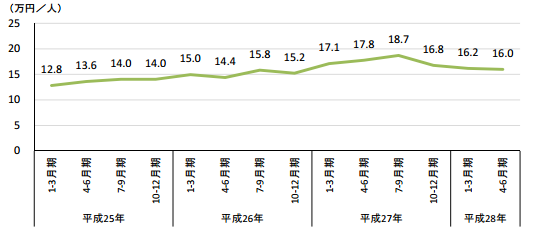
一時期に比べて消費の勢いはやや収まったと言われているものの、都心や観光地に行くとあちこちに大勢の外国人観光客がいる風景は変わらないですよね。以下の図は訪日外国人1人当たりの消費額です。
<図1> 訪日外国人1人当たりの消費額
自治体や企業でも、インバウンド消費を狙って地域振興をしていきたいと考えているところは多いと思います。そこで、観光庁のホームページで公開されている訪日外国人の行動に関するオープンデータとSPSS Modelerを使って分析をおこなってみたいと思います。
具体的には、インバウンド(訪日外国人旅行)に関する分析をテーマに、架空の観光地を想定して、地域の産業はどこの国の人の消費スタイルに合っているのか、そしてその国の人はどれだけのお金を使ってくれるのか。を予測分析してみたいと思います!
類似性からのアプローチ
この記事を読んでいる方で、商品の特徴を元に競合相手を見つけたり、顧客を増やしたりしたいと考えたことのある方はいませんか?
「ウチの商材の競合や顧客をフィーリングでなく、数字で見つけたい」
競合となる商品と顧客になりそうな人が求めているものが自分の商品とどれだけ似ているかという、“市場の製品比較”が共通していえる手法だと思います。
例えば、消費財であれば成分比較や入っている量や価格によって似ている製品、つまり競合製品を見つけ、そのうえで差別化を図り市場に投入する前に売り出していくポイントを決めることができます。
また、店舗に年齢層ごとにどれくらいの割合で来店しているのかがわかれば、顧客割合の似ている店舗を見つけ出し、店内のレイアウトを参考にしたりすることができます。
ひとことで言えば、「類似性」からのアプローチです。
分析手法
その類似性を探索するために、最近傍分析のk最近傍法(KNN分析)を使った分析を行っていきます。k最近傍法は機械学習のひとつで、保存されたパターンまたはケースに完全に一致する必要なしにデータのパターンを認識する方法として開発されました。類似したケースはお互いに近く、類似していないケースはお互いに離れています。つまり、2 つのケース間の距離は、それらの非類似度の尺度です。
その類似性を探索するために、最近傍分析のk最近傍法(KNN分析)を使った分析を行っていきます。k最近傍法は機械学習のひとつで、保存されたパターンまたはケースに完全に一致する必要なしにデータのパターンを認識する方法として開発されました。類似したケースはお互いに近く、類似していないケースはお互いに離れています。つまり、2 つのケース間の距離は、それらの非類似度の尺度です。
k最近傍法の結果、互いに近いケースを「近傍」と呼びます。新しいケース (ホールドアウト) が存在する場合、モデル内の各ケースからその新しいケースへの距離が計算されます。最も類似したケースの分類である「最近傍」が集計され、新しいケースが、最大数の最近傍を含むカテゴリーに投入されます。
例えば、自動車メーカーが、2 つの新しい自動車 (乗用車およびトラック) のプロトタイプを開発しているとします。新しいモデルを範囲に導入する前に、メーカーは市場にある既存の自動車でどれが最もプロトタイプに近いのか、つま りどの自動車が「最近傍」なのか、そのためどのモデルが競争相手となるのかを判断する必要があります。
この考えを、視点を変えて使ってみます。
分析に使用するデータ
KNN分析で使用するデータは平成28年4月~6月期の観光庁の訪日外国人消費動向調査*3です。
それを一部抜粋し、加工したものがこちらです。
<図2>KNN分析で使用するデータ
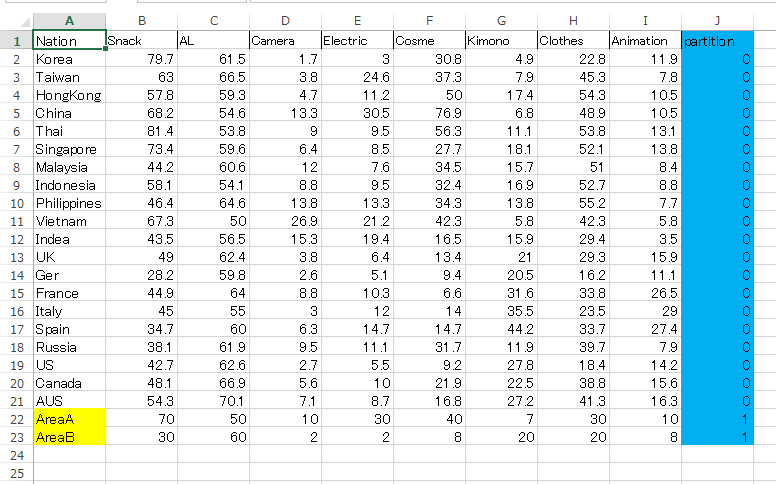
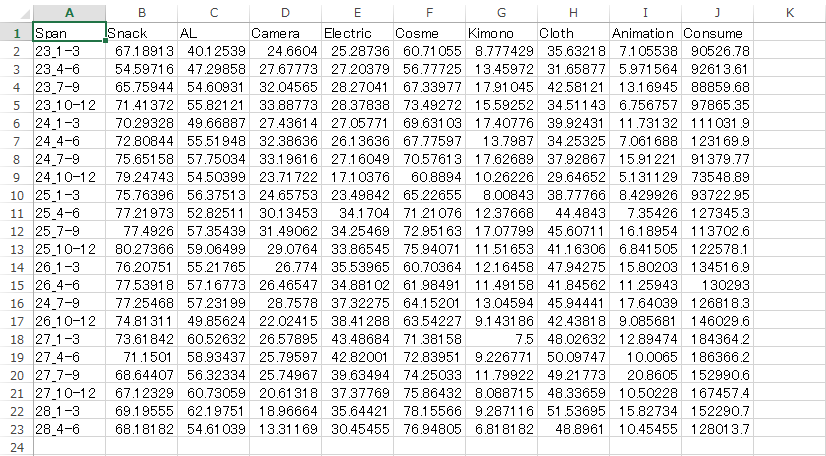
データの列は、
- Nation国名
- Snack 菓子類
- AL その他食料品・飲料・酒・たばこ
- Camera カメラ・ビデオカメラ・時計
- Electric 電気製品
- Cosme 化粧品・香水
- Kimono 和服(着物)・民芸品
- Clothes 服(和服以外)・かばん・靴
- Animationマンガ・アニメ・キャラクター関連商品
となっています。後の分析で過去のデータを取得した際、当時なかった品目は削除してあります。
partitionは分析用に付け加えました。詳しくは後述します。
数字は、該当する消費品目にどのくらいの割合の人が消費したかを示しています。
黄色でハイライトしたAreaAとAreaBは、外国人消費動向調査から抜粋したデータに付け加えたデータです。仮に、今このブログを読んでくださっている皆さんが大型商業施設や観光地の広報担当者であると考えてみてください。AreaAまたはBは、皆さんが広報を担当している商業施設や観光地を示します。観光庁の データからは、外国人が訪日した際にどのような品目にどのくらいの割合の人が消費したのかが国別にわかります。しかし、これはあくまでも日本全体のデータ であり、自分がPRしていくべき場所だけのデータではありません。そこで、これからインバウンド消費を狙っていこうとしているAreaAとAreaBが 「自分の地域(または商業施設)がどの国の観光客の消費品目の割合に近いのか」を知るために、架空の地域が自地域の観光客100人(100人の国に偏りは ないと仮定)にアンケートを取り、データを追加した、というストーリーです。
順序としては、既に品目別に消費金額が分かっているそれぞれの国の観光客のデータを計算したのち、AreaAとAreaBがどこの国の特性に近い のかを計算します。そのため、partitionという変数を入れ、値を0と1に分け、AreaAとAreaBを後から計算するようにしています。上図で はpartitionの列に青でハイライトを入れておきました。partitionの列のAreaAとAreaBが1となっています。
では以下デモに移ります!
分析フロー
ここでさっそく気づいたことですが…
Modelerの中でデータを扱うときは、使用するデータ(エクセルなりcsv)は閉じなければならない。
これ、やっている途中で気づいたんですが、意外とやっちゃうんですよね。データ編集して読み込ませて、いざ分析!ってなって結果を見ようとしたらエラーで・・・そのときに「あ!!」となること数多し・・・。要注意です!
では気を取り直して、エクセルのデータを読み込んでいきます!
- 入力タブからExcelを追加します。
<図3>

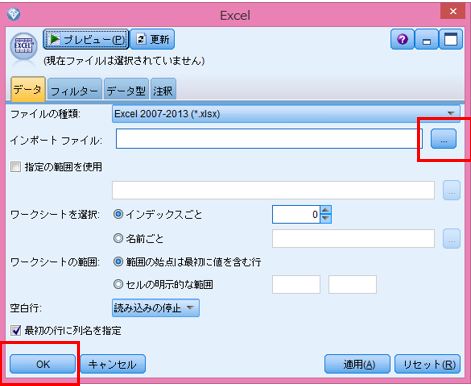
追加したノードをダブルクリックすると以下の画面が出てきますので、ファイルの場所、ファイルを選択し、OK。
<図4>
- 出力タブからテーブルを追加し、先ほどのExcelファイルから結合します。
<図5>

<図6>
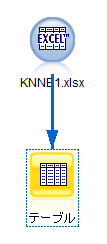
テーブルの中身を見てみます。テーブルをダブルクリックし、実行。
<図7>
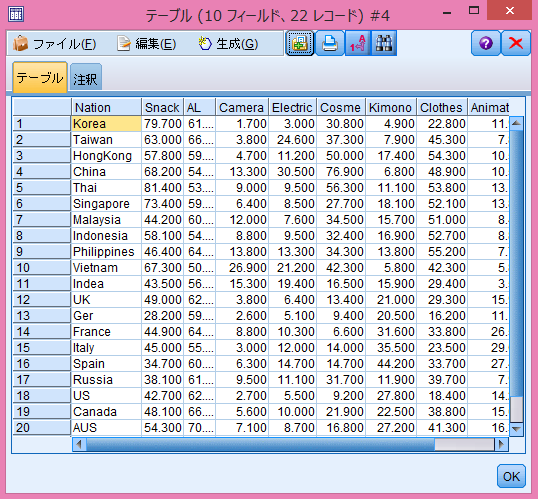
読み込み成功です!!
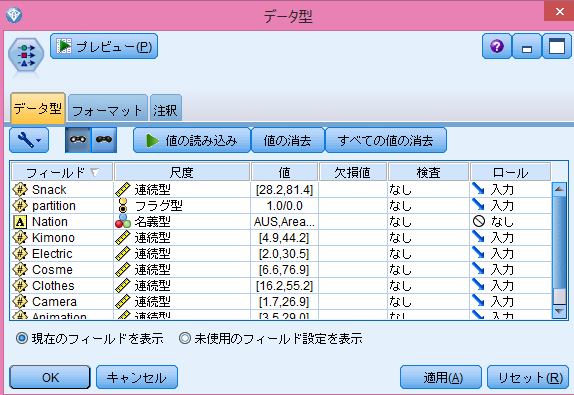
- フィールド設定タブからデータ型を追加します。
<図8>

エクセルノードから結合し、データ型をダブルクリックします。
Nationのロールを“なし”にして、partitionの尺度を“フラグ型”にします。
<図9>
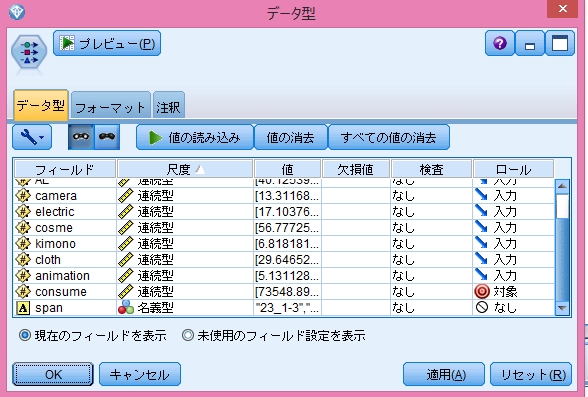
- モデル作成タブからKNN(=k近傍法)を追加します。
<図10>

データ加工タブから結合します。KNNノードをダブルクリックし、目的タブから最近傍のみを識別を選択します。
<図11>
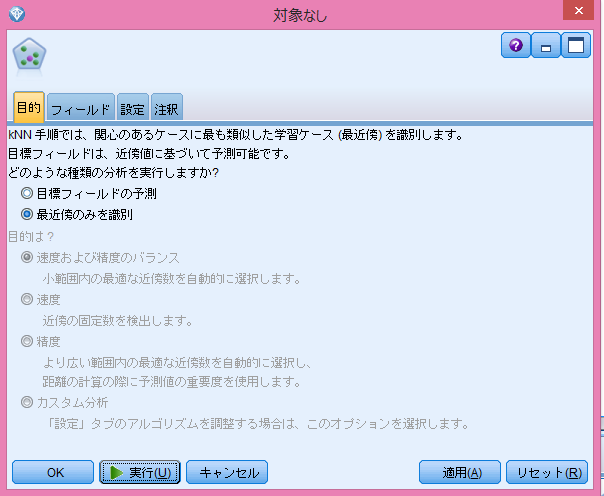
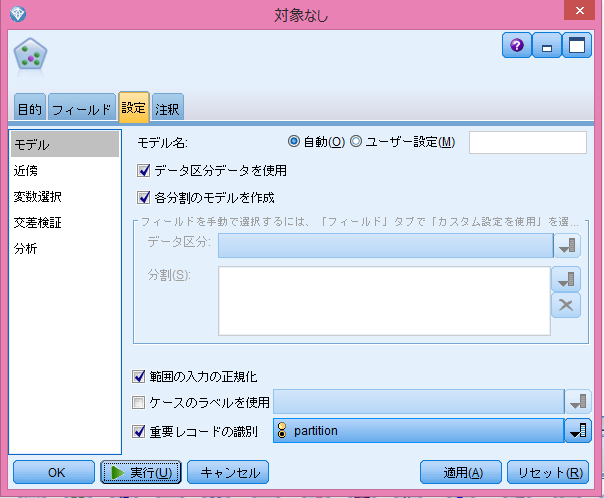
設定タブより、重要レコードの識別にチェックを入れ、プルダウンからデータ型を選択し、partitionを選択して実行!
<図12>
ちなみにここまででストリームは以下のようになります。
<図13>
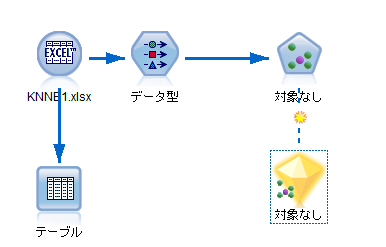
◉ 分析結果1
KNN分析の結果は以下になります!
<図14>
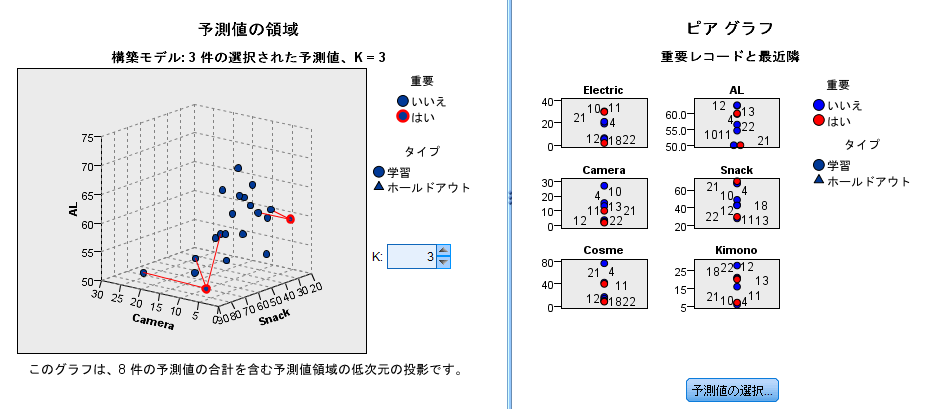
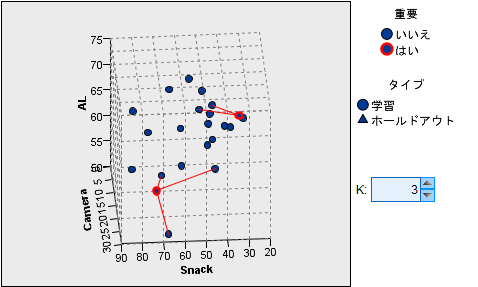
左側の3次元の図は回転させることができるので視覚的にどの項目がどの程度近いのか把握することができます。
<図15>
また、ピアのタブからピアを隣接および距離の表に変更すると、もっとも近い(似ている)ものがわかります。
これを読み解いていくだけでもなかなか興味深い結果が出てきます。たとえば、各国の消費行動には、以下のような類似性が見られました。*4
全20カ国のうち、フランス、スペインが似通っています。地理的に近い国なので気候などの影響でKimonoやClothesが似ているのは想像がつきますが、Animationが高水準で似ているのは興味深いです。
また、マレーシアとフィリピンにも強い類似性がみられます。特にCosmeやSnack、Clothesが似通っていることからフランス、スペインと同じく地理的に近いと文化や好みが似ているのかもしれませんね。
USとAUS、カナダはすべての品目で似通っているというわけではないですが、ALとKimonoでは高い水準で似通っており、英語圏の人には人気があるのでしょうか。
Kimono、Clothes、Animationは地理的に近いと、似通った数値をとることから、流行というものが伝わりやすい品目であることが推測でき、興味深い点でした。
さて、本題であるAreaAとAreaBの類似性の高い項目の考察に移りましょう!
KNN分析結果からの考察
<図16>
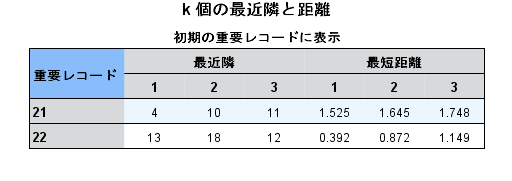
KNN分析では、partitionを1としたAreaAとAreaBの観光資源の割合に対して、partitionを0としたKorea(韓 国)からAUS(オーストリア)の20カ国それぞれの外国人の購買割合の距離が、それぞれ計算されています。距離が近いほど互いに似ているということにな ります。
まずはAreaA(=図16中の「21」が該当)を見ていきます。最近傍にあたるのは「4」=中国ですので、AreaAが提供する消費財は中国からの観光客に受けそうということになります。
各消費財ごとに、もっとも距離が近い最近傍のみを表示したのが以下の図です。
<図17>
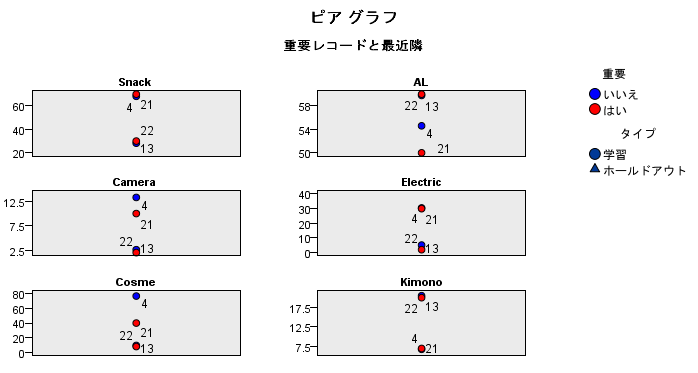
中国からの観光客の購入割合とAreaAでの観光客の購入割合をみると、Snack(菓子類)やElectric(電気製品)が高い水準で近い割 合をとっています。一方、Kimono(和服(着物)・民芸品)の距離は購入割合が低いものの近い割合で、両者が似ていることがわかります。Snackや 電化製品はAreaAの強みなので、それらを押し出していくことで多くの中国人観光客を獲得できると考えられます。
次にAreaBを見ていきます。最近傍は「13」=ドイツです。AreaBはAreaAに比べてAL( その他食料品・飲料・酒・たばこ)で強みを持っています。その分野で高い購入割合を持つドイツが一番AreaBの観光資源との親和性が高いということに なったようです。結果として、AreaBはドイツ人に対し食料品や飲料、酒、たばこを全面に押し出してPRするのが良いと考えられます。
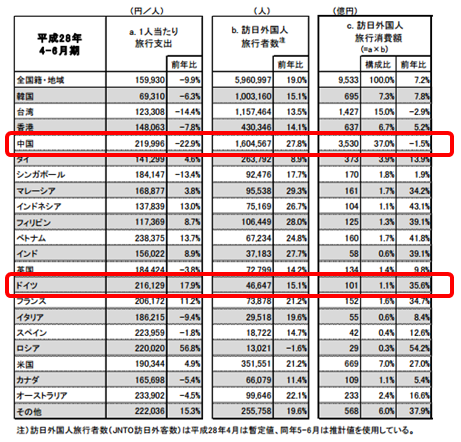
ここまででAreaAの最近傍が中国人観光客、AreaBの最近傍がドイツ人観光客であることがわかりました。距離をみると、AreaAと中国人 観光客は1.525であり、AreaBとドイツ人観光客は0.392となっていました。AreaBとドイツ人観光客の距離の方が近く、似ていることがわか りましたが、どこの国の人に爆買いをしてもらうともうかるのかという観点から、一人当たりの消費額が多く、訪日外国人旅行者数も多い中国人観光客の分析を AreaAにおいて引き続き行なっていきます。
<図18> 訪日外国人の国別旅行支出、旅行者数および旅行消費額
最近傍に対するアプローチ
ターゲットにするべき対象が分かったら、次は誘致のためのキャンペーンを検討することにします。ただし、キャンペーンを打つには多大なコストがか かります。そのためキャンペーンを打つからには高い確率で確実な収益を上げたいものですよね。そこで、今回はAreaAを例にとって最近傍である中国人観 光客を相手に何を買ってもらえるように訴求すれば一人当たりの平均購入額がさらに上がるのかを予測し、キャンペーンに活かすことにします。
なぜ、来訪者の出身地区の割合を使わないのか
ちなみに、ここまで読んで「なぜ、AreaAに来ている人の出身地別の割合を使って分析しないのか?」と思われる方もいらっしゃるかもしれません。もちろん、今回は架空の地域を分析しているため、そのような情報がないというのもあるのですが、ちゃんと理由があるのです。
そもそも、中国人観光客が断トツで多く来ていることが明らかな状況では、似ている地域などというものを考えずとも目の前の観光客に販売をしていれば 自然と中国人観光客の望むような品ぞろえになっていることでしょう。そうではなくて、様々な国の観光客が来ていて特徴がわからず、売上が伸び悩んでいる地 域だからこそ、いま当地を訪問してくれている外国人観光客が何に関心を持っているのか、どのような傾向にあるのか、データ分析をし、お客様を理解して販売 戦略を考えていく必要性が出てきます。さらに売り上げを伸ばしていくために、ターゲットを設定し、新たにキャンペーンを打っていくのです。
平均購入額向上のための予測分析手法
今回はシンプルに1人あたりの購入額を、これまで用いた購入割合で重回帰分析を用いて予測します。時系列データとして扱い、経済データなども集めればもっと精度をあげられそうですが、壮大な量になってしまうので割愛します。
使用するデータ
データ元は先程と同じ、観光庁の訪日外国人消費動向調査です。ここまでのKNNの分析でAreaAの最近傍が中国人観光客であることがわかりました。そのため中国人観光客の消費動向に関するデータを、3か月ごとのデータ22期分集めました。
右端の列のconsumeは一人あたりの平均購入額です。それ以外の変数の意味はKNNのときと同じです。
<図19> 中国人観光客の消費動向データ(3ヶ月区切り/消費カテゴリ毎)
分析フロー
ModelerではデータをKNNのときと同様読み込ませ、データ型で目的変数のConsumeのロールを対象にします。
<図20>
線形回帰のノードを追加し、データ型からつなげます。
線形回帰のノードで方法をステップワイズ法*5にします。
<図21>
ストリームは分析が終わると以下のようになります。
<図22>
僕たちが普段回帰分析を行うときはRを使うことが多いのですが、Rだとlm(y~x1+x2)でsummary, step, summaryと手順を踏まなければならないのに対し、Modelerだと1回で変数選択から要約まで出してくれるので、とても便利だと思いました!慣れるとModelerの方が早いと思います!
回帰分析の結果
では結果を見ていきます!
<図23>
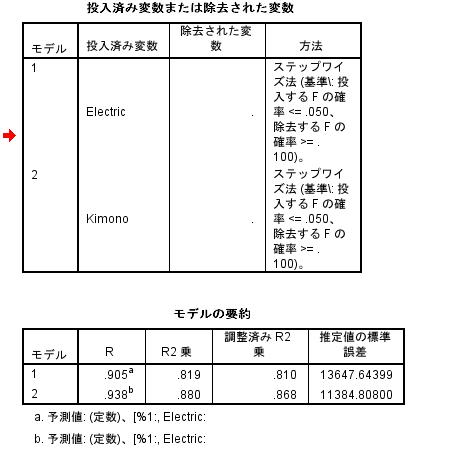
ステップワイズ法を使用したところ、変数としてElectric(電気製品)とKimono(和服(着物)・民芸品)が選ばれました。
<図24>

予測式として、
平均消費金額= 3931*Electric – 2306*Kimono + 25339
という結果が得られました。
考察
上の予測式はつまり、電気製品を買う人が1%増えると平均消費金額が3931円増え、和服(着物)・民芸品を買う人が1%増えると平均消費金額が2306円減少するということになります。
AreaAがターゲットとしたい中国人観光客との相性を見てみましょう。電気製品を買う人が1%増えると平均単価を99%有意水準で 3931円押し上げることがわかりました。購入割合を見ても、中国人観光客は電化製品で他国の観光客よりも高い購入割合を示していますから、中国人観光客 の電化製品を購入する意欲は高いと思われます。AreaAでは電化製品の販売は既に多いように見えますが、様々な国の人々が購入している中での販売量なの で、中国人観光客に向けてより電化製品のPRをすることで売り上げが伸ばせそうです。
逆に和服(着物)・民芸品目当てで来た人は平均消費金額を押し下げてしまうようです。そのうえ中国人の和服(着物)・民芸品の消費額は他国の観光 客に比べても低く、あまり求めていない傾向にあると言えます。AreaAにおいてもそこまで販売が多いわけではないですから着物などが特産品であるという 地域ではないでしょう。よって、AreaAにおいては着物や民芸品は売り上げを伸ばすためのPRには向かない品目だと考えられます。
キャンペーンやPRをするにはコストがかかることから、確実に消費額が伸びる品目である電化製品をPRしたいところです。
<まとめ>
<図25> 今回の分析にあたり作成したストリーム
今回はそれほど大きな元データを使わなかったため*6、 実は頑張れば目視でも分かるような結果だったのですがw、今回の分析よりももっと項目数が増えた場合、グラフを目視することだけではどの商品、製品が似て いるかを見つけるのは難しくなるでしょうし、このKNN分析を利用することで今まで気づかなかった競合や売り込み先、顧客を見つけられるかもしれません! さらに特筆すべきは、一度Modelerでまとめておくと、新しいデータが出た時に再度分析するのも簡単ですし、分析方法を研究室内の後輩に説明するのも 楽でした!ストリームを見せさえすれば再現が可能なので、まだ分析が不慣れな人でも私たちと同じ結果を得ることができます。また、複数人で作業をする時に も、お互いが何をやりたくて、何をやってきたのかを共有しやすいなと感じました。
予測に関しては、今回は単純な回帰分析でしたが、コードを書いて分析するRよりも簡単な手順で分析結果を出すことができました。ほかのモデルでもどの程度わかりやすく、かつシンプルに分析できるのか気になります。
Modelerには重回帰分析以外にも時系列モデルや、一般化線形モデルなどが用意されているので、次回は予測に重点を置いて分析していきます!
*3:観光庁のページ
*4:2016/9/3 各国の類似性の内容を書き換えました。上で提示している分析結果と少し異なる内容であったため。
*5:ステップワイズ法について少しだけ解説です:回帰分析において、変数を増やせば増やすほどモデルがデータをどれだけ説明しているかという説明力は増加します。目的変数には実際には関係のない変数を入れてもです。ですが、そのような変数によって予測しても有意義であるとは言えません。そこで求められること が、変数を一つ加えることに対してモデルが複雑になることと、どの程度モデルの当てはまりの良さが高まるのかを考慮して、その変数を加えるべきかを判断す る基準です。一般的にはAIC基準(赤池情報基準)という、元統計数理研究所所長の赤池弘次さんが1973年に発表した指標が使われています。それによって、ある変数を入れたほうが良いのか、入れないほうが良いのかを判断しています。AICがなるべく小さい値の方がよいとされています。
*6:今回はデモンストレーション目的で元データとして20行程度のcsvを 使いましたが、統計解析のモデル精度を担保するためには最低限100行くらいはあるべきで、ターゲット人数を考慮に入れたら統計的には384行は必要で しょうという指摘が先生からありました。これ以下の場合1%が与える影響が非常に大きくなってしまうそうです。次回以降気をつけます。
出典:【インバウンド消費も簡単に予測分析】データサイエンティストを目指す大学生のブログ>> http://ibm.biz/SPSS-modeler-blog
大学でデータサイエンス系のゼミに所属する学生さんに「外国人観光客のインバウンド消費」をテーマに予測分析を行ってもらいました。
SPSS Modeler マーケットプレイス/無料評価版はこちら
IBM SPSS総合製品カタログのダウンロードはこちら
More SPSS Modeler ヒモトク stories

DB2エキスパート座談会 ~ ClubDB2の舞台裏とDb2展望 ~
Db2, IBM Data and AI, アナリティクス
今年、IBM MQ と Db2 は 30 周年。WAS(WebSphere Application Server)は 25 周年を迎えます。アニバーサリー・イヤーとして 3 製品に関わりのある方々へのインタビューを 1 ...続きを読む

IBM SPSS Statistics 書籍紹介
Data Science and AI, SPSS Statistics, アナリティクス...
SPSS関連の書籍をご紹介します。 新刊紹介 SPSSとAmosによる心理・調査データ解析(第4版)―因子分析・共分散構造分析まで [著者] 小塩 真司 出版社] 東京図書 [内容] メニューを選択するだけ ...続きを読む

元技術理事に伺う Db2の軌跡と舞台裏
Db2, IBM Data and AI, アナリティクス...
今年、IBM MQとDb2は30周年。WAS(WebSphere Application Server)は25周年を迎えます。アニバーサリー・イヤーとして3製品に関わりのある方々へのインタビューを1年を通じて定期的に行っ ...続きを読む
