IBM Data and AI
実践!IBM Cloud Pak for Dataチュートリアル (MLOps and trustworthy AI後編)
2022年07月22日
カテゴリー Data Science and AI | DataOps | IBM Cloud Blog | IBM Data and AI | IBM Watson Blog
記事をシェアする:
前編からの続きです。
MLOps and trustworthy AI 前編はこちら→https://www.ibm.com/blogs/solutions/jp-ja/practice-cp4d-02/
3.チュートリアル2:モデルのテストと検証
概要
このチュートリアルでは、Data fabric trial のMLOpsとTrustworthy AIのユースケースを使用してデプロイされたモデルの評価とモニターを行います。目標は、Watson OpenScaleを使用して、どの申請者が住宅ローンの資格を得るかを予測するモデルを評価するためのモニタリングを構成します。この中で、Golden Bankの担当者はモデルが正確であり、すべての申請者が公平に扱われていることを確認します。チュートリアルのストーリーは、Golden Bankが、オンラインアプリケーションに低金利の住宅ローンの新しいサービスを提供することでビジネスを拡大したいと考えていることです。オンラインアプリケーションは、銀行の顧客範囲を拡大し、銀行の申し込み処理コストを削減します。Golden Bankのデータサイエンティストとして、予期しないリスクを回避し、すべての申請者を公平に扱う住宅ローン承認モデルを作成する必要があります。Jupyter Notebookを実行して、機械学習モデルのモニターをセットアップします。それらが意図したとおりに動作することを確認して、プロダクション(本番環境)に展開します。 これは、IBM Cloud Pak for Data as a Serviceを通じて実現されます。これらのサービスは、データへの信頼、モデルへの信頼、および AIを確実に運用するために必要なプロセスです。
このチュートリアルでは、これらのタスクを実施します。
3-1. Notebookを実行してモニターをセットアップ
3-2. モデルを評価
3-3. モデルモニターの品質を観察
3-4. モデルモニターの公平性を観察
3-5. 説明性についてモデルモニターを観察
3-6. モデルをプリプロダクション(検証環境)にプロモートし、モデルを承認
3-1.Notebookを実行してモニターをセットアップ
サンプルプロジェクトに含まれるNotebookを実行して、モデルをWatson OpenScaleに登録します。手動で設定も可能ですが、Notebookで設定する方が早く、エラーも少なくなります。このチュートリアルは設定方法のガイドが目的ではなく、OpenScaleでモニタリングされた結果を確認することが目的のため、手動での設定方法の手順は割愛しています。
1.Cloud Pak for Dataのナビゲーションメニューから、[プロジェクト] > [すべてのプロジェクトの表示]を選択します。
2.[MLOps and Trustworthy AI]プロジェクトを開きます。
3.[資産]タブで、[ソース・コード] > [Notebook]をクリックします。[2-monitor-wml-model-with-watson-openscale] Notebookを開きます。
(1-model-training-with-factsheets Notebookでは、Mortgage Approval Prediction Model をトレーニングし、WML を使用してデプロイしました。[2-monitor-wml-model-with-watson-openscale]では、プログラムによるWatson OpenScale のセットアップ、モデルのデータマートの作成、展開、監視、そして OpenScale のインサイトダッシュボードで表示するレコードと測定値の挿入を行います。OpenScaleでモデルを監視するには、リレーショナルデータベースにアクセスする必要があります。データベースはPostgresのデータベースを使用します。)
4.Notebookが読み取り専用になっているので、鉛筆のアイコンをクリックして、Notebookを編集モードにします。※タイトルの前にあるセルは削除します。

5.Notebookの上部にある指示に従って、プロジェクト・トークンをインポートします。[その他] メニューから「プロジェクト・トークンの挿入」を選択します。
これにより、プロジェクト・トークンを含む新しいセルがNotebookの最上部に挿入されます。
6.[Insert IBM Cloud API key] セクションで、ibmcloud_api_key フィールドに API キーを貼り付けます。(ダウンロードしたファイルからコピー&ペースト)
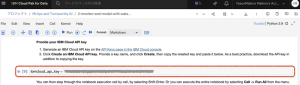
7.Notebook内のすべてのセルを実行するには、[Cell] > [Run All] をクリックします。また、各セルとその出力を調べたい場合は、Notebookをセルごとに実行することもできます。
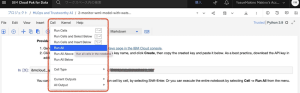
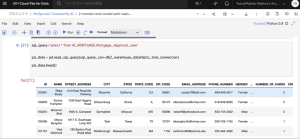
8.Notebookが完成するまでには、1〜3分かかります。アスタリスク「In [*]」が「In [1]」のように数字に変わることで、セルごとの進行状況を確認できます。(Out[21]はデータの一部をプレビューした様子)
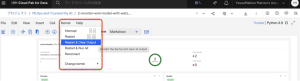
9.Notebook実行中にエラーが発生した場合は、「Kernel」>「Restart & Clear Output」をクリックしてカーネルを再起動し、Notebookを再実行してください。
3-2.モデルを評価
ホールドアウトデータをダウンロードし、そのデータを使用してWatson OpenScaleでモデルを評価します。
1.「MLOps and Trustworthy AI」プロジェクトをクリックします。
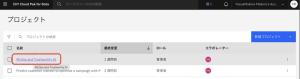
2.[資産]タブで[データ] > [データ資産]をクリックします。csvデータ資産をクリックします。
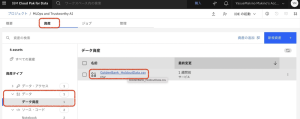
3.csvデータ資産の[Overflow]メニューから、[ダウンロード]を選択します。モデルが要求通りに動作しているかどうかを検証するためには、モデルの学習から外れたラベル付きのデータセットが必要になります。このCSVファイルには、検証のためのホールドアウトデータが含まれています。
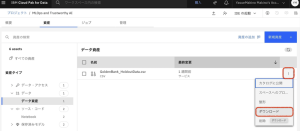
4.Watson OpenScaleを起動するには、IBM Cloud Pak for Dataのナビゲーションメニューから、[サービス]> [サービス・インスタンス]を選択します。
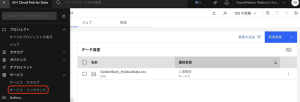
5.[Product] ドロップダウン ボックスを使用して、既存の Watson OpenScale サービス インスタンスを確認します。Watson OpenScale インスタンスをクリックします。プロンプトが表示されたら、Cloud Pak for Data のサインアップに使用したのと同じ認証情報を使用してログインします。
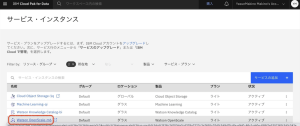
6.Watson OpenScale サービス インスタンス ページで、[アプリケーションの起動] をクリックします。
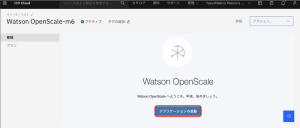
7.ブラウザの別タブで洞察ダッシュボードが開きます。洞察ダッシュボードで、[Mortgage Approval Model Deployment] タイルをクリックします。
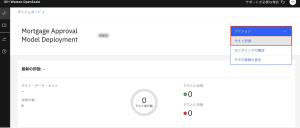
8.[アクション] メニューから、[今すぐ評価] を選択します。
9.テスト・データのインポートでインポートのオプションの選択から、[CSV ファイルから] を選択します。
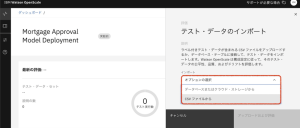
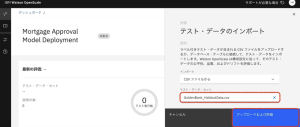
10.プロジェクトからダウンロードした[Golden Bank_HoldoutData.csv]データファイルをサイドパネルにドラッグします。[アップロードおよび評価]をクリックします。
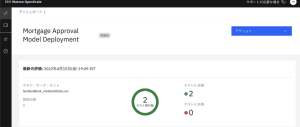
11.評価が完了すると、テストに合格、またはテストに失敗の何れかが表示されます。以下の画面は2回評価し、2回ともテストに合格したという意味になります。
3-3.モデルモニターの品質を観察
ホールドアウトデータを用いた評価が終了したらモデルの品質や精度をモニターします。
1.左側のナビゲーションパネルで、[洞察ダッシュボード]アイコンをクリックします。
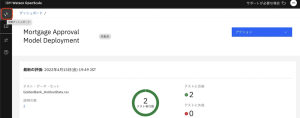
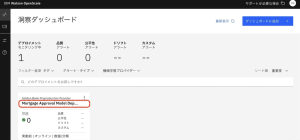
2.[Mortgage Approval Model Deployment]タイルを見つけます。問題が0件であること、品質テストと公平性テストの両方が合格していること、つまり、モデルが要求されるしきい値を満たしていることに注意してください。
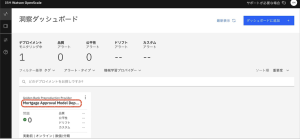
3.詳細を見るには、Mortgage Approval Model Deployment タイルをクリックします。以下はクリック後に表示される画面です。
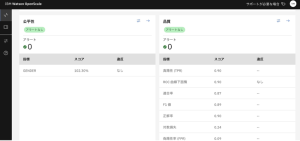
4.[品質]セクションで、[設定]アイコンをクリックします。
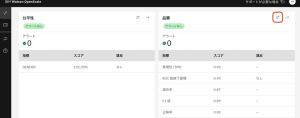
5.ここでは、このモニターに設定された品質しきい値が70%であり、使用されている品質の測定が ROC 曲線の下の面積であることがわかります。
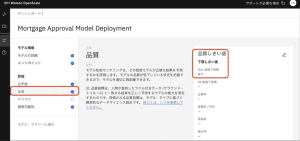
6,モデルの詳細画面に戻るには、[モデル・サマリーに進む]をクリックします。
7.モデル品質の詳細結果を見るには、[品質]セクションで、右矢印アイコンをクリックします。
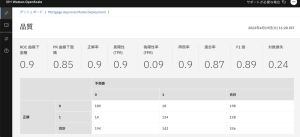
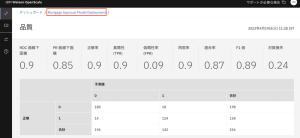
8.このページでは、多くの品質メトリックの計算と、正しいモデル決定と偽陽性および偽陰性を示す混同行列が表示されます。計算された ROC 曲線下の面積は0.9 以上で、閾値の 0.7 を大きく上回っているため、このモデルは品質要件を満たしていることになります。
9.モデルの詳細画面に戻るには、[Mortgage Approval Model Deployment ]をクリックします。
3-4.モデルモニターの公平性を観察
モデルの公平性をモニターします。
1.「公平性」セクションで、[設定]アイコンをクリックします。
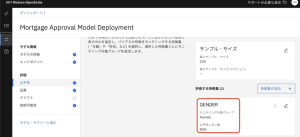
2.このページでは、申請者が性別に関係なく公平に扱われているかどうかを確認するために、モデルの見直しが行われていることがわかります。女性は、公平性を測定する監視対象グループとして特定され、公平性の閾値は80%以上であることが求められています。公平性モニターは、公平性を判断するために、格差影響法を使用しています。
3.モデルの詳細画面に戻るには、[モデル・サマリーに進む]をクリックします。
4.モデルの公平性の細結果を見るには、[公平性]セクションで、右矢印アイコンをクリックします。
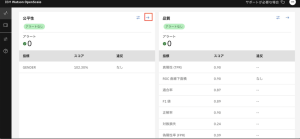
5.このページでは、自動承認されている男女の申請者の割合と、100%を超える公平性スコアが表示されており、モデルは必要な公平性基準値80%をはるかに上回るパフォーマンスを見せています。
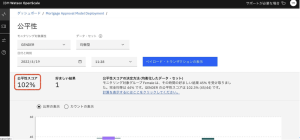
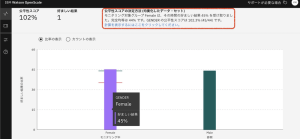
6.画面上部に表示されているデータセットに注目してください。公正さの指標を可能な限り正確にするために、実際のモデル予測に加えて、Watson OpenScale は摂動を使用して、保護された属性と関連するモデル入力のみを変更し、他の機能はそのままの結果を判断しています。これらの追加のガードレールは、[均衡型]データセットを使用した場合の公平性を計算するために使用されますが、[ペイロード]またはモデルの[訓練]データのみを使用して公平性の結果を表示することも可能です。モデルは公正に動作しているため、この指標についてさらに詳しく調べる必要はありません。
7.モデルの詳細画面に戻るには、[Mortgage Approval Model Deployment ]をクリックします。
3-5.説明性についてモデルモニターを観察
モデルがどうしてそのような判断に至ったかを理解することも重要です。これは、融資の承認に関わる人々に判定を説明するためと、モデルの所有者に判定が有効であることを保証するために両方。これらの判定を理解するために、モデルの説明可能性をモニターします。
1.左のナビゲーションパネルで、[トランザクションの説明 ]アイコンをクリックします。
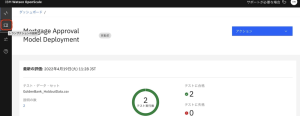
2.[Mortgage Approval Model Deployment ]を選択すると、デプロイされたモデルのトランザクションのリストが表示されます。
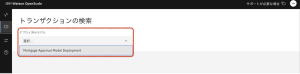
3.任意のトランザクションについて、[アクション] 列の下の[説明] をクリックします。
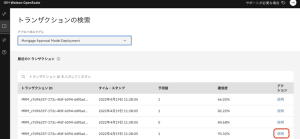
4.このページでは、この予測結果の詳細な説明が表示されます。モデルへの最も重要な入力フィールドと、それぞれが最終結果に対してどの程度重要であったかが表示されます。
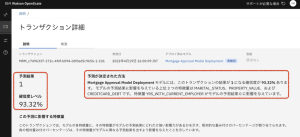
5.下の方にスクロールすると、グラフが確認できます。青のバーは、モデルの予測結果をサポートする傾向がある 入力を表し、紫のバーは、別の予測結果につながったかもしれない入力を表します。例えば、ある申込者は、十分な収入があり審査に通ったとしても、クレジット履歴が悪く、負債が多いため、モデルは申込を拒否することになります。この説明を確認し、モデルの予測結果の根拠について把握します。
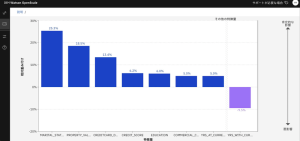
6.モデルがどのように判断したかをさらに詳しく知りたい場合は、[検査]タブをクリックします。
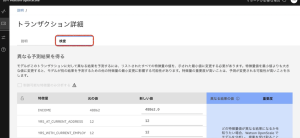
7.このページでは、予測結果を分析して、いくつかの入力にわずかな変更を加えるだけで異なる予測結果になるような敏感な領域を見つけることができます。また、実際の入力のいくつかを代替の値で上書きして、それが結果に影響を与えるかどうかを確認することによって、自分でテストすることもできます。
3-6.モデルをプリプロダクション(検証環境)にプロモートし、モデルを承認
モデル・インベントリーのモデル・エントリーのステータスを確認します。更新されたモデルを承認することで、ステータスが承認済みになります。このようにモデルのライフサイクルが管理されることを確認してください。
1.Cloud Pak for Dataのナビゲーションメニューから、[カタログ] > [モデル・インベントリー]を選択します。

2.Mortgage Approval Modelエントリについて、[詳細の表示] をクリックします。
3.[資産]タブをクリックします。
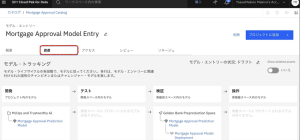
4.[モデルトラッキング] の下で、モデルが現在 [検証] 段階にあることが確認できます。
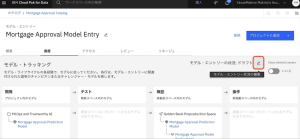
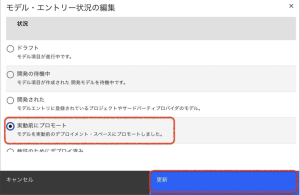
5.モデル・エントリーのステータスの横にある鉛筆のアイコンをクリックし、[実働前にプロモート]を選択し、[更新]をクリックします。
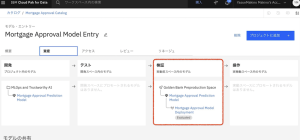
6.Watson OpenScale Insights ダッシュボードに戻ります(ブラウザの別タブ)。[Mortgage Approval Model Deployment] タイルをクリックします。
7.[アクション] メニューから [実働の承認] を選択し、[承認] をクリックします。これにより、AI 運用チームに、指定された本番スペース(このシナリオでは、実動前環境(検証環境))にモデルをデプロイできるようになっています。
承認後は、以下のようにメッセージが表示されます。
8.モデル・インベントリーの表示に変更があるか確認しましょう。ブラウザの別タブで開いているIBM Cloud Pak for Data のページのメニューから[カタログ] > [モデル・インベントリー]を選択します。

9.Mortgage Approval Modelエントリの、[詳細の表示] をクリックします。
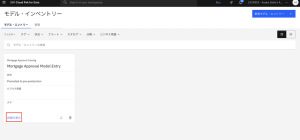
10.[資産]を選択します。「Approved」が表示されていることが確認できます。
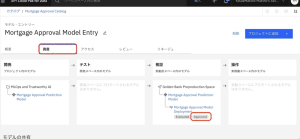
このように、モデルの更新を承認して、実働前環境(検証環境等)や実動環境(本番環境)にプロモートし、承認を経て実稼働する等のモデルのライフサイクルをモデル・インベントリーで管理、運用するプロセスを実現することが可能となります。
4. 終わりに
以上がData fabricのチュートリアルの中の「MLOps and trustworthy AI」でした。このチュートリアルで以下を体験できました。
チュートリアル1:モデルのビルドとデプロイ(Build and deploy a model):
①サンプルの活用
- 「Gallery」からサンプルプロジェクトを検索し、インポートしてプロジェクトを作成しました。
- プロジェクトの中にあるNotebookを実行してモデルを作成しました。
②モデルのトラッキングの設定
- モデルのライフサイクルのトラッキングをするために、カタログ機能の拡張であるモデル・インベントリーを作成しました。
- モデルのライフサイクでモデルがまだ「開発」段階であることを確認しました。
③モデルのデプロイ
- モデルを実行できるようにデプロイするとモデル・インベントリーで、モデルのライフサイクルが「テスト」に移動することを確認しました。
チュートリアル2:モデルのテストと検証(Test and validate the model):
①Notebook実行によるOpenScaleのセットアップ
- プロジェクトの中にあるNotebookを実行してOpenScaleにモデルを登録しました。
- テストデータを読み込み、モデルの品質等を評価しました。
②モデルの品質、公平性、説明性の確認
- モデルの品質が閾値を超えて品質が高いこと、公平性も担保されていることを確認しました。
- ローン審査において、重要視されている値を確認しました。どの値が異なる結果につながるか確認しました。(説明性)
③モデルの承認(MLOpsライフサイクルの確認)
- モデルを実働前環境(検証環境)で稼働することを承認しました。
- 実働前環境(検証環境等)や実動環境(本番環境)にプロモートし、承認を経て実稼働する等のモデルのライフサイクルをモデル・インベントリーで管理、運用することができることを確認しました。
以上が、「MLOps and trustworthy AI」のチュートリアルでした。チュートリアル全般についてはこちらでご紹介しています。同シリーズでMulticloud data integrationのチュートリアルもございます。是非、Data Fabricの他のチュートリアルもお試しいただき、Cloud Pak for Dataでデータ活用を一気通貫で実行する流れをご体験ください!ありがとうございました。

牧野 泰江
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

斉藤 明日香
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

セキュリティー・ロードマップ
IBM Cloud Blog
統合脅威管理、耐量子暗号化、半導体イノベーションにより、分散されているマルチクラウド環境が保護されます。 2023 安全な基盤モデルを活用した統合脅威管理により、価値の高い資産を保護 2023年には、統合された脅威管理と ...続きを読む

量子ロードマップ
IBM Cloud Blog
コンピューティングの未来はクォンタム・セントリックです。 2023 量子コンピューティングの並列化を導入 2023年は、Qiskit Runtimeに並列化を導入し、量子ワークフローの速度が向上する年になります。 お客様 ...続きを読む