SPSS Statistics
SPSS Statistics Small Tips #09リスク予測に活用できるロジスティック回帰分析~ SPSS Regression ~
2022年04月11日
カテゴリー IBM Data and AI | SPSS Statistics | アナリティクス | データサイエンス
記事をシェアする:
ロジスティック回帰分析
ロジスティック回帰は、従属(目的)変数がカテゴリカルなデータの予測や要因分析に利用する回帰分析のひとつです。たとえば、契約の解約や病気の罹患、信用リスクのランクなどの事象が起こる確率を求め、その確率により「解約する」か「解約しない」かを予測します。また、予測に対して何が影響しているかを読み解きます。
ロジスティック回帰分析の実行には、SPSS Statistics Regressionが必要です。
線形回帰では、対象となる従属変数yが連続値なので直線の1次式
![]()
をデータに当てはめますが、ロジスティック回帰では、従属変数がカテゴリ値なので、S字形のシグモイド曲線
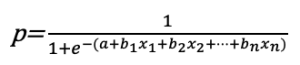
を当てはめ、従属変数yが起こる確率pを求めます。

このシグモイド曲線の式は変形すると
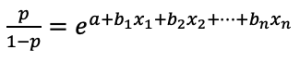
と表すことができます。左辺のpは事象が起こる確率で、1−pは事象が起こらない確率であることから左辺はオッズを表します。右辺のそれぞれの独立変数xの係数bは、オッズへの影響になります。ちなみに、自然対数の底eは2.72です。
では
![]()
の式における係数bの解釈を順を追って説明します。ここでは、わかりやすいように独立変数xは1つとし、値は0か1のデータとします。
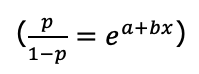
xが0の場合、オッズは『ea』です。xが1の場合、オッズは『ea+b』で、『ea×eb』とも表現できます。つまり、xが1増加するとオッズは『eb』変化することがわかります。このオッズの変化をオッズ比といいます。
たとえば、bが0の場合、オッズ比が1(e0=1)なので、x=1のオッズとx=0のオッズは等しく、その独立変数xはオッズに影響を与えません。b>0の場合、オッズ比が1より大きくなるため、x=1のオッズは、x=0のオッズよりも大きくなります。つまり、事象が発生する確率はx=0の場合よりもx=1の場合の方が大きくなります。逆に、b<0の場合、オッズ比が1より小さくなるため、x=1のオッズは、x=0のオッズよりも小さくなります。つまり、事象が発生する確率は、x=0の場合よりもx=1の場合の方が小さくなります。
ここまで、係数の解釈について説明をしてきましたが、SPSS Statistics Regressionのロジスティック回帰では『eb』(Exp(b):エクスポネンシャル ビー)を算出します。『eb』は、オッズ比を表すので、事象に対して何倍の影響(またはリスク)があるかがわかります。
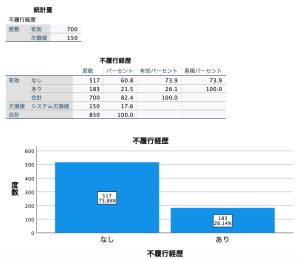
では、実際にデータを使ってロジステック回帰分析を行ってみます。ここでは、製品に同梱されているbankloan.savデータを使用します。このデータは銀行業務で債務不履行率を低減させるための模擬データで、既存の顧客と見込み客850人に関する財務情報と人口統計情報が含まれています。最初の700ケースは、以前に貸付を行った既存顧客、残りの150ケースが見込み顧客です。

変数「不履行」のデータの分布を確認します。不履行経歴「あり」が、全体の26.1%です。
分析メニュー > 回帰 > 二項ロジスティックを選択します。
従属変数が2値の場合には、二項ロジスティックを従属変数が3値以上の場合には多項ロジスティックを選択します。2値の場合でも多項ロジスティックを実行することができますが、二項ロジスティックのアウトプットの方がシンプルで読み解きがしやすいのでお勧めです。
①従属変数に、変数「不履行」を指定します。独立変数となる②ブロックに「年齢」から「その他負債」を指定します。変数選択の方法③方法では変数増加法:尤度比を選択します。方法には、6種類のステップワイズ法が用意されています。一般的に尤度比の利用が推奨されています。理由は、モデル式の有意性の判断に尤度比が利用されているためです。予測確率と予測値をデータエディタに保存するため、④保存ボタンをクリックして、⑤予測値の確率と所属グループを選択します。
次に、出力情報を追加するため⑥オプションボタンをクリックします。

母集団の傾向を把握するため、オッズ比の95%信頼区間を算出する⑦Expの信頼区間を選択します。また、ステップワイズ法の結果は冗長的になることを回避するため⑧表示の最後のステップを選択します。

実行結果を参照します。さまざまな出力が表示されますが、基本は、ブロック1を参照します。出力ウィンドウのアウトライン(出力ウィンドウの左側の目次の部分)で参照したい項目をクリックすると、内容(出力ウィンドウの右側の表やグラフの部分)がスクロールされ参照できます。

モデル係数のオムニバス検定は、モデルの有意性を評価します。有意確率から5%水準で有意であることが読み取れます。つまり、このモデルは統計的に意味があることを示します。
また、モデルの要約では、擬似R2乗を表示してモデルの適合性の評価に使用します。Nagelkerkeの値は0〜1の範囲をとるので、1に近いほど当てはまりがよいことを意味します。この値は、低く出やすいため参考程度に見ておくのでよしとされています。分類テーブルは、混同行列です。それぞれのカテゴリの正解率と全体の正解率を算出します。今回のターゲットの不履行経歴「あり」は50.3%の正解率となっています。
方程式中の変数テーブルを見てみましょう。
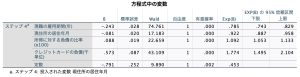
ステップ4は、変数選択のステップワイズ法が4回で収束したことを意味します。そして、最終的に選択された独立変数が「現職の雇用期間」、「現住所の居住年月」、「所得に対する負債の比率」、「クレジットカードの負債」になります。Bの列が係数です。符号から従属変数への影響方向性はつかめます。ロジスティック回帰では、Exp(B)のオッズ比で独立変数の影響力を評価します。「クレジットカードの負債」のオッズ比が1.774となっています。これは、負債が千円増えると、不履行のリスクが1.774倍になることを意味します。「現職の雇用期間」のオッズ比は0.785のため、雇用期間が1ヶ月増えると、不履行のリスクが0.785倍になることを意味します。
Exp(B)の95%信頼区間は、母集団におけるオッズ比の範囲です。この範囲に「1」が含まれる(オッズ比=1の可能性がある)と、母集団において独立変数の影響がないことを意味します。
では、最後にデータエディタウィンドを見てみましょう。

新しく予測確率変数「PRE_1」と予測カテゴリ変数「PGR_1」の変数が追加されました。デフォルトでは、確率0.5を境界値として、上回っていれば1:「あり」、下回っていれば0:「なし」と予測します。
また、予測モデルの算出に従属変数の「不履行」が未入力のデータは使用されませんので、同じデータファイルに既存顧客と見込み顧客のデータが混在していても問題ありません。既存顧客のデータから算出された予測モデルから見込み顧客の予測ができました。
まとめ
いかがでしたか。SPSS Statistics Regressionのロジスティック回帰分析は、カテゴリデータ、特に2値のデータを予測する際にさまざまな分野で利用されている手法です。みなさまの業務でもきっとご利用いただける場面があるのではないでしょうか。
さあ、さっそくはじめてみませんか。
SPSS Statistics 無料評価版 https://www.ibm.com/jp-ja/products/spss-statistics
お問い合わせは SPSS営業部まで jpsales@jp.ibm.com
→SPSS Statistics Small Tips バックナンバーはこちら

牧野 泰江
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

テクノロジーが向かう先とは〜中長期テクノロジー・ロードマップ
IBM Cloud Blog, IBM Data and AI
IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む