SPSS Modeler ヒモトク
ブログで学ぶSPSS_Modeler #03- データのクレンジングにトライ!法人のお客様を名寄せする
2022年03月07日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:

IBM山下です。
今回はSPSS Modelerで法人のお客様を名寄せするためのTipsを、具体的な例を交えて解説します。
1000件の法人お客様リストがあったとして、それは本当に1000社でしょうか。同一企業がリストに何度も重複して含まれていないでしょうか。そのデータをそのまま分析に使ってしまうと、本来の分析結果が出せません。また、1社に何通もDMを送ってしまう、といった結果になってしまうこともあります。分析の前処理として、できるだけ1企業は1件に統合しておきたいところです。このような処理を「名寄せ(なよせ)」といいます。
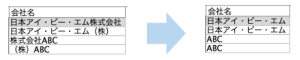
名寄せは、法人名が同じレコードを一つにする、という単純な処理ではなかなかうまくいきません。例えば、法人名には表記の揺れがよくあります。「日本アイ・ビー・エム株式会社」「日本アイ・ビー・エム(株)」「日本IBM㈱」といった具合です。このような表記の揺れやデータ欠損などをうまく処理して名寄せするためのTipsを3つご紹介します。
『株式会社』『 (株)』の表記を削除
法人名表記には「株式会社」が前後につく場合が多いですよね。
「株式会社」「(株)」「㈱」などの表記の揺れをもっとも簡易に吸収する方法はそれ自体を削除してしまうことです。
SPSS Modelerの[置換]ノードで[replace]関数を使うと、以下のように簡単に削除できます。
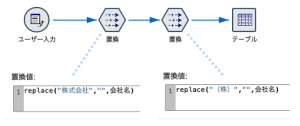
[if]などの制御構造を使うと、1ノードで様々な表記をまとめて削除できます。

辞書(社名マスタ)を使う
表記揺れ以外にも、以下のように名称自体にバリエーションがあります。
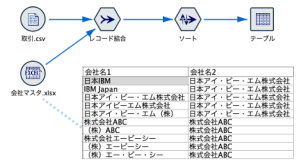
このような表記の揺れを吸収するには、手間はかかってしまいますが、辞書を作って突き合わせる方法が現実的です。
以下の処理例では「会社マスタ.xlsx」を辞書として、分析データ「取引.csv」と突き合わせて、法人名を統一しています。
レコード結合ノードでは[部分外部結合]で、辞書ではないほうのデータにチェックを入れてください。
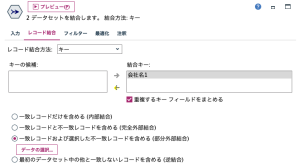

こうすることで、辞書にない会社名が「取引.csv」に含まれていても、結合できます。
以下の最後の行のように、辞書でカバーできていない会社名があれば簡単に判別できます。
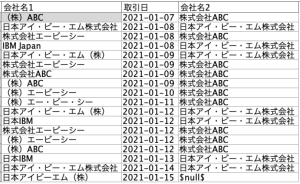
「会社マスタ.xlsx」は別途Excelなどでメンテナンスします。
上記の方法で、辞書でカバーできていない法人名をチェックして、適宜辞書に加えて徐々に辞書を充実させていくことができます。
複数項目を使った条件結合
別企業で法人名が同じ場合もありますので、メールアドレス・電話番号・郵便番号など他の項目も名寄せに使うことが有効です。ただし、名寄せに使う全ての項目が漏れなく入力されていれば良いのですが、一部が欠けているだけでうまく名寄できません。もう少し柔軟な条件設定が必要です。
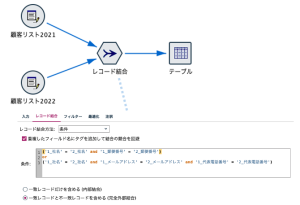
以下の処理例では、レコード結合ノードを使って2021年のリストと2022年のリストを名寄せしています。以下(1)(2)のいずれかが満たされた場合に名寄せするように設定しています。
(1) [会社名]と[郵便番号]が一致した場合
(2) [会社名]と[メールアドレス]が一致した場合
[and][or]をうまく組み合わせることによって、幅広く名寄せをすることができています。
まとめ
今回はSPSS Modelerのデータ加工機能を使って法人の名寄せをするTipsをご紹介しました。
厳密に名寄せしようとすると、市区町村合併や企業合併に伴う変更や新旧対応など、他にも注意点がいろいろあります。業務によっては、万が一名寄せに間違いがあって、お客様の個別情報を他のお客様へ公開してしまうようなことがあっては大変です。そのような業務で使うお客様リストの名寄せには、やはり専門の名寄せソリューションを使って、それなりの手間と時間をかける必要があります。
ただ、お客様リストが整備されるのを待っていると、いつまでたっても分析が始められません。以下のように、名寄せにそこまでの精度が求められない場合もあります。
・どのようなお客様の割合がどれほどいるか、といった個別のお客様を識別しない分析を行う
・パーソナライズされていない一律のDMを送る
今回ご紹介したような方法で、分析の一環として名寄せを手早く行ってしまうのも、一つの選択肢です。目的に応じた適切な手段を選ぶことで、効率的に分析を進めましょう。
次回ブログで学ぶ#04は4月初旬にスマートアナリティクスの畠さんが登場。SPSS Modeler の18.2で搭載された新グラフ機能を解説します。
そして身近な疑問にヒモトク連載#03では3月下旬にIBM盛武さんが「What-if」について執筆されます。
どちらもお楽しみに!
→これまでのSPSS Modelerブログ連載のバックナンバーはこちらから
→SPSS Modelerノードリファレンス(機能解説)はこちらから

山下 研一
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む