IBM Cloud Blog
第9回『サーバーレスとバッチ処理の運命的な出会い』
2021年12月24日
カテゴリー IBM Cloud Blog | IBM Partner Ecosystem
記事をシェアする:
コンテナオーケストレーション環境であるKubernetesを利用して得られるメリットとして何が思いつくでしょうか?
良く聞く中には、コンテナ(Pod)がダウンした際に自動復旧する、複数のコンテナが分散配置されることで、Worker Node障害時の可用性確保に繋がるといった話があります。
一般的にコンテナで構成されるようなWebサーバやアプリケーションサーバは常に処理できることを求められるため、コンテナでは常駐することが望まれます。
従って、Kubernetesのメリットを考えた時にオンライン処理を受け持つような常駐するコンテナに関連する機能が思いつきやすいです。
ところで、Kubernetesでバッチ処理は可能なのでしょうか?
語られることは決して多くないですが、もちろん可能です。
では、どのように実現するものでしょうか?
Job
Jobはコンテナを利用して、一度限りの処理を実行させるものです。詳細には、指定した並列数で処理されて、指示した成功回数に達するまでコンテナが何度も起動します。Replicasetも複数のコンテナが常時展開されることを定義するものですが、違いはJobがコンテナが停止することを前提にしている点です。コンテナの停止が正常終了と期待される用途で用いられます。例えば「Object Storageへのファイルのアップロード」「特定のサーバとのrsync」などが挙げられます。
Kubernetesでは、Jobを以下のように定義します。
kind: Job
metadata:
name: sample-job
spec:
completions: 1
parallelism: 1
backoffLimit: 10
templete:
spec:
containers:
– name: job-container
image: xxx/yyy:zzz
restartPolicy: Never
Jobのマニフェストでは、 spec.templete.spec.restartPolicy に、 onFailure か Never のどちらかを指定する必要があります。上記のように Never を定義すると、コンテナの障害時には新しいコンテナが作成されます。 onFailure の場合は、再度同一のコンテナを利用してJobを再開します。
こちらでは、成功回数を指定する completions と並列数を指定する parallelism を 1 で指定していますが、デフォルト値が1なので、明示的に指定しなくても同様に動作します。backoffLimit は失敗を許容する回数を指定します。
CronJob
CronJobはJobに似たもので、スケジュールされた時間にJobを作成します。
例えば5分置きに実行するCronJobを定義してみましょう。
kind: CronJob
metadata:
name: sample-cronjob
spec:
schedule: “*/5 * * * *”
concurrencyPolicy: Allow
startingDeadlineSeconds: 60
successfulJobsHistoryLimit: 5
failedJobsHistoryLimit: 3
suspend: false
jobTemplate:
spec:
completions: 1
parallelism: 1
backoffLimit: 10
templete:
spec:
containers:
– name: job-container
image: xxx/yyy:zzz
restartPolicy: Never
先ほどのJobの定義が、CronJobだとjobTemplateに記述されていますが、それ以外にも設定がいくつか増えましたね?
spec.concurrencyPolicy は同時実行の制御を定義する部分で、Allow は何も気にせず5分経つと次のJobをスケジュールします。 Forbid を指定すると前のJobが終了していない場合はスケジュールしないようにすることができます。 Replace を指定すると、前のJobが終了していなかった場合、それをキャンセルし、新しいJobをスケジュールします。
CronJobはMaster NodeがJobを作成することで、Worker Nodeにコンテナがスケジュールされます。つまりMaster Nodeが何らかの理由でダウンしていた場合やネットワークトラブル等で、開始を指定した時間にJobが起動できないことも考えられます。これに対して spec.startingDeadlineSeconds で秒数を指定することで、CronJobで指定した時間で起動しなくても、この秒数以内であればJobの起動をリトライします。
spec.successfulJobsHistoryLimit には 5 、failedJobsHistoryLimit には 3 を指定していますが、これはそれぞれJobの成功回数と失敗回数をKubernetes上に保存しておく履歴数を指定しています。こちらを指定していなかった場合、CronJobで定義されたJobは成功、失敗に関わらず終了したこととなり、Jobの情報が消えて、また紐づいていたコンテナ(Pod)の情報も消えます。その結果、異常終了していたとしても、コンテナからどのようなログが出力されたのか、コンテナがKubernetes上でどのような状態であったのか、といった調査が難しくなります。従って、履歴数でいくつかのJobの履歴を残しておくことで、処理に問題無かったか、Kubernetes上で問題が無かったか、ということを後から確認することができます。
5分毎に実行されるCronJobを定義していますが、しばらく処理を止めたい、ということもあるでしょう。もちろんManifestの spec.suspend を true に変更して、 kubectl apply することで一時停止することが可能ですが、 kubectl patch cronjob sample-cronjob -p ‘{“spec”:{“suspend”:true}}’ のコマンドで一時停止させることも可能です。
これらのJob、CronJobの設定を駆使して、Kubernetes上でバッチ処理を動かすことが可能です。
実際どうなのか
もちろん、Kubernetesで既にコンテナ化しているサービスと連携したバッチ処理を実行する上では、JobやCronJobの仕組みを利用することは非常に有用です。
しかし、既にKubernetesのワークロードは、コンテナ化したシステムで溢れている時に、定期的、もしくは不定期に実行されるJobが実行するに足るリソースは正しく確保できているでしょうか?常駐するコンテナが使用するWorker Nodeのリソースは計算管理しやすいですが、そこに常駐しないコンテナの利用リソースを加味すると管理は非常に複雑になりますし、またKubernetes上のJob、CronJobを管理する製品もまだ多くは出ていないのが現状です。
下手すると、規模の大きいJobがスケジュールされて、Worker Nodeの1つがOut of Memoryを発生させ、Node全体のコンテナがスローダウン、もしくはダウンすることになるかもしれません。とはいえ、不定期に実行されるJobのためにシステムリソースを確保し続けると、せっかくコンテナ化したシステムの集約性が乏しくなり、コンテナ化のメリットを十分に享受できないことも考えられます。
必要な時に、必要なリソースだけ確保するようなコンテナの実行環境は無いのでしょうか?
必要なときに必要なだけ利用できるCode Engine
IBM Cloud では、クラスタ管理・インフラ管理することなく、必要なときに必要なリソースだけご利用いただけるサーバーレス・プラットフォームとしてCode Engineが利用できます。Code Engineはバッチ処理だけではなく、ウェブ・アプリケーションやREST API、イベント駆動型のワークロードなど様々なワークロードに対応しています。
バッチ処理をCodeEngineで動かす3つの理由
- インフラ管理・クラスタ管理なし
Kubernetes上でJobを実行するためにはKubernetesの環境を用意するところから始まります。自分たちで環境を構築・管理していくとなるとなにをする必要があるでしょうか。サーバーやネットワーク、ストレージなどインフラの調達やサイジング、そしてそのインフラ上へのKubernetesクラスタの構築を実施します。その後の保守管理として定期的なバージョンアップやパッチ適用、利用状況に応じてサーバーの増強やストレージ追加など継続して行う必要があります。
大規模なシステム環境であれば自分たちでコントロール可能な環境を用意し利用することは重要ですが、「今手元で作ったアプリをシンプルに動かしたい!」というときにはハードルが高くなってしまいます。
Code Engineは、フルマネージドのサーバーレス・プラットフォームで、デプロイ先のインフラを一切管理することなく、あらゆるクラウドネイティブワークロードを数秒でデプロイすることができます。つまり、Kubernetesをインストールして管理する必要はありません。
- 使った分だけのお支払い
常時起動しているWebアプリと違い、Jobはワンタイムでの実行や、CronJobのように決められたタイミングでのみ実行するため、サーバーを確保する形ではコンピュートリソースを無駄なく利用することが難しいです。
Code Engineはサーバーレスプラットフォームのため、必要なリソースを必要なタイミングだけ利用できます。規模の大きいJobも、実行頻度が多いJobも、大規模に並列処理が必要なJobも。実行時にどれくらいのリソースを確保しなければいけないか意識することなく、動かしたいJobを動かしたいときにご利用いただけます。
Code EngineでJobを実行した際の利用料は実際に利用したCPU量とメモリ量の秒課金ですので、無駄なく利用できます。
- 複数のワークロードを一つのサービスで実行できる
動かしたいアプリはJob以外に、ウェブ・アプリケーションやREST API、イベント駆動型のワークロードなどはありませんか?動かしたいワークロードに合わせてサービスを使い分けるのが一般的ですが、その場合サービスごとに使い方を学び、管理・運用する必要があります。
Code Engineではバッチ処理だけではなく、ウェブ・アプリケーションやREST API、イベント駆動型のワークロードなど様々なワークロードに対応しています。1つのサービスで複数のワークロードが動かせるため、アプリの実行環境準備に手間取らず、アプリ開発に注力することができます。
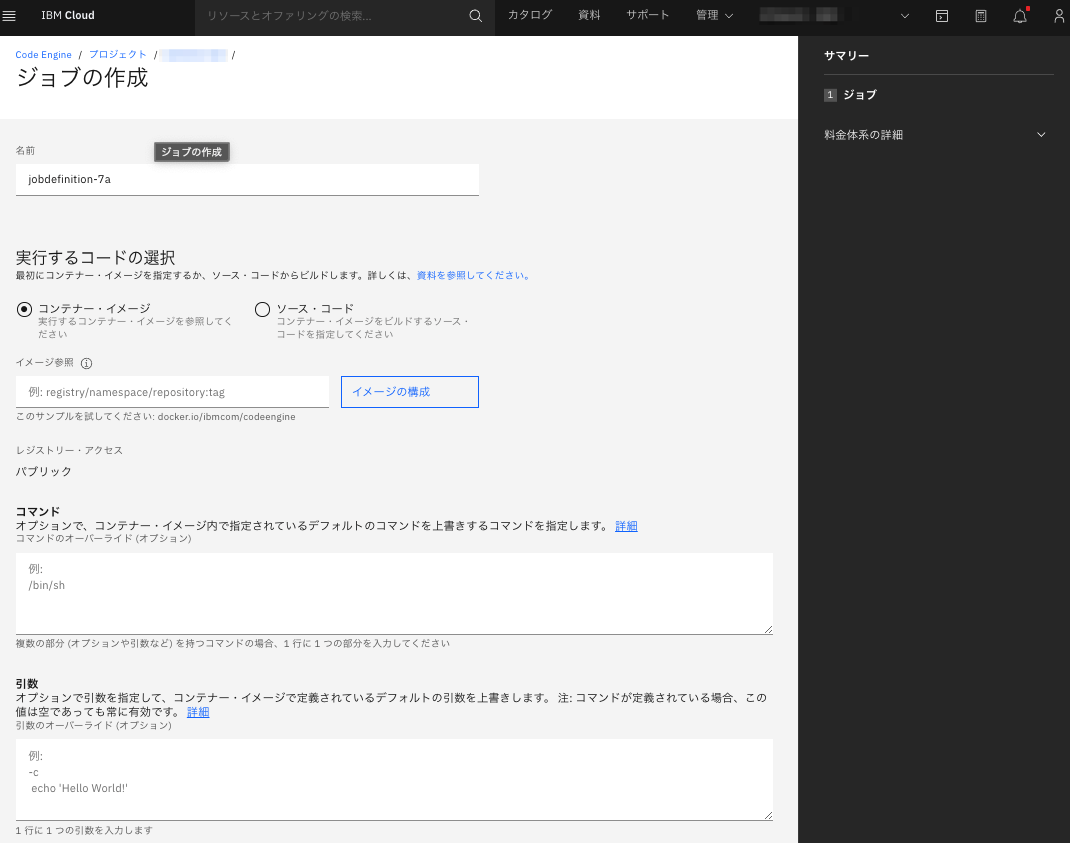
Code EngineでのJobの作成方法
Code Engineでの Jobの作成 では、コンテナイメージを指定する方法と、Gitリポジトリのソースコードを指定する方法と2パターンあります。ソースコードを指定した場合はCode Engine上で自動的にアプリをビルドし、コンテナ化が行われるため、ご自身でDockerfileを用意したりコンテナビルドしたりする必要がありません。
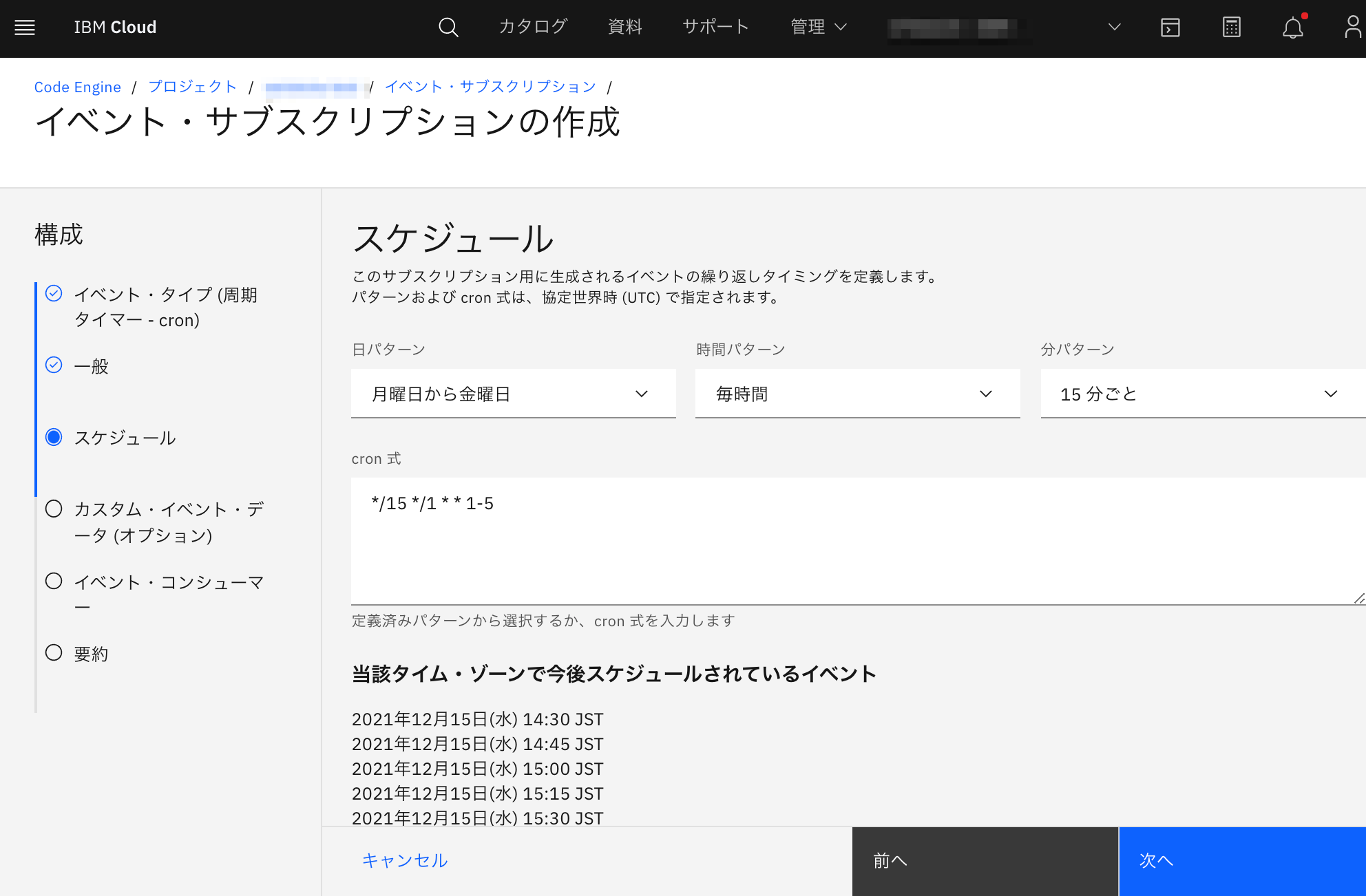
Code EngineでのCronJobとして、イベント・サブスクリプションという機能を利用して決められたタイミングで決められたJobを呼び出す設定を行います。スケジュールの設定方法としてCron式で直接記載する他、GUIを利用しての設定も可能です。
始める準備はできましたか?
実際にこちらのチュートリアルに進み、IBM Cloud Code Engine コンソールを使用してバッチ処理を実行してみましょう。

片岡 弘貴
日本アイ・ビー・エム株式会社
ITスペシャリスト
2012年IJDS(旧ISC-J)入社。ネットバンキングから基幹システムまで、システム開発に従事する傍らで、Cloud関連技術を学習。2020年よりクラウドテクニカルセールスとしてIBMに転籍し、コンテナ、IaaS、ネットワークとフルスタックなエンジニアを目指して日々お客様のCloud Lift&Shiftを支援。

佐藤 光太
日本アイ・ビー・エム株式会社
アドバイザー・アーキテクト
大手ERPパッケージベンダーでのフルスタックエンジニアを経て、2015年日本IBM中途入社。クラウドのテクニカルセールスとしてContainer, Kubernetes, CICD領域を中心に担当。元アプリエンジニア&DevOpsエンジニア&アップル・デモンストレーター。

ラウンドテーブルを通じてPwDA+Week2024を振り返る(後編) | インサイド・PwDA+9
IBM Partner Ecosystem
日本IBMグループのダイバーシティー&インクルージョン(D&I)活動の特徴の1つに、当事者ならびにその支援者であるアライが、自発的なコミュニティーを推進していることが挙げられます。 そしてD&Iフ ...続きを読む

ラウンドテーブルを通じてPwDA+Week2024を振り返る(前編) | インサイド・PwDA+9
IBM Partner Ecosystem
日本IBMグループのダイバーシティー&インクルージョン(D&I)活動の特徴の1つに、当事者ならびにその支援者であるアライが、自発的なコミュニティーを推進していることが挙げられます。 そしてD&Iフ ...続きを読む

風は西から——地域から日本を元気に。(「ビジア小倉」グランドオープン・レポート)
IBM Consulting, IBM Partner Ecosystem
福岡県北九州市のJR小倉駅から徒歩7分、100年の歴史を刻む日本でも有数の人気商店街「旦過市場」からもすぐという好立地にグランドオープンしたBIZIA KOKURA(ビジア小倉)。 そのグランドオープン式典が2024年1 ...続きを読む