SPSS Statistics
SPSS Statistics Small Tips #06アンケート分析で本領発揮!簡単操作できめ細やかなクロス表を作成 ~SPSS Statistics Custom Tables ~
2022年01月11日
カテゴリー IBM Data and AI | SPSS Statistics | アナリティクス | データサイエンス
記事をシェアする:
データ分析結果を報告するのに、最初に必要なのはデータの基礎統計です。度数の分布は?、カテゴリに占めるターゲットの比率は?、平均値は?、とデータの概要を共有して伝えるべき結論のスタートポイントに立ちます。そして基礎統計は表やグラフが用いられます。表は煩雑になりがちな基礎統計量を把握するのに簡単かつ分かりやすい集約方法ですし、グラフも目を引き瞬時に伝えられる表現方法だからです。IBM SPSS Statisticsは作表を詳細な統計量と共に簡単に出力できるオプションをご用意しています。例えば列%の出力や、カイ2乗検定やt検定。マルチアンサー(MA)形式の変数からも作表できます。
このTIPSではSPSS Statistics Custom Tablesを使って、作表の仕方や設定、多重回答の扱い方などをご紹介します。
カスタムテーブルを使って、クロス表を作成する
以下の例では、同梱されているサンプルファイルのDemo.savを使用します。
「分析」 メニュー> 「テーブル」 > 「カスタムテーブル」を選択します。
最適な表を作成するために「変数プロパティの定義」で、適切な尺度の選択や値ラベルや欠損値の設定を行うステップも用意されています。この一手間が分析結果の考察や説明に大いに役立ちます。
すでにデータエディタで定義が完了していればこのステップは不要です。
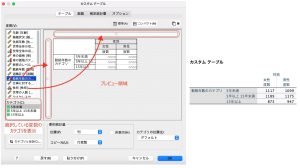
変数リストに変数一覧が表示され、変数を選択すると、そのカテゴリ情報がカテゴリリストの中に表示されます。マウスを使い、表したい変数を選んで、右のワークスペースの中の「行」および「列」のバーの部分にドラッグ&ドロップします。
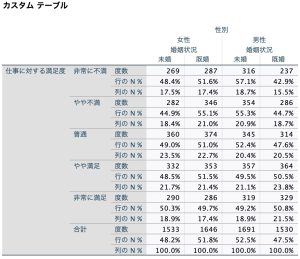
ここでは「勤続年数」変数を行、「性別」変数を列に投入しており、プレビューで確認することができます。OKを押すとテーブルが出力されます。これで、基本的な2変数のクロス表が完成です。デフォルト設定では、それぞれの度数が出力されます。
また、プレビュー内でドロップした変数を選択した状態で、左下「定義」の「カテゴリと合計」ボタンをクリックすると、カテゴリ変数のうち除外する項目の選択、値によっての並び替えの指定や、合計を表示させるかどうかを選択できます。
クロス集計表から、グラフを作成する
表を出してみると、今度はその統計出力結果を使ったグラフを出力したいことがよくあると思います。IBM SPSS Statisticsでは、出力したクロス集計表結果から、グラフを出力することができますのでその手順をご紹介しましょう。
なお、この機能はSPSS Statistics Custom Tablesがなくてもお使いいただくことができます。
IBM SPSS Statisticsの出力は、表もグラフも全てダブルクリックで編集が可能です。実際に出力したクロス表をダブルクリックすると、それぞれのセルが選択できるようになります。その状態で右クリックするとポップアップで編集メニューが表示されます。ここでは合計値を除いた集計値をハイライトした状態で、「グラフを作成」 > 「棒」を選択して、該当集計値の棒グラフを出してみます。
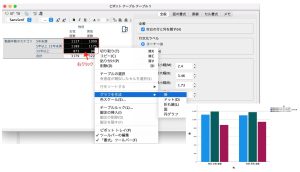
出力されたグラフはダブルクリックをすることで図表エディタを使って、色変更などの編集も可能です。
また、テーブルの編集メニューにある「テーブルルック」を使うと、すでに用意されているテンプレートを適用したり、新規テンプレートを作成することができます。
下のテーブルは、「Academicテンプレート」を適用した結果のテーブルです。

変数の積み重ね、入れ子、層化をする
ここからさらに、この表に手を加えていきます。まず、集計に使用する変数を増やしていきます。複数の変数情報を入れるには大きく分けて3つの考え方(積み重ね、入れ子、層)があります。
積み重ねは、変数を平行して同列に表示させていくやり方です。SPSS Statistics Custom Tablesでは、いくつでも変数を追加していくことができます。行方向にも列方向にも追加可能です。
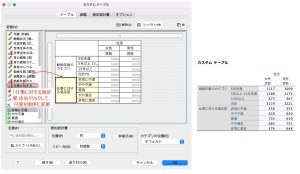
入れ子は、上位の次元に下位の次元が入っている状態で、例の場合、仕事に対する満足度全カテゴリそれぞれに勤続年数のカテゴリが含まれている状態です。SPSS Statistics Custom Tablesでは、行/列共に原則いくつでも追加可能ですが、あまり入れ子にし過ぎると各セルに該当するデータが少なくなるため、特に次に紹介する検定を行う際には注意が必要です。
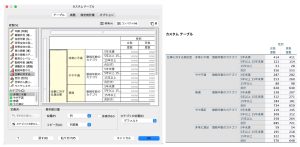
層は入れ子や積み重ねとほとんど同じですが、主な違いは 一度に表示できるのが層内の1つのカテゴリだけという点です。例えば性別を層に入れると、行/列で指定している表を、男性もしくは女性のみ集計した表を作成します。
右上の「層」のボタンを押し、層項目を表示させ、該当変数を枠内にドラッグします。
仕事に対する満足度を層に入れた結果、まず1つめのカテゴリである「非常に不満」のみを集計した結果が出てきます。
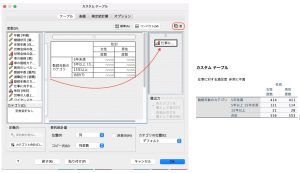
表をダブルクリックすると、層のカテゴリを選択するドロップダウンが現れますので、そこで着目したい1カテゴリを選択し、結果を表示させることが可能です。
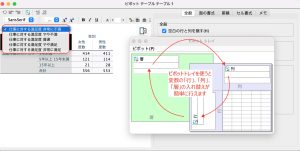
表をダブルクリックした状態で、「ピボット」 > 「ピボットトレイ」を選択すると、ピボットトレイウィザードが立ち上がります。ここで、変数を左上の層へ移動させ、層構造にすることもできます。
様々な統計量を出力する
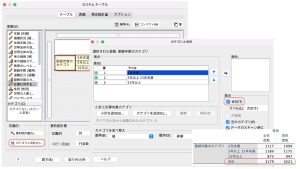
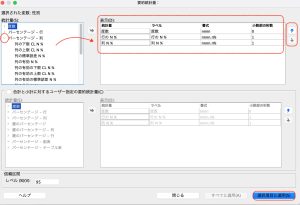
次に出力する項目を増やしてみます。デフォルトでは度数のみですが、他にも様々な統計量を出力できます。この例では、テーブルに投入した変数のうち、行変数を選択した状態で左下「定義」の「要約統計量」ボタンをクリックすると、ウィザードが立ち上がります。ここでは、行のN%と列のN%を出してみましょう。
「統計量」から行N%、列N%を選択し表示に投入します。ラベルや形式、小数桁数は変更可能です。表示順序を変えたいときには、右の上下矢印で変更してください。設定ができたら、「選択項目に適用」を押します。
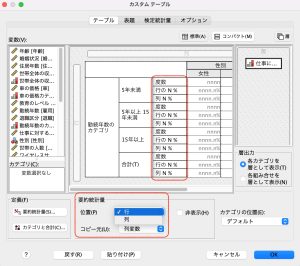
設定ができると、まずプレビューに項目が追加されていることが分かります。さらに真ん中下の「要約統計量」が選べるようになります。「位置」で項目の表示方法が選べます。
「列」を選択すると項目が横並びになり、「行」を選択すると、項目が縦ならびに出力されます。
検定を行う
クロス表でセルの度数やパーセンテージを確認できますが、では2つの変数には関係があるのか、以下の例では、性別と仕事に対する満足度の関係性をみていきます。具体的表現すると、性別により仕事に対する満足度には差が出るのか、性別による違いがあると言っていいのか、それを統計的に評価するためには、統計検定を使います。
カスタムテーブルでは、作表と併せてカイ2乗検定、t検定(列の平均値の比較)、z検定(列の比率の比較)ができます。
カスタムテーブルウィザードで、「検定統計量」タブを選択します。ここでは、「独立性の検定(カイ2乗)」と、「列の比率を比較」にチェックを入れます。
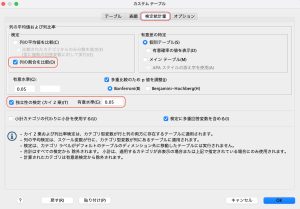
またここでは変数に、行に「仕事に対する満足」、列に「性別」と「婚姻状況」を入れ、OKを押します。

最初にPearsonのカイ2乗検定出力を見ます。有意水準=0.05で判断すると、この結果は、性別も婚姻状況も仕事に対する満足度は有意ではないことを示しています。つまり、性別や婚姻状況により、仕事に対する満足度に違いがあるとはいえない、ことを示しています。

次に列比率の比較出力です。列の比率の検定で作成したテーブル表では、列変数の各カテゴリに文字キーが割り当てられます。ここでは、女性に(A),男性に(B)が割り当てられています。
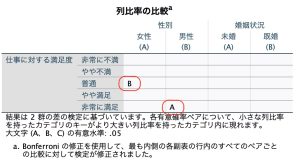
セルの中にアルファベットが入っています。これは、各有意確率ペアについて、小さな列比率を持ったカテゴリのキーがより大きい列比率を持ったカテゴリ内に現れます、という定義に基づき表出されます。この定義は表の出力の脚注に出ていますが、もう少し具体的に読み取ってみましょう。
上から順番に見ていきます。「普通」の「女性」セルにBが入っています。これは普通と回答した人の中で、女性の比率は、男性の比率よりも高い」ことを示しています。つまり、(A)である「女性」カテゴリが、(B)である「男性」カテゴリに表示されているので、この列=普通カテゴリにおける列比率は、(B)男性<(A)女性、ということを示していることになります。

同様に「非常に満足」では(B)男性の下にAが表示されているので、非常に満足カテゴリにおける列比率は、(A)女性<(B)男性であることを示します。「非常に不満」や「やや不満」、「やや満足」、加えて「婚姻状況」変数の全カテゴリにはアルファベットの出力がありません。これはそれぞれのカテゴリ間で、比率に統計的な差を確認することができないことを示しています。是非、クロス表の度数と併せて、これら検定の結果を眺めてみてください。
多重回答データ(MA)を集計する
ここからは少し視点を変えて、多重回答データ、マルチアンサーデータ、MAデータと呼ばれる変数を扱い、集計するやり方をご紹介します。
そもそもMAデータというのはどういうデータでしょうか?簡単に言ってしまうと、アンケートなどで「いくつでもいいので選んでください」「複数選択可能」と書いてあるような収集方法をしているデータのことです。そのような回答は集計しやすいようにデータとして保存をするとき、独特な方法を使います。
「Q. 以下の電話機の機能から、使用しているものをいくつでもよいので選んで下さい」という質問に対して、
- ボイス、
- ワイヤレス、ボイス、ポケベル、コールID、キャッチホン
- ワイヤレス、ボイス、
- ワイヤレス、複数回線、ボイス
- なし
…
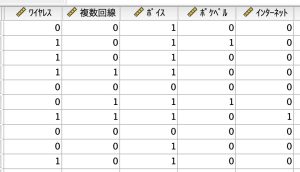
というデータが集まってくると思います。そのときには、上のようにデータ入力をします。0/1のデータで、2値型、フラグ型とも呼ばれる形式ですが、0であれば使っていない、1ならば使っていると決めて情報を入力します。このようにデータを持つことで、ワイヤレス機能を使用している人が何人か?また、使用頻度が高い機能は何であるのか?など個別のデータ集計がしやすくなります。このやり方は、アンケートの複数回答だけでなく、顧客がある商品を買った・買わないか、テキスト解析をした際に単語を言った・言わないといったデータを保存するときなどにも使われる一般的な方法です。しかしこのようにデータ入力をしていくと、困ったことが起きることもあります。複数の変数が独立しているため、複数の情報を総合した集計がしにくくなることです。
そこでIBM SPSS Statisticsでは、複数の変数であっても、本当は1つの質問に対する答えですよ、と定義することができ、その定義したグループをその他の変数と同様な扱いで集計することができます。これをIBM SPSS Statisticsでは「多重回答グループ」を設定する、といいます。それでは次に、このようなMAデータ処理方法をご紹介します。
「分析」メニュー > 「テーブル」 > 「多重回答グループ」 を選択しウィザードを開きます。
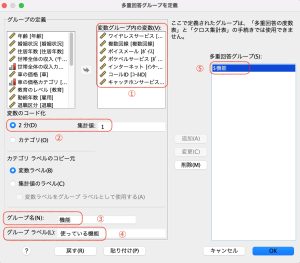
変数一覧から、グループにまとめる変数を全て「変数グループ内の変数」に投入します。
「変数のコード化」で2分変数が選択されていることを確認し、ここでは集計値を”1”とします。これは1となっているものを数えるという意味です(1or2で、2がYESならば2とし、T/Fと入っているデータならばTと入力します)。
「グループ名」にグループの名前、「グループラベル」にグループとしてのラベルを設定します。これは変数でいう変数名とラベルと同様です。この設定ができたら、追加を押すと、「多重回答グループ」に$機能という変数グループが追加されます。
多重回答グループはすべて「$」で始まります。これで設定は終了ですので、OKを押しますがここでグループの定義を変更、削除する必要があるときには、右の一覧からグループをハイライトし、情報を変更して「変更」ボタン、もしくは「削除」ボタンを押します。
データセットに戻っても、変数として追加されるわけではなく特に見た目上の変化はありません。しかし 「分析」メニュー > 「テーブル」 > 「カスタムテーブル」 を選択すると、多重回答グループアイコンと共に、新たに「 使用している機能 「$機能」 」という項目が追加されています。
以降は多重回答グループの集計表の作成はもちろんのこと、他の変数と組み合わせた集計表の作成もできるようになります。クロス集計のバリエーションが増えて、データをさまざまな切り口で捉えることができるようになります。
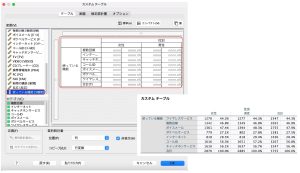
また、SPSS Statistics Custom Tablesでは、カテゴリの度数が0の場合にも集計表に表示されます。カスタムテーブルで作成した度数表と通常の度数分布表は次の通りです。

まとめ
いかがでしたか。SPSS Statistics Custom Tablesで作成できるさまざまな集計テーブルから、現状の把握、仮説の立案や検証、結果の説明までご利用いただくことができます。
集計表の作成は、ドラッグアンドドロップで視覚的にイメージしながら操作ができます。
さあ、さっそくはじめてみませんか。
SPSS Statistics 無料評価版 https://www.ibm.com/jp-ja/products/spss-statistics
お問い合わせは SPSS営業部まで jpsales@jp.ibm.com
→SPSS Statistics Small Tips バックナンバーはこちら

牧野 泰江
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

テクノロジーが向かう先とは〜中長期テクノロジー・ロードマップ
IBM Cloud Blog, IBM Data and AI
IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む