SPSS Modeler ヒモトク
Modelerデータ加工Tips#22-顧客が休眠直前に購入した商品を特定する
2021年11月08日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
皆様はじめまして、日立ソリューションズ東日本の及川と申します。
弊社は、東北/仙台に本社をおき、「そして世界へ」「その先のお客様とともに」を掲げお客様の事業をサポートして参りました。仙台、札幌には地域と密着した事業所を置く一方で、東京事業所では首都圏対応の他、地域横断つまりソリューションにフォーカスした事業(SCM分野など)を展開しております。
私は、この23年(あらためて数え、四半世紀に届こうとしていることに我ながら驚きを覚えました)という期間、データ活用に関係した事業に携わっております。当初は、BIツールの活用(今となっては懐かしいCognos PowerPlayなど)からデータウェアハウスの設計・構築などが中心で、その後、更なる価値提供のため統計解析、機械学習の分野にも関わるようになった経緯があります。弊社のアナリティクス事業は、産業・流通分野、自治体を含む社会・公共分野など広く対応しておりますが、私のミッションとしては特に製造業、工場IoT分野にフォーカスし生産性や品質、保全などの業務分野でのデータ活用、価値向上をご支援させていただいております。
私が最初にSPSSというブランドを知ったのは2000年頃だったと思います。SPSSのDecision Treesに触れる機会があり、重回帰くらいしか知らなかった私にはとても斬新に感じました。そして関連製品として当時の「Clementine」(現在のModelerです)を拝見したのですが、まだPC単体で動作するような手軽なソフトではなかったとはいえ、キャンバスにノードを繋いでフローを描くというコンセプトは当時すでに確立されており、そのユニークなユーザインターフェースが今も脈々と受け継がれていることにあらためて敬意を評します。
その後、自身でSPSS Modelerを使い、またお客様にもご提案するようになりましたが、モデリングの容易性に加えて、データ準備の段階でも(いざとなったら)多少の無理(スクリプティング)も効くところが、Modelerの良いところと思っています。
とりわけIoTセンサーデータやID付きPOSデータのように個体IDが時系列で記録されているデータへのハンドリングは秀逸で、一度覚えるとSQLやPythonで実行する気が起きなくなるほど便利です。今回はその代表的な手続きを取り上げて記事にしてみました。
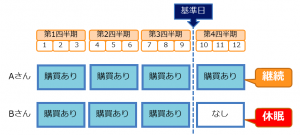
例題1:「定義に従って休眠者にフラグを立てる」
出題は以下の通りでした。
取引データの日付の最大値を現在と仮定し、顧客リスト90日以上購買がなかった休眠者フラグを立ててください。出力フィールドは顧客ID休眠フラグの2フィールドのみで、入力と出力の間には3ノードのみの3手詰めです。ヒントは、その3手に直接含まれない重要な捨て駒が活躍します。

例題データ
東京図書様に許可をいただき「実践IBM SPSS Modeler~顧客価値を引き上げるアナリティクス」の紹介ページにあるダウンロードサンプルデータ「sampletranDEPT2015.csv」を利用いただけます。
出来上がったストリームは次の通りです。出題時に述べた重要な捨て駒、グローバルノードを含めると厳密には4手詰めですね。
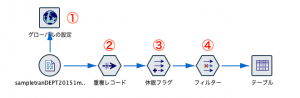
まず①のグローバルの設定です。推しノード#12でも詳しく紹介されているとおり、このノードは統計量をメモリーにキャッシュして後続のプロセスで関数から呼び出して利用できます。設定は以下の通りです。DATEのグローバル最大値を求めます。設定ができたら実行ボタンを押してみてください。
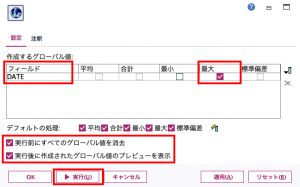
ストリームのプロパティウィンドウが表示されましたでしょうか?

このセッション中は2015-12-31がDATEの最大値として認識されます。
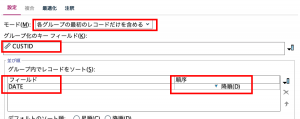
次に②で重複ノードを使って、顧客の最終購買日を特定します。
モードを「各グループの最初のレコードだけ含める」、キーは顧客IDでDATE降順でソートすると、顧客が最後に利用した日にちのみ1行を残し、重複を排除します。
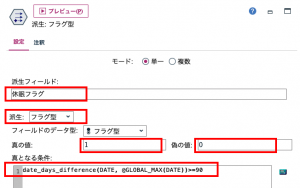
③ではフィールド作成ノードを用います。派生モードを「フラグ」にしたら真の条件を、式ビルダを起動して記述します。
利用する関数はAとB時間の差を求めるdate_days_difference(A,B)を使います。このうちAは最終利用日なので、そのままAを、Bには①で求めた全ての期間の最大値@GLOBAL_MAX(DATE)です。最終利用日から最大値(この場合2015-12-31)までの日数が90日以上だと休眠と定義されているので、真となる式は次の通りになります。
date_days_difference(DATE, @GLOBAL_MAX(DATE))>=90
最後にフィルターノードで表示するフィールドを顧客IDと休眠フラグに絞ると完成です。
今回はグローバルノードを使って最新日の特定をしました。ノード数が減ってシンプルですがストリームの最初に実行しないと正しい処理が行われないので、バッチなどでは特に注意が必要です。
そのミスを防ぐためにストリームを作ると以下のようになります。
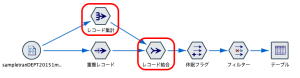
一度キーをブランクにレコード集計でDATEの最大値を求めておき、重複ノードの後に、キーをブランクで結合します。
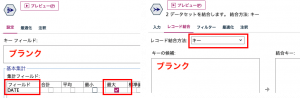
休眠フラグの真の条件の式は次の通りです。
date_days_difference(DATE, DATE_Max)>=90
この方法はノードは増えますが、プロセスは明確になりますね。
例題2:「顧客が休眠直前に購入した商品を特定する」
例題1と同じデータを使い、休眠者が休眠する前の最後の来店で購入した商品(PRODUCT)の上位5つをリストしてください。入力と出力の間には7つのノードを使う7手詰めです。

出来上がったストリームは次の通りです。例題1から延長する部分を説明します。
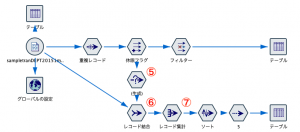
⑤の条件抽出ノードはご自分で式を記述しても結構ですが、例題1の結果テーブルから自動生成できます。休眠フラグ=1のセルを見つけ指定した状態でメニュー>生成>条件抽出ノード(AND)を選びます。
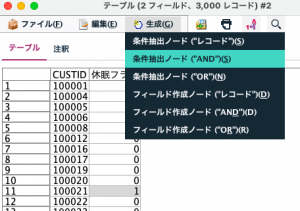
シンプルに以下のようになっているはずです。

続いて⑥のレコード結合です。
オリジナルの取引データから休眠者の最終利用日の購買商品に絞り込むのが目的です。
まず多くのフィールドが重複するので不要なものはフィルターします。フィルタータブで休眠者からのデータの顧客ID、DATE、休眠フラグ以外は不要です。
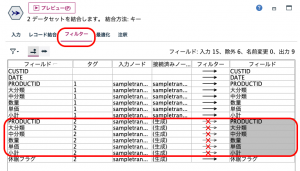
その後レコード結合タブでキーに顧客IDとDATE選んだら内部結合を選択します。
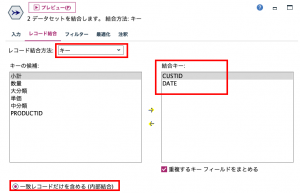
プレビューをしてみてください。例えば顧客番号100021は8月23日が最後の来店になり、休眠扱いとなっていて、その日に2つのPRODUCTを購入しています。
あとは集計すればゴールです。

⑦の集計ノードではキーにPRODUCTIDと一意に紐づいている大分類と中分類も入れておきます。
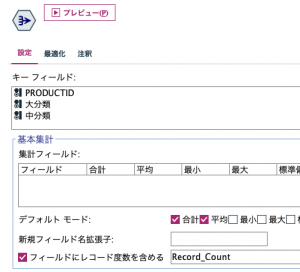
あとは度数降順でサンプリングを先頭から5行すれば完了です。
上手くできましたでしょうか?
休眠する顧客が最後に買ったランキングになんの意味があるのでしょうか?実は最後に購入した商品が原因で休眠を促した商品を探しています。化粧品などは、ユーザーの肌質などと関係なく無理に推奨販売商品を押し付けると、結果的に顧客離れが起きると言われています。もちろん、全体のランキングと比較しないと、この結果だけをみて「これがロイヤリティを下げるキリングアイテム」と誤った判断をしてしまうので注意です。特徴的にある商品を購入すると休眠しやすいことがわかると、重要な判断につながるはずです。また逆にキープアイテム(=継続を促す商品)が顧客セグメントごとにわかれば休眠させない施策に繋がりますよね。
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題:「機種ごとにループでファイルを分割する」
ループ処理を用いて、フィールド「Machine Type」の機種ごとにファイルを分割しCSV形式で保存してください。これまでの詰将棋で例えると、千日手とも言えるループ処理をできるだけマウス(GUI)で操作して、スクリプト記述は最低限にしてみてください。
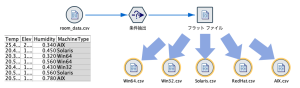
例題データ
利用するデータは、以下です。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/room_data.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
ぜひチャレンジしてみてください。
さて次回は、ベテランユーザーにはお馴染みのスマート・アナリティクス武田千夏さんによるイベント報告記事を挟んで、いよいよ連載最終回です。フィナーレを飾る執筆者は、どなたでしょうか!?ご期待ください。

及川 慎也
株式会社 日立ソリューションズ東日本
ビジネスソリューション本部 アナリティクスソリューション部
GL主任技師

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む

【予約開始】「SPSS秋のユーザーイベント2024」が11月27日にオンサイト開催
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
本年6月800名を超える方々にオンライン参加いただいたSPSS春のユーザーイベントに続き、『秋のSPSSユーザーイベント』を11月27日に雅叙園東京ホテルにて現地開催する運びとなりました。 このイベントは ...続きを読む