

























SPSS Modeler ヒモトク
Modelerデータ加工Tips#19-決定木の所属グループと該当条件をレコードに付与する
2021年09月27日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:

皆様はじめまして、(株)読売広告社 ビジネスデザイン局の齋藤と申します。
弊社は、都市と生活者の潮流から未来への変化の兆しを見つけ、得意先の「課題発見」につなげることを目指し、「都市と生活者の未来を拓く」をビジネスビジョンに掲げ得意先へ様々なサービスを提供しております。特に私の所属する部署では得意先の顧客データや調査データ、弊社内・社外の様々な3rdパーティーデータも含め多面的にデータを活用して、各種施策の企画から実施・検証、さらに得意先の新事業領域支援までサポートさせていただいております。
私とSPSS Modelerとの出会いは2003年ごろにさかのぼります。当時のエス・ピー・エス・エス株式会社に学生アルバイトとしてお世話になっており、様々お手伝いさせていただきながらツールの使い方も学ばせていただきました。その当時作ったIDPOSデータ処理のサンプルストリームを長く(未だに?)IBMさんでご活用いただいていると聞いてうれしかった覚えがございます。
さて、このブログ連載のオファーをいただいたとき、データ加工がテーマと知りながらも決定木を取り上げたいと思いました。10数年来SPSS Modelerを利用する中で、今も昔も、(ここ数日の局面でも)自分を助けてくれる頼れる重要な「駒」だからです。
Modelerの決定木ノードをModeler詰将棋になぞらえて将棋で例えると、細かいセグメントを作る仕事人C5が「銀」。2分岐が潔くユニークなCARTは「桂馬」、値千金の精度をもたらすXGboostはさしずめ「金」といったところでしょうか。
そして私が最も利用するCHAIDは、「飛車」が成って裏返った「竜王」です。カイ二乗で分ける基準が直感的で説明しやすいのに、計算負荷が少なく、すぐに結果がでてチューニングも簡単と。推しノード#6でIBM山下さんがCHAIDを絶対エースと称しましたが、この「駒」なしでは勝負ができないほどの存在です。
もちろん「竜王」のような大駒が活躍するには盤上で多くの「歩兵」(データ加工ノード)が戦局を整える必要があります(自分が広告代理店のマーケターなのを忘れてきました)。精度と説明性を確保しながら、決められた時間で適切なノードを組み合わせ、それぞれの持ち味を生かすのが、本当の棋士・・・ではなく分析者なのだと日頃から肝に銘じています。
さて、今回は特徴量生成のようなモデル前段のデータ加工ではなく、決定木モデルができてから、説明力を向上させるためのデータ加工を紹介します。「なんで、このケースはこんなにスコアが高いのか」という担当者の疑問に即答する必要があるのは、マーケティング領域だけではないはずです。設備故障や不正検知でも、同じようにケース毎の説明が要求される場合に役に立つのではないかと考えています。
それでは所属分岐ルールを付番するところから始めましょう。
例題1:「決定木モデルの所属ルール番号を各レコードに付与する」
出題は以下の通りでした。
決定木分析CHAIDを用いて、まず解約有無(フラグ型にしてください)を対象に予測モデルを作成してください。残る変数は顧客番号以外は全て入力にします。以下の図のように、一旦樹形図をIf-Thenルールに変換した上で、各レコードにルール番号を付与してください。利用するノードは1つのみ、データ型を含まず1手詰めです。
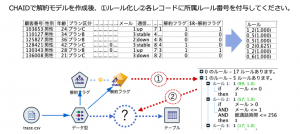
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/trace.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
まず最初にCHAIDで決定木モデルを作ります。データを読み込んだら、データ型ノードで「解約フラグ」の尺度を「フラグ型」にして「値の読み込み」ボタンを押します。あとは「顧客番号」のロールを「レコード」(「なし」でも結構です)、「解約フラグ」を「対象」とします。そのままCHAIDを接続して実行すると以下のように出題のスタートポイントになります。

出題に「一旦樹形図をIf-Thenルールに変換」とあるようにモデルナゲットを編集します。下の図の右側はビューアータブのツリー図です。SPSS Modelerはこのビジュアルなチャートを資料に転載して、プレゼンに使えるのがメリットなのですよね。一方で、「解約=1」はどういう条件で生じるのか結論をルールベースで示してしまう方が良い場面もあります。そこで左のテキストのツリー図をルールセットに変換します。
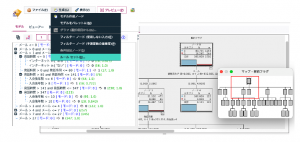
ナゲットのメニューの「生成」から「ルールセット」を選択し、次の設定ポップアップをOKとすると「R S」(ルールセット)と表記された新たなナゲットが自動生成されます。全体をセグメントに分岐させたツリー図を、If-Thenのルールに書き換えています。注意していただきたいのは先のツリーと同じものを示していますが、ルールセットに変換したことで、スコアリングに使うと、先とは異なる値になります。その理由は、スコアリングのアルゴリズムの違いによるものです。
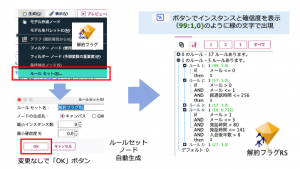
ナゲットをルールセットに持ち替えましたので、最後の仕上げです。ルールセットノードを編集してメニューの「生成」から「ルールトレースノード」を選択します。フィールド領域に星形のスーパーノード(推しノード#20)が自動生成されました。ズームインすると解約=0のルールが17種類と解約=1のルールが5種類、それぞれフィールド作成ノードで表現され、カプセル化されているのがわかります。
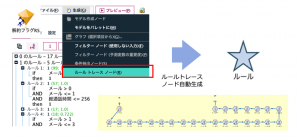
出来上がりを確認します。テーブルに出力すると、所属ルール番号が付与されて、どのルールが適用されたのかがわかります。1_2(1.000)は解約=1のルール2が適用され該当ルールは100%解約だったとわかります。
これは1手詰めではなく25手詰め(25ノード)なのではないかと疑惑を持たれるかもしれませんが、自動生成したスーパーノードはカウント1手と運営側の判断に従いました。

それぞれのレコードにルール番号と確信度が付きましたので、次は該当する条件を付与します。
例題2:「レコードにIf-Then条件をつけて所属理由を判読可能にする」
各レコードがどの条件に該当して、所属ルール番号になったかわかるようにフィールドを追加してください。
例題データ
利用するデータは、例題1のものに加えこちらも利用します。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/rule_set.txt
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
大変なノードが並び、このTips#19が問題作であると判明するのですが、それでも役に立つストリームなので一緒に作りましょう。
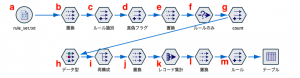
まず可変長ファイル入力(a)ですが、例題データは次のように作られています。
(a)の読み込み時には左のようにフィールド名は取得せず、改行以外の区切り文字を排除します。右のようにプレビューできるはずです。真偽区分とその中のルール番号、そして実際の条件の3つのパートに行が分かれています。

(b)は置換ノードで「filed1」の無駄な空白を「trim(field1)」でトリムしています。置換え条件は常時にします。
(c)では派生をフラグ型にしてから真となる条件を「field1 matches “ルール*”」として●真偽内のルールであるフラグを作ります。
そして(d)で真偽区分の0か1かを判別させ、ルール番号やルールのレコードはヌル(undef)にします。具体的には「あります」という文字列が含まれたら、その最初の文字(0か1)を「to_integer(startstring(1, field1))」で抽出します。

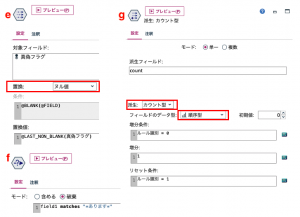
先に作った真偽フラグのヌルを「@LAST_NON_BLANK(真偽フラグ)」で置換えます(e)。
置換えてしまえば、真偽区分は不要なレコードですので、(f)のように「field1 matches “*あります*”」で破棄します。
(g)では派生をカウント型にして、初期値を0のまま増分条件を「ルール識別 = 0」リセット条件を「ルール識別 = 1」にします。
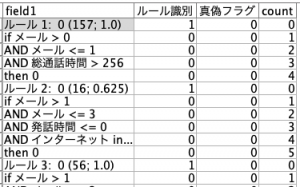
(g)までのテーブルは以下の通りです。確認してみてください。
次に(h)ではデータ型で「値を読み込み」ボタンを押して値を確定します。先のノードでcountは順序型にしていますが、ここで強制的に変更してもOK。
値が確定すると(i)の再構成ノードでcountのゼロを除く1から6までをフィールドに展開して「field1」を埋め込むように設定します。今回は6フィールドで固定しましたが、今後のストリームの再利用を考えると、想定される条件数のフィールドを予め準備することをお勧めします。
ルールは列に記録されて、field1は集計用のIDに変更します。(j)置換ノードで条件を「count /= 0」として置換値を「@OFFSET(field1, count)」にするとfieldが同じルール番頭になります。オフセットの使い方はTips#05やTips#06をはじめこのブログで何度も取り上げられてきました。N行上のレコードを参照し、今回はcountを受け取ってルールグループの先頭レコードを指定します。
(k)のレコード集計でルールを1行にしていきます。先ほど列に展開したフィールドを対象として、ヌルを無視し、実態のあるデータだけを拾うために「最大値」を使います。
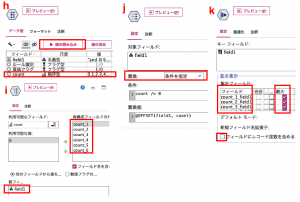
(l)はあってもなくてもいいのですが、二重引用符を続けて「””」とすることで空白を作りヌルを置換えました。
(m)は右肩の表の青いフラグと赤いルール番号を抜き出して、アンダーバーで接続した文字列のフィールド作成です。前半の「substring( (issubstring_count(“(“,1, field1))-2,1, field1))」はfieldの文字列の「(」がどの位置にあるかを数えてその2文字前の文字を抽出しています。その後の文字列と繋ぐため「><“_”><」と表現しています。後半の「trimstart(replace( “ルール”,””, startstring(issubstring(“:”, field1)-1,field1)))」は「:」の一文字前の文字数までを先頭から抽出し、「ルール」を空白に置換えた上で先頭の空白を削除し最初の数字を拾っています。数字によって桁数が異なるので少し複雑な関数になりました。
文字列の加工はIBMの牧野さんがこちらにまとめてくださっています。
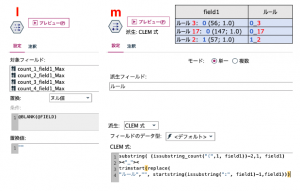
出来上がったデータをプレビューします。

これを例題1と繋げればOKです。まず、ストリームをスーパーノードで整理します。
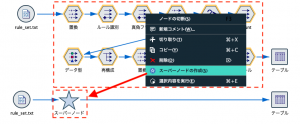
出来上がったスーパーノードを例題1のルールトレースノードまでとレコード結合します。
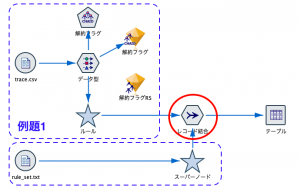
レコード結合は一般的にIDをキーにして2つ以上の表を繋げますが、今回は条件で接続します。例題1のルールフィールドは「1_2(1.000)」と確信度が余計ですので、これを結合条件で排除します。せっかくのTipsですのでTips#14を参考にさせていただきました。
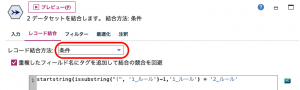
これで完了です。上手くできましたでしょうか?

今回は1のレコードに1つのルールでしたが、場合によって1のレコードに複数のルールが適用されます。その時にはセミコロンなどの記号を目印に重複したルールをまず、文字列で分割し、ノードを同じように繋いで対応してみてください。
さて次回は秋のSPSS Modelerオンラインユーザー会告知記事を挟んで、Tips# 20です。このブログではすっかりお馴染みのIBM都竹さんの登場です。イベント告知記事に都竹さんの出題をしますのでお見逃しなく!

齋藤 敏之
株式会社 読売広告社
ビジネスデザイン局 データビジネスルーム

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む