SPSS Modeler ヒモトク
Modelerデータ加工Tips#18-連続値の最適分割とモデルの出し分け
2021年09月16日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさま、こんにちは。(株)リバーフィールドの磯部と申します。
弊社は、商社としてスタートしてから30年、「豊かな社会と快適な暮らしの創出」に貢献できるよう、時代の変化に合わせて様々な製品・サービスをご提供し続けております。
近年では、「”時間”で豊かな社会」を目指し、企業様の業務を効率化することで、時間を有効活用いただけるよう、AI関連サービスに力を入れております。
また、IBMビジネスパートナーとして、SPSSの販売やAI/Analytics関連のコンサルティングサービスも提供しております。
前職では、IBMでSPSSやWatson IoT を担当しておりました。
製品・ソリューションのスペシャリストとして、技術をご紹介したり、お客様のデータをお預かりして分析したり、セミナーで講演させていただくこともありました。
現在は、AIサービスの立ち上げやAI活用をお考えの企業様に、コンサルティングや分析サービスなどを行なっています。
これまでに、大企業からスタートアップ企業まで、約600社に技術紹介やビジネス相談対応、コンサルティングなどを実施いたしました。
製造業や流通・小売業、サービス業、ソーシャルアプリ事業など、分野も様々です。
そんな私の経歴を知ってか知らずか、時々チャレンジングなご依頼をいただきます。
・6時間で実データを使った品質予測モデルを作って欲しい
(お客様先で軟禁状態…)
・12時間で走行データを使用して、何でもいいから予測モデルを作って欲しい
(頼まれた時はすでに夜…何でもいい??)
・2か月で100の支店別に需要予測モデルを作って欲しい
(いきなり全国展開ですか?)
・3か月で業務に使える商品別予測モデルを180個作って欲しい
(Help me…)
etc.
無理難題のように聞こえますが、お客様にも様々なご事情がおありなのです。
私も出来る限りご希望に添えるよう、最善を尽くしました。
ビジネスでは、”Time is money”、データも分析結果も”鮮度が命”なのです。
「いかに早く良いモデルができるか」が重視されます。
さらに、1つモデルができると、拠点別、商品別、顧客グループ別など、モデルを横展開し、既存の業務フローに広く組み込まれることもあります。その場合は、「短期間で効率良く業務展開できる」ことも重要です。
そこで、頼りになるのがIBM SPSS Modelerです。
仕事上、オープンソースや他の分析ツールを使うこともありますが、限られた時間で効率良く分析できるModelerは、私の1番のお気に入りです。
今回はベテランでも「知らなかった!」と驚く便利な2つの分割機能をテーマにしてみます。
例題1:「予測に最適なグループ化」
出題は以下の通りでした。
解約を予測するのに適するように期間をいくつかのグループに分けてください。出来上がったフィールド名は気にせず1手詰め(1ノード)です。
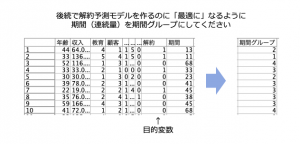
例題データ
https://raw.githubusercontent.com/yoichiro0903n/blue/main/optdata.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
こちらが解答となるストリームです。実はTポイント・ジャパンの山本さんが1つ前のTips#17で紹介されたデータ分割ノードを再び利用します(連続の登場にびっくり)。IBM河田さんも記事の中で紹介されていますね。

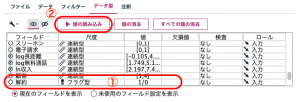
データを可変長ファイルノードで読み込むときに1箇所注意をしてください。目的変数になる解約をフラグ型で固定する必要があります。データ型タブの①でフラグ型を選択し②値の読み込みボタンを押して型を確定します。
続いて、フィールド設定タブの中にあるデータ分割ノードを配置、接続したら編集します。最初に以下のように①のデータ分割手段を設定します。今回は「分位」ではなく、目的変数を与えて自動でグループ化する「最適」を用います。分割するターゲットを「期間」に指定②、最後に③目的変数を「解約」に指定します。

このままテーブル出力もできるのですが、どのように分割するのかを「ビンの値」タブの「値の読み込み」で確認します。
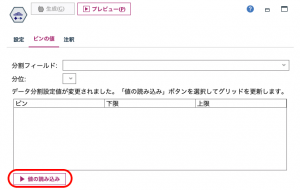
エントロピーを根拠に次の様に4群に分け、どの値で分割するのかブレークポイントを示しています。

プレビューすると、ちゃんとできていますね。
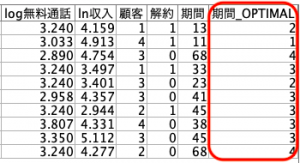
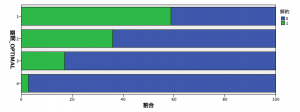
参考までに、棒グラフで正規化すると綺麗にグループで解約に差が出ています。グループ1はグループ4より20倍以上の解約率を持っています。説明変数としての活躍が期待できそうですね。
今回の例題で直感的に、「決定木を利用するのか?」と思われたユーザーも多いかと存じます。確かに決定木もグループ数とブレークポイントを決めるに役に立ちます、ただ「最適分割」は後続の予測プロセスに直接、特徴量を提供できる分、重宝するはずです。
それではそのまま予測モデルを「分割」つながりで作ってみます。
例題2:「顧客グループ毎にモデルを作り分ける」
出題は以下でしたね例題1の加工に続いて解約予測モデルをロジスティック回帰で作成してください。その際「顧客」フィールドの4群でモデルを作り分けてみます(モデルナゲットは単一とします)。例題1の手もカウントして3手詰めです。
フィールド「期間」は入力とせず、例題1で作成した「期間フィールド」を入力にしてみてください。

完成ストリームは次の通りです。入力からテーブルまで3ノード(3手詰め)。

用するので、オリジナルフィールドである「期間」のロールは「なし」へ。「顧客」フィールドの4群でモデルを作り分けるのでロールを「分割」にします。目的変数は「解約」ですのでロールを「対象」にします。
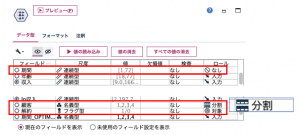
次にロジスティック回帰の設定です。今回は解約のフラグを予測しますのでプロシージャーは「二項式」を選び、方法には「変数増加ステップワイズ法」を選択します。
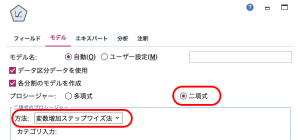
実行すると、出来上がったナゲットに分割のマークがついているはずです。ブラウズすると顧客1から4まででモデルを作り分けているのがわかります。出しわけずに、全体でモデル構築すると精度は79.1なのですが、顧客グループ2と3はそれより高い精度になりました。

ストリーム領域にモデルが複数並ぶことなく、単一のナゲットで各レコードに対応するモデルのスコアが付与されとても便利です。スクリプトでループするよりも圧倒的に楽だと思います。
分割するメリットと注意点
例題1で取り上げた連続値を分割する是非について考えてみます。数値をカテゴリデータに変換するのは情報量そのものは減少しますし、なんでもグループ化すれば良いわけではありません。どういう場合に有効でしょうか?
以下の様に、今回の例題データでは分割したことで、精度は僅かですが向上しています。単純に特徴量として有効になる場合はあります。
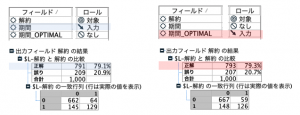
精度以上に期待できるのが解釈のサポートです。例えばワクチンの副反応の発熱がある範囲の年齢に集中した場合を想像してみてください。最適分割をするとその範囲の年齢を切り出して、他の区分よりも何倍リスクが高いか定量的に示せます。アンケートや広告では便宜上20代や30代とキリの良い区分を使いますが、ワクチンの副反応のブレークポイントは20歳や30歳でないはずです。結果から考慮したしかるべき最適点(ブレークポイント)を自動で計算できるなら使わない手はないと思います。
例題2でモデルを、あるフィールドで分割しました。実は分割フィールドは複数指定できます。

このパターンだとインターネットの有無2通りと顧客4群のかけ合わせでモデルは8つに分割されます。
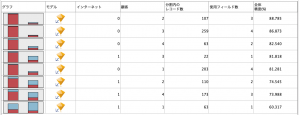
次のように合成変数を作成しておけば、分割を単一フィールドで実施しても同じことなのですが、試行錯誤したい時には手数が少なくてすみますよね。
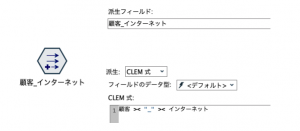
先の合成変数は出来上がったモデルを後続プロセスに組み込んで、性能比較に使っていただくと良いと思います。その際、推しノード#23でAITの林さんが紹介された以下の方法が便利です。出し分けたモデルの一致行列をすぐに比較できます。
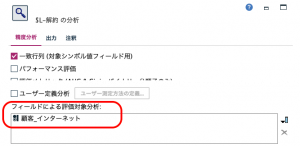
簡単にモデルを分割できるので、ついつい刻んで精度が高いグループを見つけたくなります。例えば地域単位でビジネスをしていると地域特性にあったモデルを作るなども有効です。しかしモデルが多くなればその分、管理が大変になるので、いたずらにモデル数を増やす前に、期待利益とコストのバランスを検討してみてください。
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「決定木モデルの所属ルール番号を各レコードに付与する」
決定木分析CHAIDを用いて、まず解約有無(フラグ型にしてください)を対象に予測モデルを作成してください。残る変数は顧客番号以外は全て入力にします。以下の図のように、一旦樹形図をIf-Thenルールに変換した上で、各レコードにルール番号を付与してください。利用するノードは1つのみ、データ型を含まず1手詰めです。
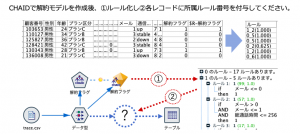
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/trace.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
例題2:「レコードにIf-Then条件をつけて所属理由を判読可能にする」
各レコードがどの条件に該当して、所属ルール番号になったかわかるようにフィールドを追加してください。手数は問いませんが、相応に駒数は必要で。10ノード以上は利用するはずです。(例題1の後続で9手以内に終局したら、IBM担当者までご連絡ください)。

例題データ
利用するデータは、例題1のものに加えこちらも利用します。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/rule_set.txt
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
ぜひチャレンジしてみてください。
さて次回のTips# 19は読売広告の齋藤さんが決定木について執筆されます。楽しみです。

磯部 葉月
株式会社リバーフィールド
代表取締役

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む

【予約開始】「SPSS秋のユーザーイベント2024」が11月27日にオンサイト開催
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
本年6月800名を超える方々にオンライン参加いただいたSPSS春のユーザーイベントに続き、『秋のSPSSユーザーイベント』を11月27日に雅叙園東京ホテルにて現地開催する運びとなりました。 このイベントは ...続きを読む