SPSS Modeler ヒモトク
Modelerデータ加工Tips#07-傾向スコアとGUIスクリプトで販促と効果の因果推論
2021年05月06日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさん、こんにちは 大日本印刷の西山です。
弊社では、お取引先の保有データをお預かりし、データ分析をもとに現状把握、課題抽出、仮説立案、コミュニケーション施策の企画・実行・検証等のマーケティング業務をトータルでサポートする取組みを行っております。
取組みを始めた当初は、専門的なスキルや知識を有した人材はまだ少なく、分析人材の拡充や育成に課題がありましたが、ノンプログラミングで利用でき、UIの充実したSPSS Modelerと出会ったことで、より多くの人材がデータ利活用に取り組むことができるようになりました。
近年、マーケティング、プロモーションでもデータ利活用が加速化し、よりデータ分析の精度を求められるようになりました。そこで今回のTipsでは、傾向スコアを用いた販促効果の検証方法についてご紹介いたします。
傾向スコア(Propensity Score)とは
傾向スコアをご存知の方も多いはずです。推しノード#06でIBM山下さんが触れているとおり、Modelerで2項判別の予測モデルを作るとモデルナゲットの設定から以下のように出力可能です。
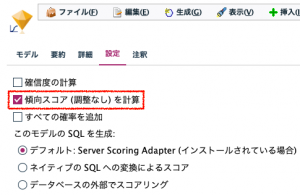
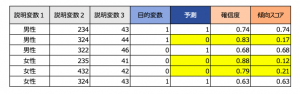
計算はとても簡単。「予測= 1」の場合は確信度が、「予測= 0 」の場合(図では黄色)は「1-確信度」と確信度の反転で傾向スコアが出来上がります。
傾向スコアがあると何が良いのでしょうか?
例えば顧客名簿からキャンペーンに反応しそうな1万名をリストしようとします。ところが「予測=1」が1万名に届かない場合には、不足分を「予測=0」の顧客からも選ぶ必要になります。そもそも「98%の確からしさで反応なし」は「2%の確からしさで反応あり」と読み変えられるのですからあらかじめ「予測=0」は確信度を反転、傾向スコアを求めておいて、上位1万名を抽出するのがスマートな方法ですよね。
傾向スコアと因果推論
傾向スコアが盛んに応用されるのは医療分野です。典型的な利用目的は「新しい薬の有効性の評価」。例えば新型インフルエンザのワクチン報道でも知られる「治験」は新薬を対象群に、コントロール群と呼ばれる比較対象にプラセボ(偽薬)を処方することで効果を検定します。その際、対象群とコントロール群は無作為で選出が理想なのですが、現実の治験者には属性上なんらかの偏りが生じます。このセレクションバイアスは年齢や社会的背景の類似性(喫煙・出産経験など)による共通の要因によって過大もしくは、過小評価に結果を導いてしまいます。このリスクを排除するには本来は同じ治験者で、新薬を処方した場合とプラセボを処方した場合を比較したいのですがそれはできないため、治験者の一人ずつに、共通の要因で傾向スコアを作成し、なるべく等質なペアを探す方法が傾向スコアによるマッチングです。
スタッツギルドさんのサイトにSPSS StatisticsのTipsとして具体例が紹介されています。
販促効果を傾向スコアを利用して検証する
さてここからが本題です。昨今、機械学習ブームで予測はするが、施策の検証まで手が回らないというコメントが散見され、不安視されています。確かに比較的低コストなメール販促は、オプトインしていれば多少のヒンシュクは承知で乱発傾向と言えます。しかし、どんな施策もやりっぱなしでは改善の余地がなく継続的に効果検証するのが重要です。
販促の効果をどのように評価するかは状況によって様々ですが、次のケースを題材に説明していきます。
ビジネス上の課題を解決するべく、過去の販促反応の学習モデルでリストを作ってクーポンを送付しました。パッと見いい感じの結果だと安心したのも束の間・・・・
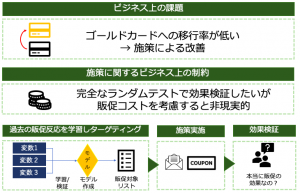
なんとある役員から「本当にキャンペーンの効果なの?」と責められます。もともとゴールドに自発的にしようとしていたカードの利用意欲の高い人が結果的に販促対象者だったのではないのか?という主張です。販促が原因ではなく、真の原因はカード利用意欲であって、販促コストはまるっと無駄だったのではと食い下がってきます。

販促を受け取り反応した人が、それが直接の原因でゴールドにアップグレードしたのかどうかは本人でないとわかりません。場合によって本人でもちゃんと説明できないこともあるのでマーケティングにおける因果関係の証明は極めて難しいと言われます。それでも、データを用いて販促を実施した者として、効果を推定する責任はありそうです。「しかるべき手続きに則って統計的には効果があると判明しています」と言えるかどうかは大きな差があるため、きちんと向き合う方が良さそうです。
わかりやすさを優先して諸々省略して恐縮ですが、以下の①と②によってカード利用意欲のバイアスを除去して販促がゴールド移行に効果を与えていると評価します。

Tips#05で出題したふたつの例題が①と②に対応していますので、具体的な手続きを確認してみます。
例題1:「傾向スコアから5分位グループを作る」
①の手続きのイメージはこちらです。これは簡単にできそうです。
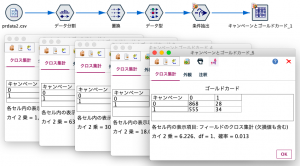
完成したストリームは次の通りです。データ分割ノードの1手詰ですね。
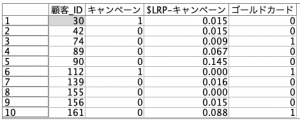
可変長ファイルノードに対象データを読み込みプレビューます。データは以下のリンクから入手ください。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/prdata2.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
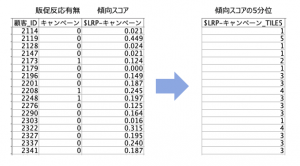
「キャンペーン」は販促反応の有無を意味し、「$LRP-キャンペーン」が販促反応を推測するロジスティック回帰モデルの傾向スコアです。モデル作成に利用した説明変数はこのデータには含まれていませんが、値が1に近いほど反応する見込みが高くなります。
「ゴールドカード」は、この販促後にカードをアップグレードしたかどうかを意味しています。よく見ると、販促に反応しても、ゴールドカードフラグがゼロのID30や、販促には反応せず、カードはアップグレードした顧客(ID74と161)も確認されるため、この販促の成功説に「まった」がかかるのも自然かもしれません。
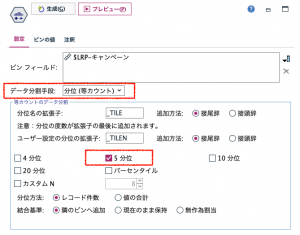
それでは傾向スコアを、なるべく同じ顧客数になるように5分割します。データ分割ノードを以下のように設定します。傾向スコアを対象にデータ分割手段を「分位」に変更し「5分位」を選択します。
出来上がると傾向スコア上位2割を5に、下位2割を1に分類した5分位が出来上がります。
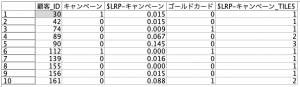
念の為、各グループの人数と販促の反応率を見ておきます。同じスコアを持つ人がいたため、完全には人数が一致していません。また本来だと5層目に向かっての反応率が上がるはずですがサンプルなので少し不格好になりました。
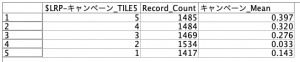
例題2:「傾向スコアから5分位グループを作る」
②の手続きに入ります。完成イメージはこちら。

そして解答例はこんな感じでしょうか。まず、条件抽出で「’$LRP-キャンペーン_TILE5′ = 1」と定義したら、クロス集計ノードの行に「キャンペーン」列に「ゴールドカード」を作ります。あとは残りの4層をコピペして抽出条件を変更すれば完成です、、が11手詰め(11ノード必要)ですね・・・・
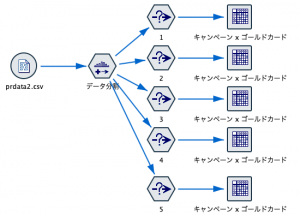
もっと短い棋譜はないものか、、Tipsらしくチャレンジしてみました。5手詰めです。GUIループを利用しているので最後のふたつにループを示すバッジが付いています。
早速作ってみます。

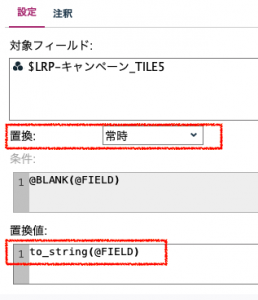
まず、置換ノードで、置換条件を「常時」とし、傾向スコアグループの整数をto_string(列名)で文字列に置き換えます。これは、ループの条件値をカテゴリ型として扱い、ループの回数を設定するためです。設定の手続きはこの後で登場します。
置換ノードを福岡大学の太宰先生が詳しく説明した記事はこちら→推しノード#15「置換」
続いてデータ型ノードで後続のループ処理でこれにより何回ループするのかを認識させるために、ちょっと面倒ですが値を読み込みます。データ型は予測のインプットとアプトプットのロール設定に使われる印象がありますが、今回のようにカテゴリ型のメンバーとして何層あるのかを記憶するのに重要な役割を担っています。
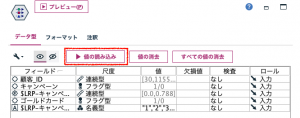
ここからループの設定に入ります。メニューからパラメータを設定を起動します。
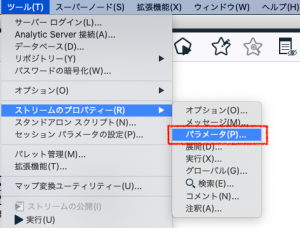
ここでは3箇所設定します。まずプロンプトはチェックを外してオフにします。次にパラメータに任意の名前をつけ(例えば「PS_Group」)、ストレージを文字列にします。
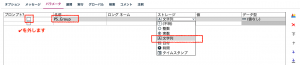
続いて今宣言したパラメータを定義します。条件抽出ノードの上で右クリックして反復キーの定義を選択します。
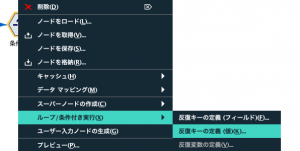
反復対象から値リストまで5箇所、上から順番に設定してみてください。
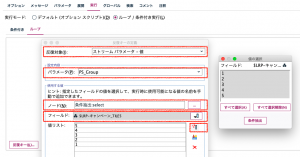
確定するとこうなるはずです。この時点で条件抽出ノードのアイコン左肩にループのバッジが付きます。
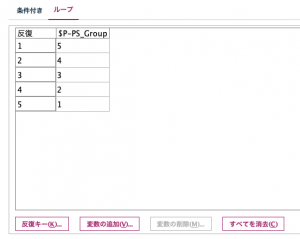
パラメータを宣言して、5つのメンバーの存在を定義しましたので、条件抽出に式として記述します。式ビルダー上ではフィールド名もパラメータもリストから選択できます。この式によって、5層を1度ずつループ処理してくれます。
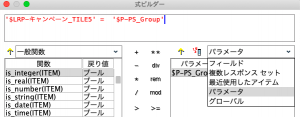
最後にクロス集計ノードです。
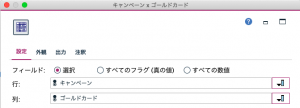
外観タブの行のパーセンテージを入れておきます。
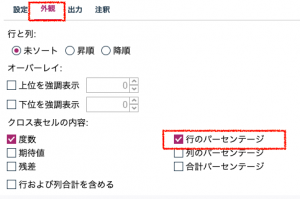
これで事実上は完成なのですが、このままだと出力されたクロス集計表がどの層に対応しているのか判別できなくなるので、クロス集計ノード上でも出力が明示的に識別されるように変数を追加しておきます。クロス集計ノード上で次のように変数の定義を呼び出します。
4箇所を順番に選択しテキストボックスには「_キャンペーンとゴールドカード」と記します。
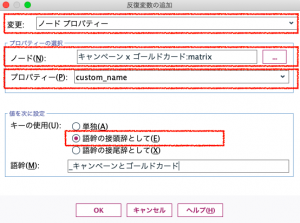
先に定義したループの反復キーに対応する変数をクロス集計に定義しました。
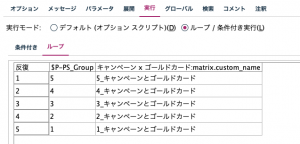
あとは実行するだけです。再生ボタンをクリックしてください。

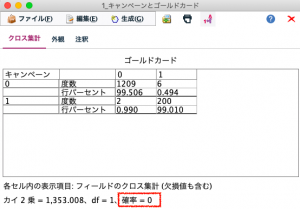
以下のような出力が5回表示されるはずです。以下は1層のクロス集計表ではキャンペーンの反応のない顧客では0.5%、反応があった顧客では99%がゴールドカードを結果的に保有しているとわかります。これだけ見ると歴然ですがカイ2乗検定の確率が0.05以下であれば、統計的に有意と裏付けられます。すべての層で有意でしたので「販促の結果はゴールドへのアップグレードに影響を与えた」と評価できました。
いかがでしたでしょうか?今回は分かり易さを優先して諸々省略していますがが施策効果検証や傾向スコアに関心を持たれたり、GUIループを試してくださると嬉しいです。
GUIループはこちらの記事にも詳しく書かれています!
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:7日後の日付を作成する
日付の加算なのですが、単純に7を足し算しても動作しないので工夫が必要です。
1手詰(1ノード)です。

例題2:6ヶ月後の日付を作成する
同じく1手詰めなのですが、年をまたぐ場合や閏年、月末が31日でない月の対応を考えると想像よりも手強いと思います。余力のある方は1〜12ヶ月をパラメータ設定できるスーパーノード作成にチャレンジしてみてください。

例題データ
https://raw.githubusercontent.com/yoichiro0903n/blue/main/data2.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
いかがでしょうか。IBM所属のSPSS Modeler イケメン棋士は例題1に3分、例題2には11分要したとのこと。
さて次回のTips#08はABTマーケティングの白岩さんが執筆されます。結構トリッキーな例題2の解説を伺うのが楽しみです。
ご期待ください。
SPSS Modeler 春のオンラインユーザー会が2021年05月21日金曜日に開催予定!
ご参加を希望される方は、IBMご担当者、またはIBMパートナーに、ご担当が不明の方はリンクの問い合わせ先までご連絡ください、、とのことです。

西山 忍
大日本印刷株式会社
情報イノベーション事業部 DXセンター
デジタルマーケティング本部
カスタマーサクセス部 第3グループ
リーダー

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む