SPSS Modeler ヒモトク
Modelerデータ加工Tips#06-@OFFSETでカテゴリ別商品ランキングを作成する
2021年04月23日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさんこんにちは株式会社ファミマデジタルワンの橋本です。
弊社(ファミマデジタルワン)は、ファミリーマート店舗や10万箇所以上の街のお店で使える、スマホ決済「FamiPay」を中心に、デジタル関連事業を展開しています。
私の担当するマーケティング推進部では、ファミリーマートに集積される様々なデータを用いて、メーカー様の商品開発からプロモーション、分析まで、マーケティング業務をトータルでサポートする取組を行っております。
私がSPSS Modelerを最初に使いはじめたのは2005年頃でした。未だ、データマイニングという概念が広まり始めたばかりの時代で、必要な分析スキルを有しているメンバーも限られている中、大量のPOSデータから様々な角度の分析結果を抽出するのはとても大変でしたが、SPSSとCADSの導入により、自動化、定型化が可能となり、効率的に分析を行う仕組みを開発する事ができました。
その後、暫く分析業務から離れていたのですが、一昨年より再びデータマーケティングに関わる事になり、新たに配属された複数のメンバーで、効率的にデータを可視化するべく、再びSPSS Modelerを利用させて頂いております。
このTipsではID付きPOSのサンプルデータを使って商品を評価する過程で役に立つ関数やデータ加工方法を紹介いたします。
例題1:「カテゴリ別商品ランキングを作成する」
元データと完成イメージはこちらです。

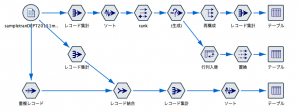
商品の売上ランキングをカテゴリ毎に表示してみます。6ノードで実現する2種類の方法を説明していきます。
まず①でデータを読み込みます。読み込むデータはTips#05で指定したsampletranDEPT2015.csvです。(→東京図書様のサイトからダウンロードはこちら)可変長ファイルノードで読み込みプレビューします。

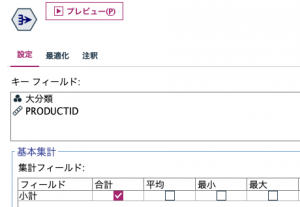
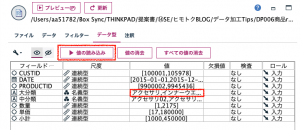
続いて②は以下のように大分類と商品IDで集計します。
③で多重ソートします。大分類を昇順にして売上は降順で並び替えます。

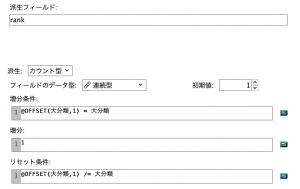
④にきました。ここが今回のポイントです!Tips#05でJALの竹村さんも力説されていました@OFFSETを使います。この縦方向を操る@関数を覚えると格段にデータ加工の効率が上がります。
派生モードを「カウント型」、初期値を「1」にしたら増分条件とリセット条件を以下のように記述してください。
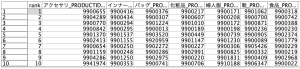
この時点でデータを見ると次のようになっています。見やすくするためにアクセサリの11位の次が527位までワープさせました。アクセサリの売上ランキング529位でこの部門が終わるとインナーウェアが始まり、カウントがリセットされているのが分かります。
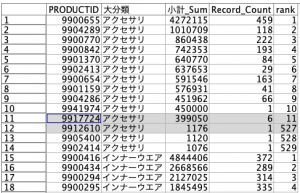
11位以降は今回除外ですので⑤の条件抽出がこちらです。
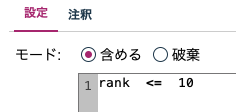
このノードの表記が(生成)である理由を自然に受け取られた方はさすがです!この条件抽出ノードは、手動配置と編集をせず、先のテーブルでrankの10のセルをハイライトして生成メニューから条件抽出ノードを自動生成させました(CLEM式は=から<=に修正しています)。表やグラフから次のノードを自動生成できる(作れる)のはModelerの凄いところです。
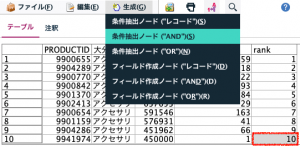
続いて、縦に並んだ大分類を列に展開するため⑥の再構成ノードを利用します。再構成ノードはIBM河田さんが推しノード#04で紹介されています。値フィールドは商品IDです。
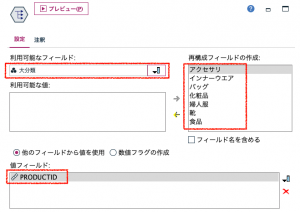
大分類の7つのメンバーがリストされない!?と慌てた方は、①のデータ読み込みまでお戻りいただき、「値の読み込み」をクリックしてください。データ型ノードを直前に入れて、値を読み込んでも同じなのですが1手無駄にしてしまいます。
あとは⑦の王手で投了です。IDなので最大値でも平均値でも、どれでもO Kです。
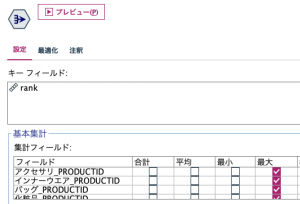
出来上がった表を確認します。
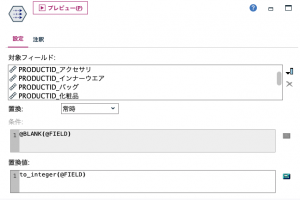
別の手筋も紹介しますね。⑥で行列入替を使います。
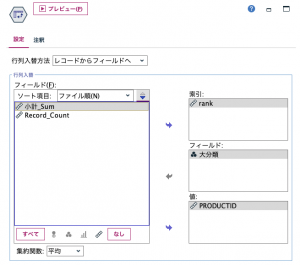
この方法だと商品IDが実数になっていますので⑦整数化しておきます。この時7つのカテゴリ全てを@FIELDで1度に指名できるのもModelerのスゴ技ですね。推しノード#15でも福岡大学の太宰先生が触れられています。
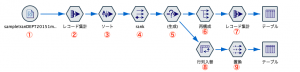
例題2:「客単価向上に貢献した商品のランキングを作成する」
元データと完成イメージはこちら。今度は顧客IDを利用します。

ストリームはノードを5つ利用します。
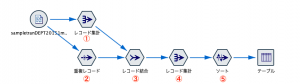
最初に①で顧客の単価を計算しておきます。
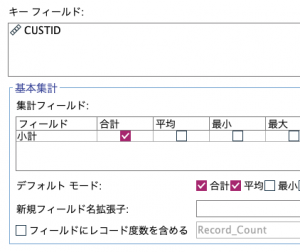
続いて②顧客と商品の組み合わせのレコードを重複を排除して作ります。レコード集計ノードでも同じことができます。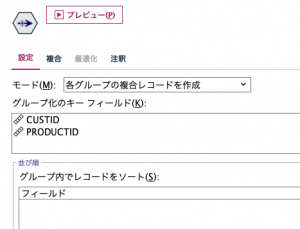
③で2つを結合します。キーは顧客IDです。全ての商品に購入顧客と客単価が紐付きました。
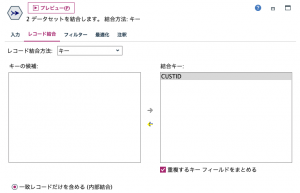
あとはジワジワ寄せて詰ませるだけですね。④のレコード集計と⑤のソートは以下のように設定します。
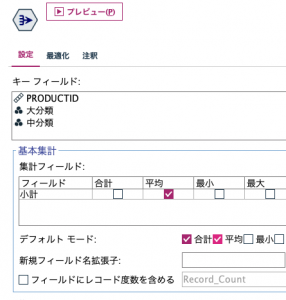

出来上がったテーブルを見てみます。
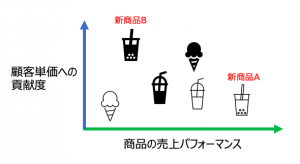
この商品分析には、重要な意味があります。例えば今期店頭に並んだ新商品を評価するとします。以下のグラフを見ると新商品Aは売上ナンバー1です。しかし、その商品を購入する顧客が他の商品を含めて沢山購入する人かというとそうでもないですね。商品単独で売れれば良いわけではなく、その商品と一緒に別のものを買ってもらわないと、来客増加が見込めないストアではAへの評価はイマイチです。一方新商品Bは優良顧客に支持されていて、この商品をむげにするとストアのファンが去ってゆくリスクがあります。盤上で地味な駒でも局面に応じて役割を発揮させられるかが重要なのは将棋もビジネスも(分析も)同じかもしれないですね。
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
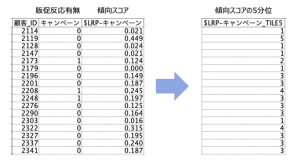
例題1:「傾向スコアから5分位グループを作る」
顧客に割り当てられた予測モデルの傾向スコアから顧客の数が2割ずつになるグループ(5分位)を作成してください。ノードは1つです(1手詰め)。
例題2:「5つのグループ間で販促と成果の有意差を検定する」
最後のクロス集計を含めて、11手詰め・・・がGUIループを使っていただくと5手詰めできます。ぜひチャレンジしてみてください。

例題データ
右クリックで「リンク先を保存」、または一度ブラウザで開いてから「ページに名前をつけて保存」を実行してください。
さて次回のTips# 07は大日本印刷の西山さんが執筆されます。傾向スコアを層別にして検定とは、一体何をテーマにしているのか解説を伺うのが楽しみです。
SPSS Modeler 春のオンラインユーザー会概要が発表されました! こちらも楽しみです。
SPSSをお求めのIBMご担当者、またはIBMパートナーさんに問い合わせいただくか、ご担当が不明の方はリンクの問い合わせ先まで、、とのことです。

橋本 ゆり子
株式会社ファミマデジタルワン
金融・マーケティング事業推進本部
マーケティング推進部

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む

【予約開始】「SPSS秋のユーザーイベント2024」が11月27日にオンサイト開催
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
本年6月800名を超える方々にオンライン参加いただいたSPSS春のユーザーイベントに続き、『秋のSPSSユーザーイベント』を11月27日に雅叙園東京ホテルにて現地開催する運びとなりました。 このイベントは ...続きを読む