SPSS Modeler ヒモトク
Modelerデータ加工Tips#04-行列入替で適合率PrecisionやF1スコア・MCCを求める
2021年03月30日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
みなさんこんにちは。 Western Digital®の小杉と申します。
弊社は米国に本社を持つHDD, SSD, Flash Memoryを主たる製品とする開発・製造・販売の会社です。弊社の出荷台数から考えますと、皆様が所有されておられるスマートフォン、タブレット、パソコン、HDDレコーダー等のデジタル機器のうち複数台に弊社製品が搭載されていると考える事が出来ます。したがいまして間接的ではありますが、ほとんどの皆様が弊社製品のユーザー様でおられます。この場をお借りしまして、日頃よりの皆様のご愛顧に感謝を申し上げます。
現在私はグローバルIT部門内に2018年に設立されたDigital Analytics Officeという部門に所属し、社内のHDD・Flash Memoryの開発/エンジニアリング部門を対象にデータアナリティクスの活用支援を行っています。SPSS Modelerを使い始めたのはHDDの品質保証部門に所属していた2008年頃にさかのぼります。当時手探りで始めた機械学習による製品の不具合原因判別予測ではアルゴリズムのチューニングに苦慮しましたが、ほどなくデータ加工が最も重要だと気付くことになりました。生産拠点であるタイにある工場では、Modelerを展開・教育を実施した直後からデータ加工への活用が一気に広まった事は今でも記憶に残っています。その後一年間は現地チームと週一回の電話会議によってModelerの使い方、モデルの性能評価・解釈・理解のスキルアップを図り、解析技術の定着化を図りました。この流れは現在まで続き、Modelerを活用した不具合発生原因解析・低減業務はすっかり日常業務として定着しています。
Modelerは判別予測モデルの性能を評価するために、評価グラフでROC曲線が書けますし、精度分析ノードで精度(Accuracy)やAUCが標準で出力可能です。また推しノード#23「自動分類」では精度分析ノードを使って適合率(Precision)や再現率(Recall)を表示させる方法が紹介されています。ですが我々は当時SPSSに依頼して実施頂いた導入教育の中で、性能指数の作り方を教えて頂きました。このTips#04ではModelerには標準で備わっていないモデル性能評価指標の作り方を紹介します。
混同行列Confusion Matrixと性能指標
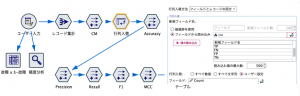
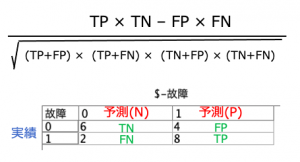
私どもはよく製品の検査のPASS(合格)/FAIL(不合格)の予測に用いるのですが、今回は、故障予測を例にします。例えばIoTセンサー情報から、ある設備が既に故障しているかどうかの予測モデルを作ります。実際に全ての時間帯で故障の有無を検査すると予測と結果の4パターンに分類され、Positive(陽性)/Negative(陰性)とTure(真)/False(偽)の頭文字などで表現します。
T P(真陽性)=予測通り故障
F P(偽陽性)=故障と思ったが故障していない
T N(真陰性)=予測通り故障していない
F N(偽陰性)=故障していないと思ったら故障だった
「P C R検査で選手の新型コロナウィルス感染を疑ったが、精密検査したら偽陽性(F P)だった」とニュースで耳にするようになり、この分類が身近なものになってきました。
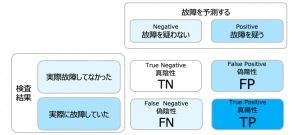
この4つのパターンから以下のような予測モデルの性能評価が行えます。
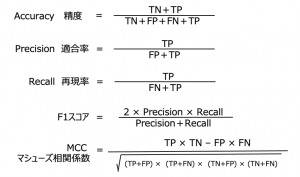
前回のTips#03で出題した、「Precision」と「MCC」は、解けましたでしょうか?
例題1:「Precisionを作ってみる」
元データと完成イメージはこちらです。
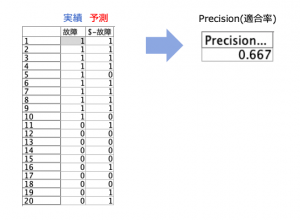
式と考え方は以下の通り。

まずは対象データを読み込みます。前回のTips#03の例題の説明の通り、ユーザー入力かpythonスクリプトで準備してください。


完成済みのストリームはこちらです。

まずフィールド作成ノードPrecisionフラグ列を作ります。故障と予測($-故障=1)して実際故障(故障=1)なら1に、実際故障していない(故障=0)場合は0と定義します。故障と予測していない($-故障=0)レコードはundefを用いてヌルにします。
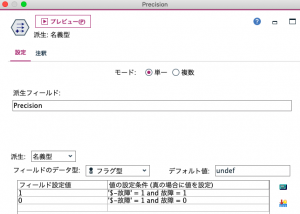
続いてレコード集計ノードで、先に作成したフラグの平均を取ります。キーフィールドはブランクのまま全レコードを要約します。
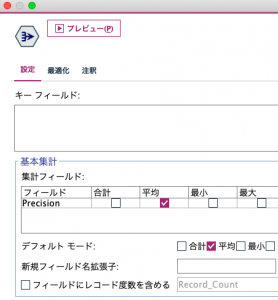
故障と予測しなかった列を欠損値にしたことで、分母は故障を予測したものに限定され(FP+TP)、その上で実際に故障していたTPの比率を求めPrecisionが作られました。フィールド名は適宜修正ください。

出題時にクロス集計を使わない前提を取りましたが、その方法を紹介しておきます。私どもは多くの場合、この方法でPrecisionとRecallを確認します。
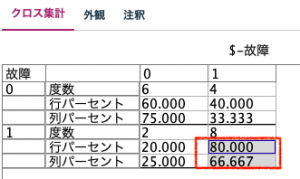
クロス集計ノードで行に「故障」列に「$-故障」を選択します。
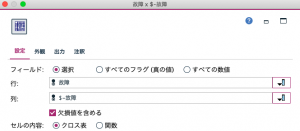
外観タブの設定で行と列のパーセンテージを求めます。
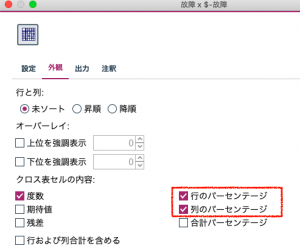
赤枠の列パーセントがPrecisionで行パーセントがRecallです。
例題2:「MCCを作ってみる」
次はマシューズ相関係数を作ります。データと完成イメージはこちらです。
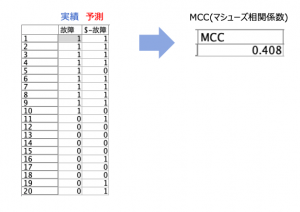
式は次のとおりです。相関係数ですので−1から1の間をとり、ゼロから遠いほど、相関が強く、性能が高いと判断できます。
出来上がったストリームは以下のとおりです。

レコード集計で混同行列(Confusion Matrix)の組み合わせ4通りを作成し、レコード数をカウントします。
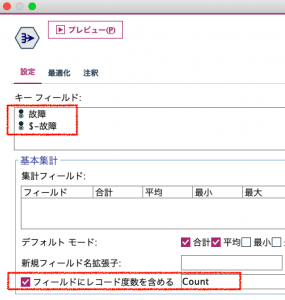
続いてフールド作成ノードで4つのレコードにTP・FP・TN・FNの4つの識別ができるようにラベリングします。
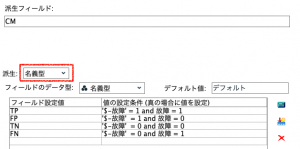
ここまでのデータを確認します。混同行列の4通りが要約されています。
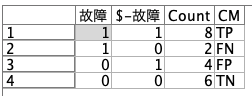
ここでModelerの数あるノードで、試してみないと、どう挙動するかイマイチわからない「いけず」な行列入替ノードを使います。赤枠のとおりに設定してみてください。
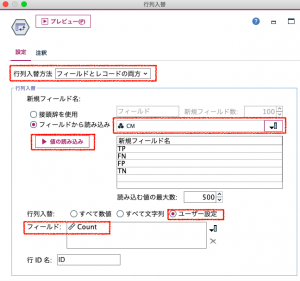
プレビューすると、こうなっているはずです。これができれば、あとは四則演算で、公式の通りです。
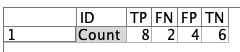
MCCの式をフィールド作成で記述します。

きちんとできたか確認します。

Recall(再現率)やF1スコアも含めて出力する
例題2の行列入換ができた段階で、以下が全て作れます。

ストリームは以下の通り。
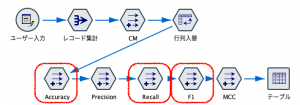
まだ触れていない赤い楕円の3つの関数です。
Accuracy

Recall
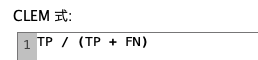
F1スコア
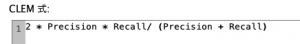
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「車両の時刻と座標から平均速度を求める」
以下のような車両の位置記録情報から平均速度を求めてください。車両は複数ありますので、IDの入れ替わりに注意してください。
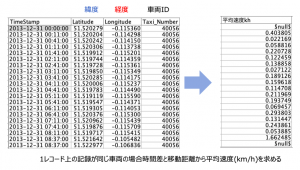
余計なことですが、データは擬似的に作られているため、このタクシー車両が、業務怠慢な挙動や法定速度を超過していても見逃してください。
例題2:「出発点から各レコード時点の直線距離を求める」
車両IDが最初に登場する出発点を各車両の拠点と設定し、後続の位置情報までの直線距離を求めてください。
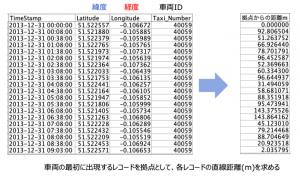
例題データ
SPSS Modelerをインストールすると同梱されるサンプルデータTaxiLocationData.csvを利用します。DEMOSというフォルダを確認ください。
座標から距離を求める公式の例
距離を求める方法はいくつかありますが、今回は特定の都市内の車両移動ですのでヒュベニの公式を例として利用します。

緯度と経度を起点と現在で記していますのでフィールド名を充当して利用ください。
sqrt( ( (6356752 *(abs(緯度 – 緯度起点) *(pi / 180)) ) ** 2) + ( (6378137 * (abs(経度 – 経度起点) *(pi / 180)) * cos(((緯度起点 + 緯度)/2) * pi/180) )** 2) )
いかがでしょうか。IBM所属のSPSS Modeler 女流名人は例題1に4分、例題2は9分要したとのこと。
さて次回のTips# 05はJALエンジニアリングの竹村さんに例題の解説をいただきます。
楽しみです!

小杉 潔
Western Digital®
IT Digital Analytics Office
Analytics Business Partner

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む

【予約開始】「SPSS秋のユーザーイベント2024」が11月27日にオンサイト開催
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
本年6月800名を超える方々にオンライン参加いただいたSPSS春のユーザーイベントに続き、『秋のSPSSユーザーイベント』を11月27日に雅叙園東京ホテルにて現地開催する運びとなりました。 このイベントは ...続きを読む