
上田 延寿
日本アイ・ビー・エム株式会社
東京ソフトウェア&システム開発研究所
データサイエンス&AIサービス
2020年08月25日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:

日本アイ・ビー・エムの上田です。
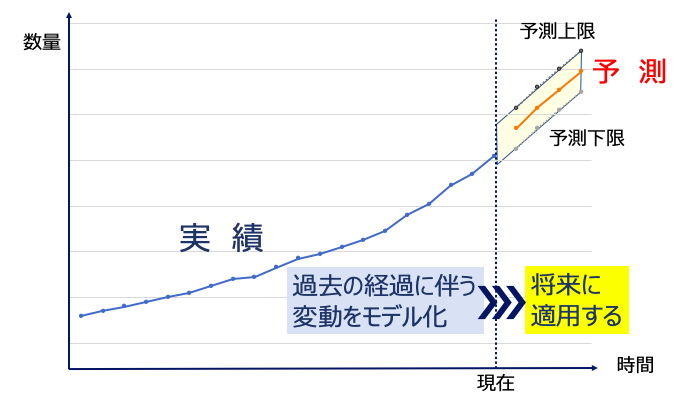
商品やサービスが将来どの程度売れるか推測する機会をお持ちだったことはないでしょうか。グラフを作り、経験に照らして鉛筆を舐めながら「このくらいかな?」と勘を働かせても良いのですが、SPSS Modelerでの統計モデル作りをお勧めします。アルゴリズムとパラメータは自動選択してくれますのであっけなく出来上がります。内部的には、丁寧に対象の時間経過に伴う変動(過去の傾向)をモデル化し、将来に適用して予測値を得られます。そして結果としてチャートのように予測を幅で扱うことで経験や勘よりも業務上のリスクや機会をコントロールできるのです。
予測する期間の幅が時間や日にち単位なら短期予測、月や四半期単位なら長期予測と区別されますし、要因データを用いるか、季節性を考慮するのか、手筋や流儀は様々なのですが時系列予測の原理は同じです。それを素早く実現してくれるのが、「時系列ノード」。とても便利な私の推しノードを、具体的なプロセスに照らしてなるべくシンプルに紹介します。
将来予測の手法や分類は様々です。例えば顧客調査を利用して先読みするなどもあり、コンセプトやプロトタイプの評価で市場にリリースされた後の売れ行きを予測する場合などもあります。今回は過去の実績を定量的に扱うケースを取り上げます。
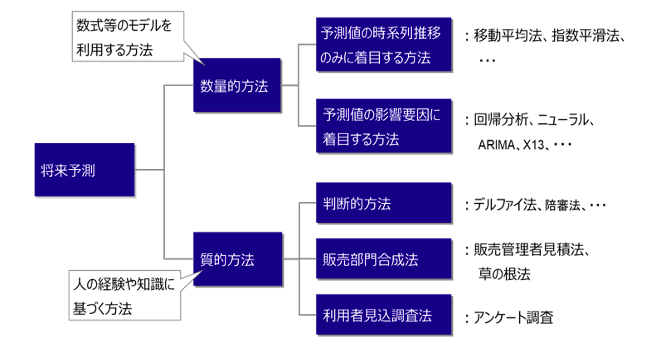
時系列ノードは、予測値の影響要因に着目する方法に属する「指数平滑法」、「ARIMA」の一方を明示的に利用するか、自動選択させて利用します。
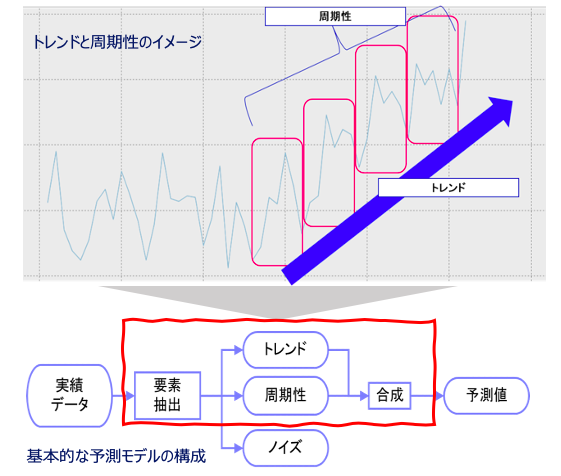
時系列予測は、対象の過去の実績の数量を使用して、将来の数量を予測します。基本的には、過去の実績から、トレンドと周期性の要素を抽出し、これらを組み合わせた予測モデルを構築します。
コンビニの売上予測を例にします。3店舗の1月1日から11月22日の約1年分の飲料製品販売実績データから、今後1週間の販売量を予測します。実績データの他に、販売に影響があると思われる天候と、特売(イベント)有無に加え近隣に存在する大学の休講情報も加えてみます。天候は1週間分の予報、特売や大学の情報は同じく向こう1週間分の予定を含んでいます。
まずは、これらのデータを日付をキーにして結合します。
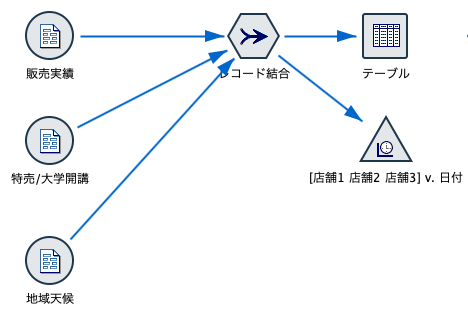
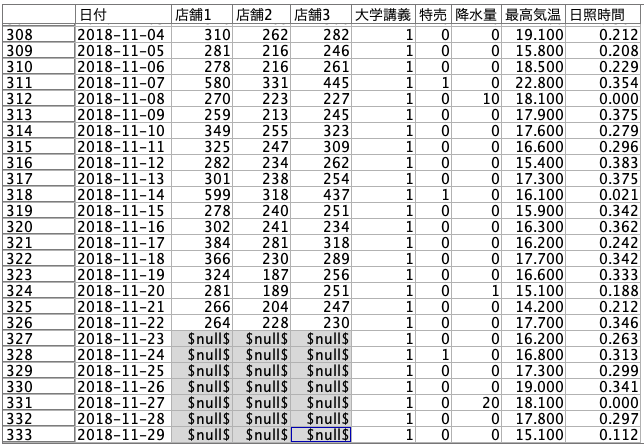
出来上がったデータです。11月22日を現在と想定しているため、そこから11月29日までの7日間は実績がNULL値(無効)になっており、大学休講や特売有無の計画と天気の予報のみが記述されています。
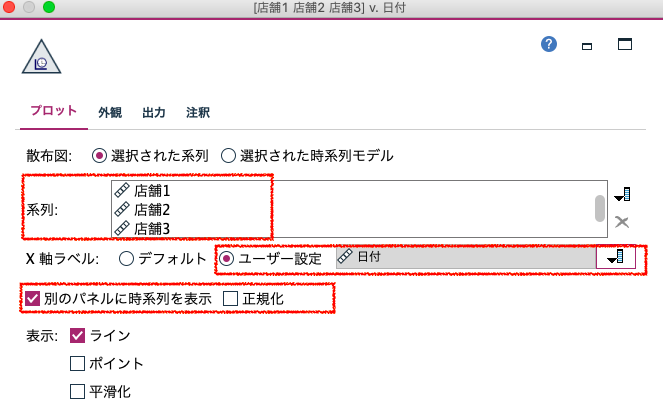
予測する3つの店舗の販売量を時系列グラフで表示します。設定は以下の通りです。
「プロット」タブで、表示する系列や表示方法を設定します。
散布図で、「選択された系列」を選択します。
系列で、「店舗1」、「店舗2」、「店舗3」を選択します。
X軸ラベルで、「ユーザー設定」を指定し、「日付」を選択します。
「正規化」のチェックボックスを外し、そのままの値で表示します。
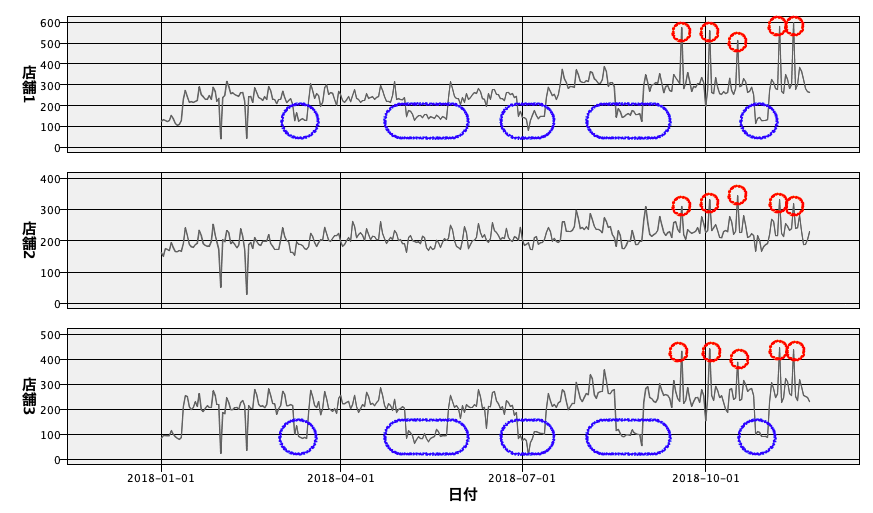
店舗1と3は、実は大学にかなり近いため、休講期間に販売が100前後まで落ち込んでいるのがわかります(青)。またどの店舗も特売の影響を受けているようで、9月以降に何度かスパイク(赤)しています。時系列ノードの良いところは、影響しているかどうか不明確なものでも一旦モデルに投入してみて、効いていれば考慮し、効いてなければ無視してくれるところです。またコーザルと呼ばれる要因データが仮に存在しない場合には、自分自身の過去の挙動のみを説明変数に変換して将来を推測できる特別なアルゴリズムです。
データの型を確定させてから時系列ノードを接続し、パラメータを設定していきます。「フィールド」タブで、対象、入力の候補、イベント及び干渉を設定します。
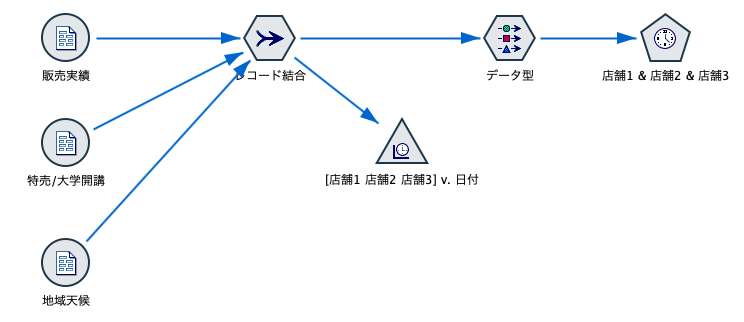
まず「ユーザー設定フィールドの割り当てを使用」を選択します。
「対象」は、予測対象の3フィールドを指定。今回は3系列のみの予測ですが、100を超える多品種を多モデルで同時に生成できます。
「入力の候補」は、予測値を算出する際に影響すると考えられるフィールドを指定します。今回はCSVで準備した過去と予報のデータですが、IBMでは気象データ(The Weather Company)をAPIサービスとして提供していて、Modelerの「TWCインポート」ノードから参照すると、タイムリーに座標ごとの予報が取得でき、とても便利です。
「イベントおよび干渉」は、予測値を算出する際に影響すると考えられる販売促進などの予測可能な繰り返し発生する状況を意味します。これは停電や従業員のストライキなど、一時的な出来事も含みます。選択するフィールドは、事前に、ストレージを整数に、尺度をフラグに設定することに注意します。
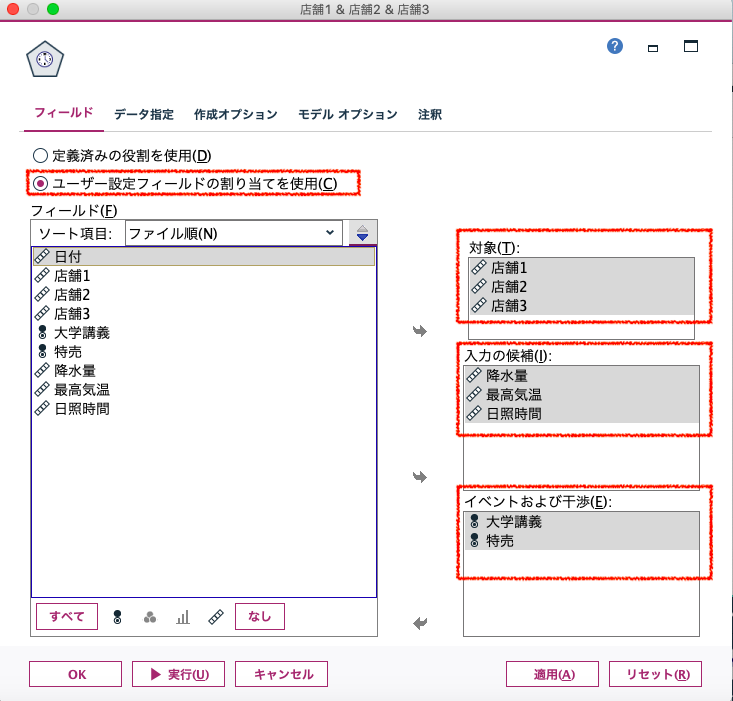
次に、「データ指定」タブで、予測のタイミングを設定します。
項目の選択で、「観測」を選択します。「日付/時刻フィールドごとに観測を指定する」を選択します。
日付時刻フィールドで「日付」を選択し、時間区分で「日」を選択し、週当たりの日数で「7」をしています。
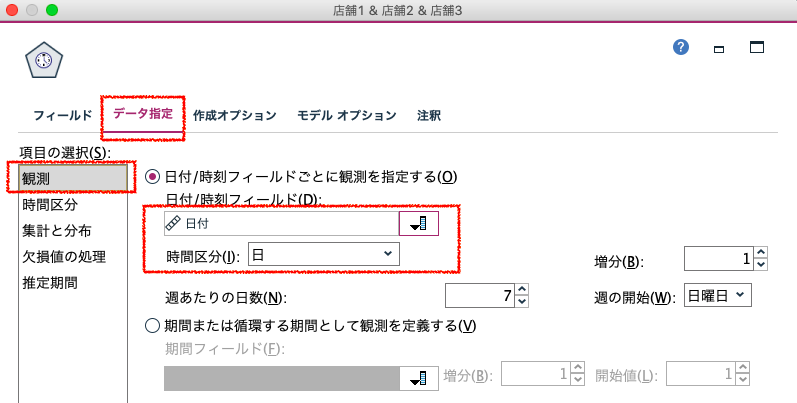
さらに「データ指定」タブで、モデリングに利用する期間を設定します。
例えば366日より以前のデータは、ビジネスの制約で常に切り捨てながらモデルを作り続けたい場合、あるいは常に直近の100秒間は、評価用にモデル作成に利用したくない場合にこの推定区間設定をします。最後の7日は説明変数用の未来の枠であるため学習から排除します。NULL値を含まず最終レコード全てを使ってモデリングする際には「モデルオプション」タブで将来予測させるN日を拡張させて実行します。
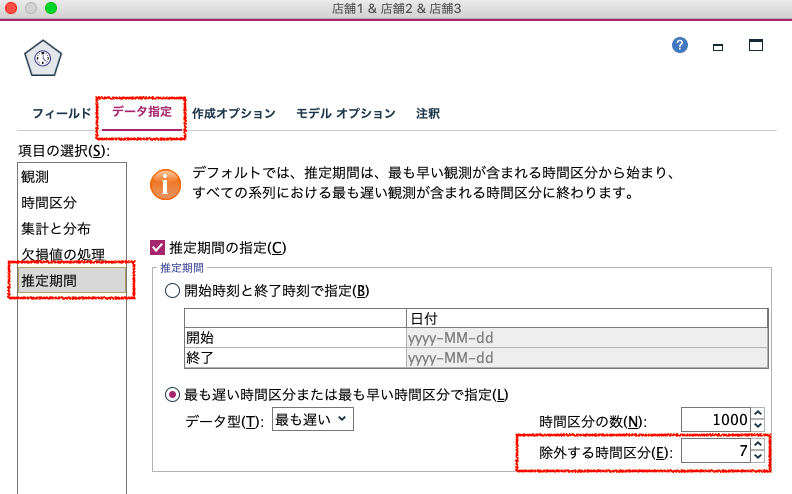
最後に、「作成オプション」タブで、モデルを構築するオプションを設定します。
項目の選択で、「全般」を選択します。方法で、「エキスパートモデラー」を選択します。これにより、指数平滑化とARIMAモデルから、誤差が最小になるように、階差(ラグ)や季節性のパラメータが調整されたモデルが構築されますが、必要に応じて、選択します。
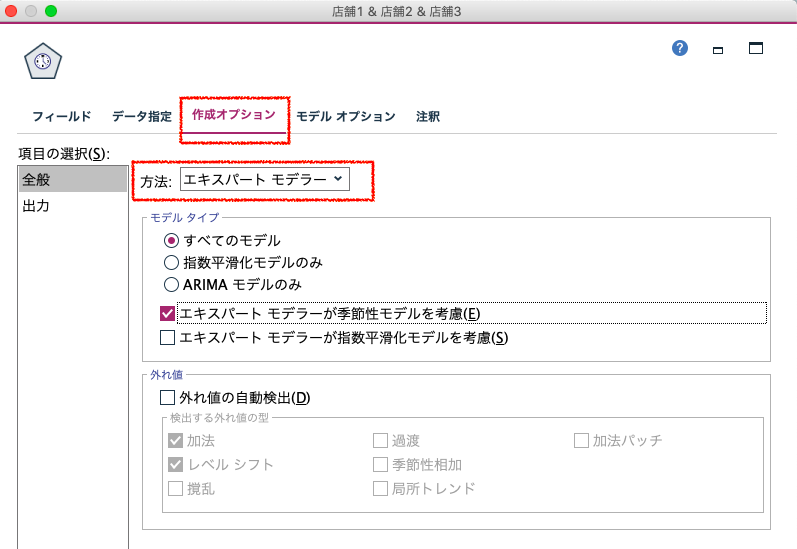
作成オプションの方法には、3種類あります。
時系列ノードの「実行」を選択すると、モデルが構築されます。
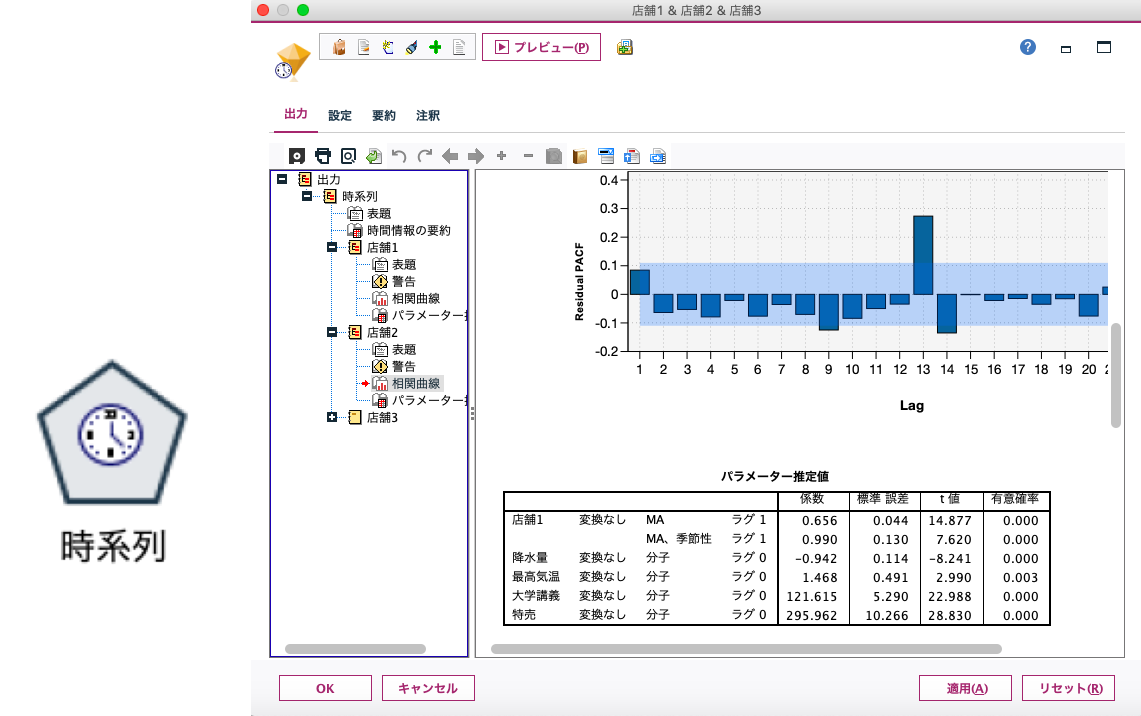
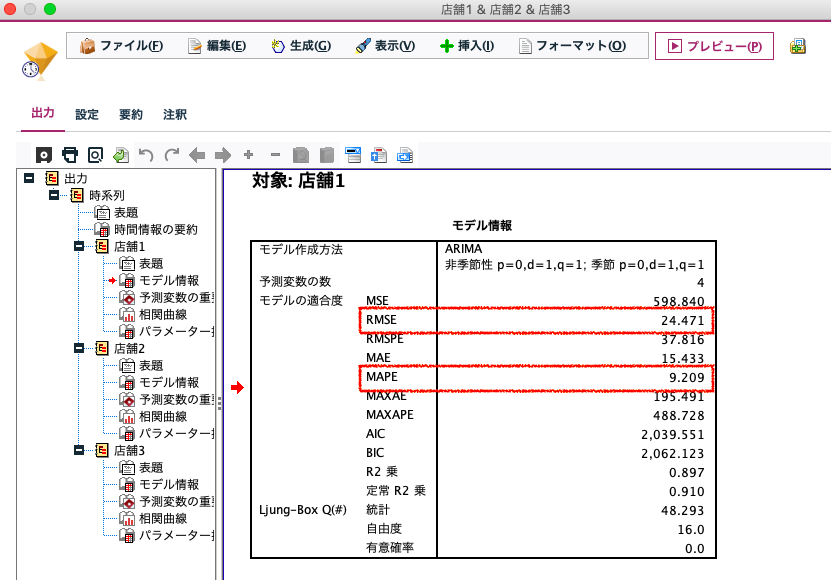
構築されたモデルを開くと、店舗1では、ARIMAが自動選択されたことがわかります。RMSE(二乗平均平方根誤差)が24.471、MAPE(平均絶対誤差率)が、9.209となりました。
内部でパラメータを試行して誤差が最小になるようにセットされた結果です。
RMSEもMAPEも値が少ないとモデルとしての性能が高いことを意味するのですが、肝心なことは実際の業務に当てはめて実効性をどの程度確保できるかです。どんなに予測精度が高くても、ビジネスプロセスに組み込まれなければ意味がないですし、逆に精度が低くても現在の人手による対応よりはるかに成果を期待できる場合もあるのです。予測精度よりも施策の精度を検討する必要があります。
また、将来の値もさることながら、どの要因が予測に影響を与えるのかを捉えるだけで業務改善できる場合もあります、今回は、降水量、最高気温、大学講義、特売が予測モデルを構築するのに有効として採用されています。要因のインパクトとその影響度合いがわかるだけでも適切な手を打てる場合があると言われています。
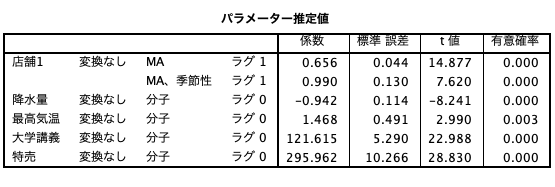
またModelerの多くのアルゴリズムに搭載されている重要度分析も、周囲に説明するときに役に立ちます。このグラフは合計で1となるように比率で表されているため要因の寄与度は別の要因の何倍なのかがわかりやすく、用途によっては必要な投資配分の根拠になり得ます。なお、この重要度分析は時系列ノードの「作成オプション」にある出力項目に、あらかじめチェックをしておく必要があります。
テーブルノードを接続し、「実行」を選択しますと、店舗1から店舗3の2018-11-23以降の7日間の予測値が確認できます。
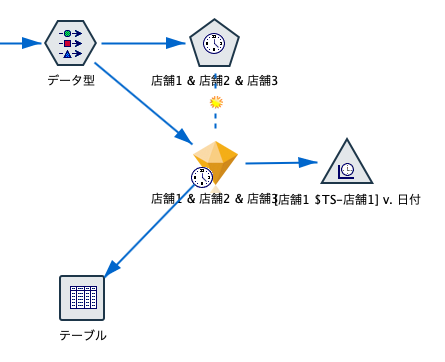
各対象フィールドの信頼区間の下限値と上限値(デフォルトの接頭辞 $TSLCI- および $TSUCI- が付きます)も算出されます。
時系列データをグラフで確認する場合は、時系列グラフノードを接続し、パラメータを設定します。
系列で、「店舗1」、「$TS-店舗」を選択します。
X軸ラベルで、「ユーザー設定」を指定し、「日付」を選択します。
「別のパネルに時系列を表示」のチェックボックスを外し、一つのパネルに、全系列を表示します。「正規化」のチェックボックスを外し、そのままの値で表示します。
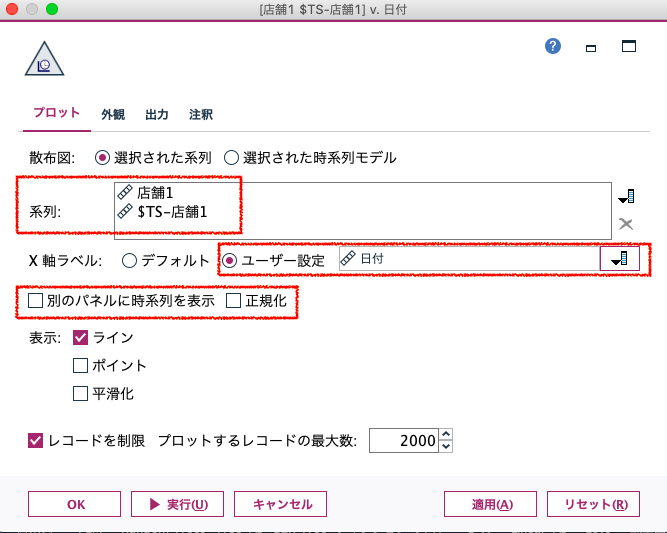
時系列グラフノードの「実行」を選択しますと、グラフが表示されます。
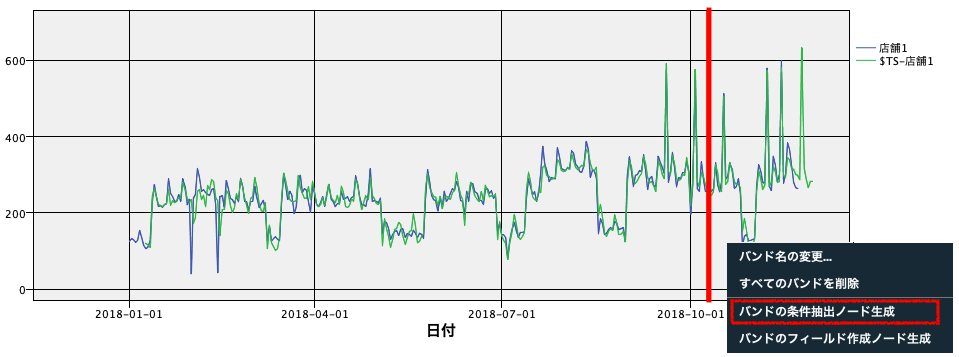
10月をハイライトしてみます。インタラクティブモードで赤い縦棒を10月3日近辺に配置して、その右側で、右クリックすると期間を抽出するノードが自動生成されます。
今度は時系列グラフに95%信頼区間を表示させるために2つの系列を追加します。店舗1の下限である「$TSLCI-店舗1」と上限を表す「$TSUCI-店舗1」です。
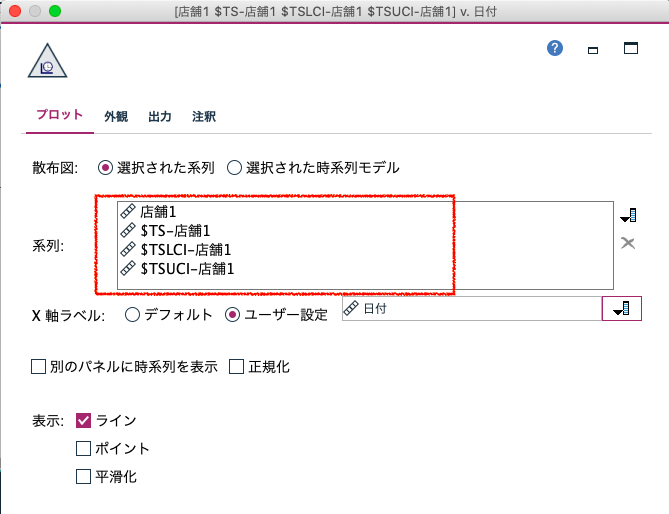
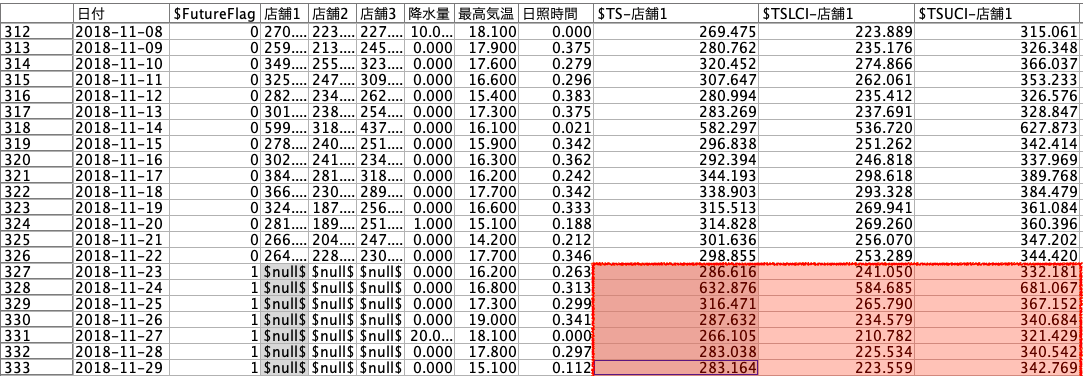
グラフを実行すると店舗1の2018-11-22までの実績販売数量と2018-11-29までの(平均)予測販売数量、95%信頼区間による下限値、上限値が確認できます。
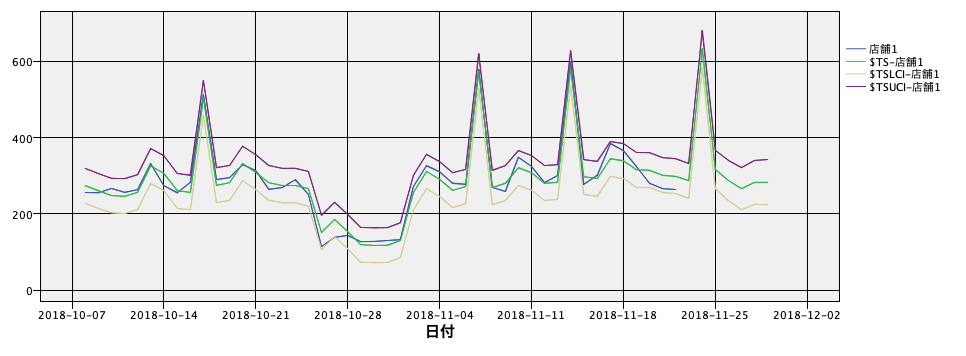
例えば、11月23日以降の予測値を利用して、(平均)予測販売数量と下限値の間に生産数量を設定しますと、統計的に売れ残りリスクを減少でき、(平均)予測販売数量と上限値の間に生産数量を設定しますと、欠品を削減できます。
この上限と下限の間で多くの事象が起きるという前提に立ち、逆に一定の割合で外すことを考慮すると将来への備えを最適化させることも可能です。
時系列分析は、かつて、データを可視化してからモデルを選定し、改めて必要なデータを検討しながら最終的にパラメータチューニングする大変な作業でした。しかも継続的にモデルをメンテナンスして業務に組み込むなどは至難の技だったと言えます。
しかし、「時系列ノード」はその手間の一切を肩代わりして分析者に「業務への適用」や「実装後の劣化の対処」、また「新たなデータの候補探索」や「欠損や特異値の手当て」に時間を割けるようにしてくれました。
重要なことは将来の値を完璧に当てるではなく、どの幅で将来値を想定しておけば業務上のコストが下げられ、利益を生み出せるかと視点を切り替えることだと考えます。
将来の出来事を当てるゲームはせずに、外れる幅をコントロールしながら上手に外して勝負に勝つ、そういったチャレンジを皆様が「時系列ノード」と実践していただけると幸いです。
次回のリレー連載、推しノード#15は福岡大学の太宰先生に「置換ノード」について解説いただきます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
上田 延寿
日本アイ・ビー・エム株式会社
東京ソフトウェア&システム開発研究所
データサイエンス&AIサービス

皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む