
山下 研一
日本アイ・ビー・エム株式会社
クラウド&コグニティブ・ソフトウェア事業本部
Data and AI事業部
データサイエンス&AI テクニカルセールス
2020年04月30日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:


今回は、SPSS Modelerノード人気投票で第一位を獲得した絶対エースCHAIDを取り上げます。CHAIDを使ったことのない方は絶対エースとして君臨する理由を、よく利用する方にはその魅力を再発見いただけるようにお伝えできればと思います。
なお、この記事は予測分析の用語をある程度ご存知の方向けに書かれています。もしご存知なければ、まずは「決定木」「予測モデル」「特徴量」の意味を調べてみてください。
CHAID(正式名称:CHi-squared Automatic Interaction Detector)は決定木で、古典的な予測アルゴリズムの一種です。ディープラーニング、Random Forest、XGBoost、LightGBMなど、より複雑で予測精度が高い予測アルゴリズムがどんどん出てくる中、なぜ今更シンプルな決定木なのでしょうか?
(1)解釈が容易で説明しやすい
予測モデルはとにかく予測精度さえ高ければ良いかというと、それだけではありません。Kaggleコンペと違い、実際の業務で活用するには「説明しやすさ」が重要になることがしばしばあります。例えば次のような場合です。
(1-1)上司にプレゼンやレポートで分析結果を説明
説明を受ける方々は必ずしも数学の専門家ではないのですから、専門用語が頻発するだけで受け入れてもらえないかもしれません。かといって「とにかくこのような予測結果が出たから信頼してください!」と伝えても、簡単には合意してもらえません。
「直近5年間の購買実績から、40代女性で、クレジットカードを通販ではなく主に店舗で使うお客様は、通常より2.5倍もこの商品の購入確率が高いのがわかりました。」という分析結果だとどうでしょう?具体的で説得力が違います。決定木グラフもこのような法則をまとめた図として説明の役に立ちます。
(1-2)アクションする人の納得感
予測結果を実際にアクションに落とし込むのがWebサーバーのプログラムなど機械の場合は、複雑で人間が理解しづらい予測モデルでも淡々と実行し、結果を出してくれます。しかし、アクションするのが営業職や窓口業務など人間の場合はどうでしょう?「このスコアの高い順にお客様にアプローチして」とリストを渡されても、「いやいや、どう考えてもこのリストここがおかしいでしょ。現場の経験と勘を舐めないでほしいね。」と、なかなか今までの行動を変えてはくれないものです。どんなに精度が高い予測でも実行されないと意味がありません。人が動くには納得感が大切です。具体的な法則が提示され、「このお客様はこの法則に当てはまるから、これだけ結果が期待できる」と説明があると、納得感が出ます。
(2)システムに組み込みやすい
決定木はIF-THENルールの集合として、予測モデルをそのまま組み込めないシステムにも容易に組み込むことができます。例えば、Excelマクロ、BIレポート、RPAなどに組み込むことで、すぐに業務で活かせます。
ただし、この方法は諸刃の剣でもあります。予測モデルの更新に手間がかかり、後々メンテナンスが大変になりますので、注意が必要です。予測モデルをシステムへ直接組み込める場合は、そちらの方がお勧めです。
(3)現状分析や原因分析にも有益
決定木は予測に使われるだけではありません。特定の指標(目的変数)を基準に分類する手法でもあります。教師なし学習のクラスタリングとはまた違った観点で、特定の指標が特徴的なグループ(例えば、特に不良率が高いロット、特に離反率が高い顧客層など)がどのような性質でどれだけあるか、といった現状分析に使えます。
また、人がBIツールなどを使ってデータを深掘りする代わりに、自動的に深掘りしてくれる手法とも言えます。特定の事象(不良品発生や契約の解約など)がどのような条件で起きているかを、人間ではやりきれない多くのパターンで細かく場合分けして探ることができます。
予測だけを目的としたブラックボックスな予測モデルでは真似できない利用法です。
決定木の中でもCHAIDは特に「説明しやすさ」に優れています。「多分岐かつ、分岐に特徴量が繰り返し使われない」ためです。以下はCHAIDの一部を切り取った例で、特徴量「年齢」によって4つに分岐しています。32歳から38歳をピークとした、年齢と目的変数の非線型な関係をわかりやすく表現できています。
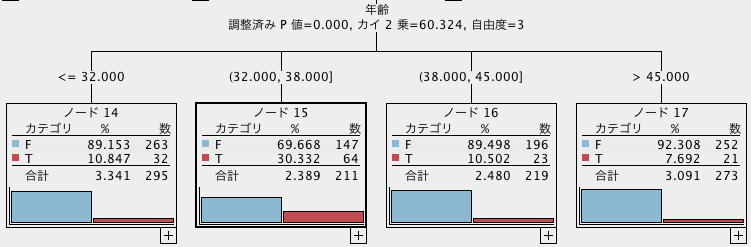
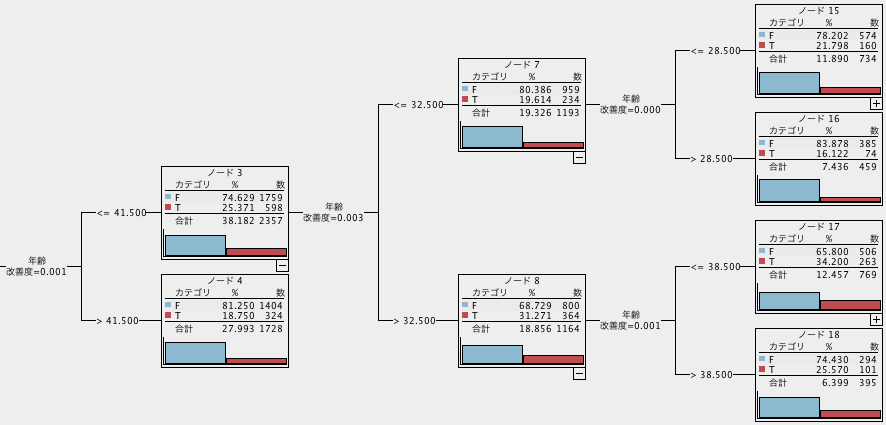
「2分岐で、分岐に特徴量が繰り返し使われる」CARTでは以下のようになります。年齢に関して同じような分岐条件になっていますが、図から直感的に年齢と目的変数の関係を捉えるのが難しくなってしまっています。この例では年齢による分岐が固まって登場していますが、他の特徴量分岐に混じって決定木のあちこちに何度も年齢による分岐が登場すると、ますます解釈しづらくなります。
同じアルゴリズムでも、ソフトウェアによって実装に違いがあります。SPSS Modelerならではの特長もご紹介しておきましょう。
(1)目的変数・特徴量のデータ型や尺度がフレキシブル
使うデータが数値/文字列、連続型/フラグ型/名義型、何でもそのまま使うことができます。他ソフトウェアやオープンソースでは、データ型を数値に変換したり、名義型を数量化・フラグ化したりする必要がある場合があります。SPSS Modelerではそのような処理は自動的に行われ、人の判断が重要な本来の特徴量エンジニアリングに集中できます。
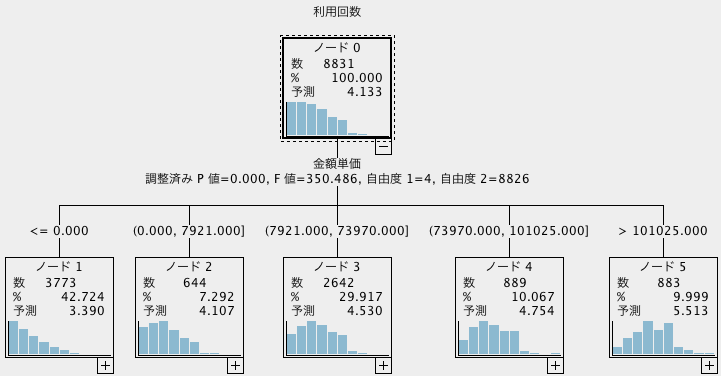
CHAIDはクラス分類として使われることが多いかと思いますが、目的変数を連続値にすると、数値予測としても使うことができます。その場合、決定木グラフの度数表示は以下のようにヒストグラムになります。
(2)見やすく、活用しやすい決定木グラフ
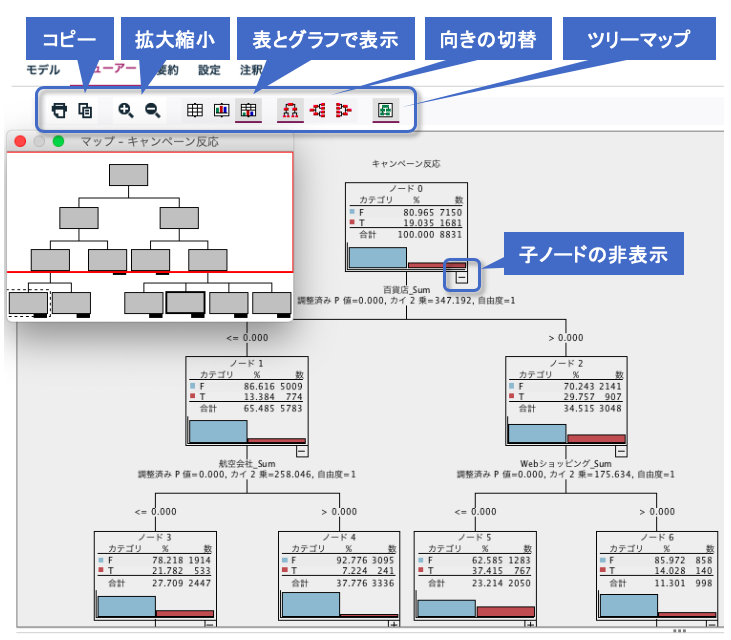
決定木グラフビューアーにはCHAIDをさらに活用しやすくする機能が揃っています。
(2-1)コピー
クリップボードに画像として決定木グラフをコピーできます。以下グラフの見栄えを調整する機能と合わせて、分析結果レポートに適切なグラフをすぐに貼り付けられます。
(2-2)拡大縮小
決定木全体図を捉えたり、個別の分岐条件や数値を確認したり、目的に応じて見やすい大きさにできます。
(2-3)表とグラフで表示
表とグラフ両方を表示すると、詳細数値と分布概要を1画面でコンパクトに確認でき、お勧めです。
(2-4)向きの切替
使っているモニターの形や貼り付け先レポートのスペースに応じて、見やすい向きにすることができます。
(2-5)ツリーマップ
決定木全体のうち現在表示している箇所がすぐわかり、簡単に移動できます。
(2-6)子ノードの非表示
それより下の分岐を非表示にし、省略したい部分を見せないようにすることができます。いわゆる枝切りとは違い、決定木モデルを変更せずにグラフの見栄えを整えることができます。
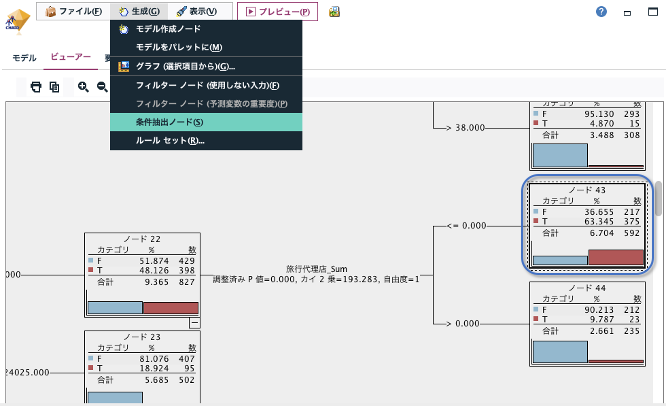
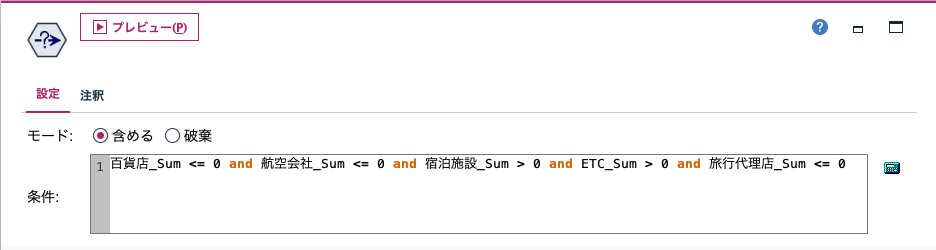
(3)決定木から条件抽出ノード生成
決定木グラフの任意のノードを選んだ状態で、「生成>条件抽出ノード」メニューを選ぶと、ノードに該当するケースを抽出する条件抽出ノードを自動生成できます。決定木の中から注目したい箇所を簡単にピックアップして、さらに深掘り分析することができます。
(4)ルールセット
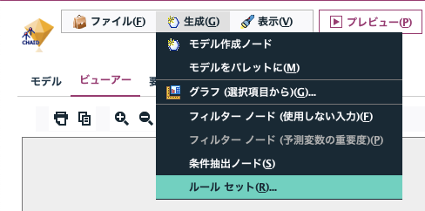
「生成>ルールセット」メニューを選ぶと、「RS(ルールセット)」ノードが自動生成されます。「40代女性で、クレジットカードを通販ではなく主に店舗で使うお客様は、通常より2.5倍もこの商品の購入確率が高い」といった法則の集合(ルールセット)に変換してくれます。このルールセットはテキストとしてコピーできますので、マクロやプログラムに変換してシステムに組み込むことが容易になります。

(5)インタラクティブツリー
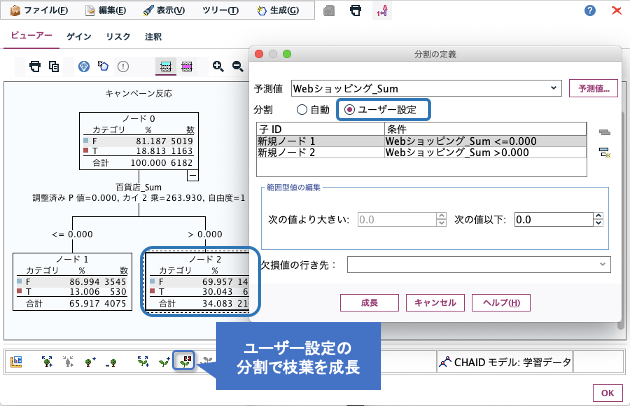
モデル作成ノードの「作成オプション>目的>インタラクティブセッションの起動」を選んで実行すると、決定木を1段階ずつ手動で成長させることができます。自由に枝切りができるだけでなく、個々の分岐条件を手動で設定することもできます。どの特徴量を使うかだけを選んで閾値は自動にしても良いし、閾値だけを設定しても良いのです。
例えば、顧客分析の場合に、最初の分岐はチャネルにしたい、年齢の分岐閾値は運転免許の取れる18歳にしたい、などビジネスルールを決定木の中に取り入れることが可能になるのです。
(6)各種チューニング
CHAIDモデル作成ノードの「作成オプション」タブでは様々なチューニングもできます。デフォルトのままでも十分に使えるのですが、精度を追求したい場合などに有用です。いくつかピックアップして簡単にご紹介します。
(6-1)継続学習
1年分のデータで予測モデルを作った後、新たに得られた直近1ヶ月分のデータで追加の学習を行う場合などに使います。13ヶ月分のデータで作り直すよりも早くモデル作成できます。
(6-2)ブースティング、バギング、アンサンブル
精度を上げるのに有効な方法なのですが、CHAIDの強みである説明しやすさを損なってしまいます。類似の方法としてXGBoostツリーやランダムフォレストが使えますので、それらを使っても良いですね。
(6-3)停止規則
精度を上げたいときは停止規則を緩くしてより深い決定木を作る、汎化性能を上げて過学習を防止したいときには停止規則をきつくしてより浅い決定木を作る、という調整ができます。
(6-4)誤分類コスト
2値分類の場合に、適合率・再現率のどちらを重視するか重みを設定できます。
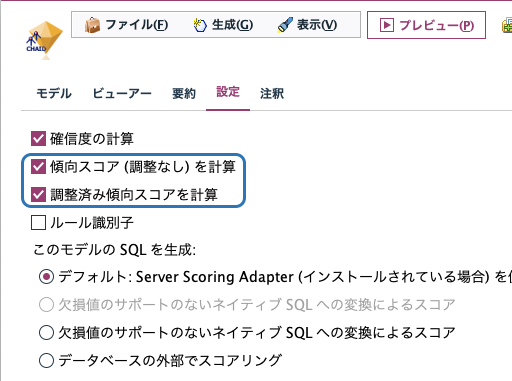
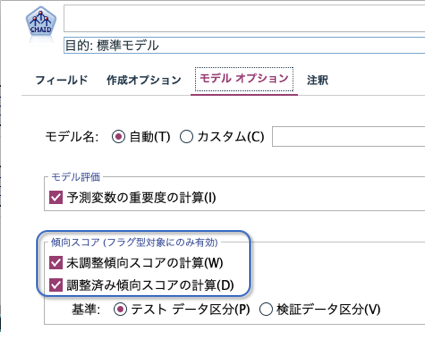
(7)傾向スコア
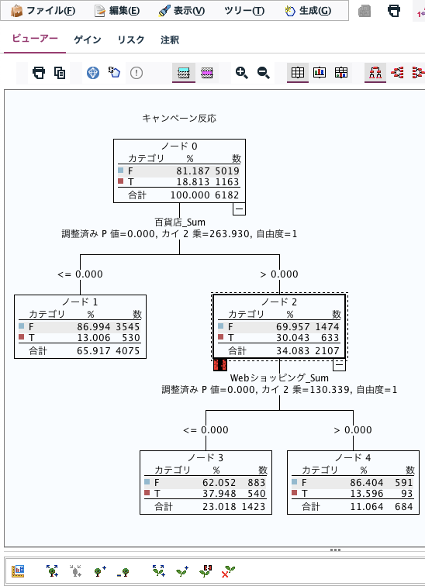
例えば「キャンペーンに反応するかどうか」2値分類の予測モデルを使って、可能性が高い上位60%の顧客をキャンペーン対象にしたいとします。モデルナゲット設定タブの「傾向スコア」が便利です。傾向スコアは予測結果が100% Fの場合に0、100% Tの場合に1という一律のスコアであり、傾向スコアでソートすることで上位60%といったターゲットリスト作成がすぐにできます。

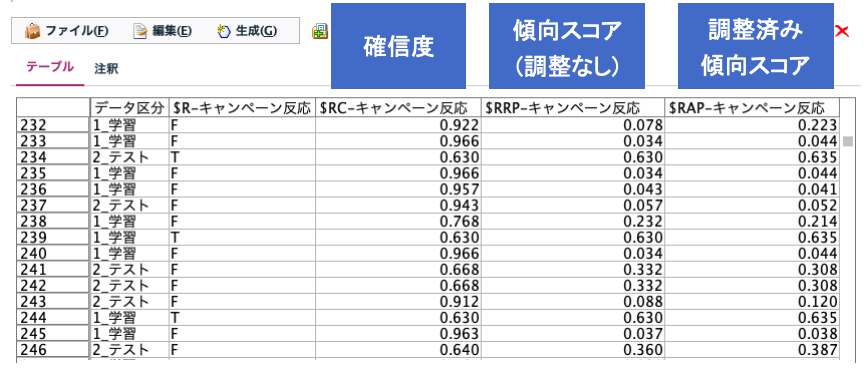
上の実行例から、調整なし傾向スコアは予測結果がTの場合は確信度に等しく、予測結果がFの場合は(1-確信度)になっていることがわかっていただけると思います。
調整済み傾向スコアは過学習を予防するようテストデータ/検証データで補正したスコアです。なお、調整済み傾向スコアを利用するには「データ区分ノード」でテストデータ/検証データを設定し、モデル作成ノードのモデル作成オプションタブで「調整済み傾向スコアの計算」にチェックを入れておく必要があります。
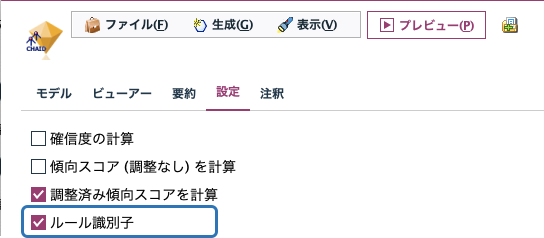
(8)ルール識別子
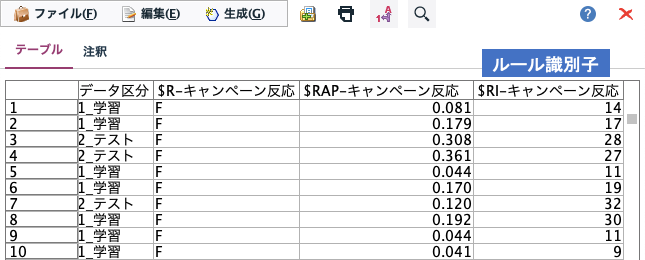
モデルナゲット設定タブの「ルール識別子」を使うことで、決定木のどの葉に分類されたかがわかります。前述のルールセットと合わせることで、どのような条件で個々の予測結果が出ているのかを判別できます。
使うデータを選ばず、モデルを解釈しやすいCHAIDは「分析の手始めに試してみる予測モデル」として適しています。さらに様々なTipsを知ることで、考え抜かれた使い勝手の良さに気づかされます。その説明しやすさ・使いやすさで、初心者にもプロフェッショナルにも大いに役立ってくれるでしょう。
リレー連載次回推しノード#07は、三菱自動車工業の伴様がフィールド作成ノードを説明くださいます!
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
山下 研一
日本アイ・ビー・エム株式会社
クラウド&コグニティブ・ソフトウェア事業本部
Data and AI事業部
データサイエンス&AI テクニカルセールス

皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む