SPSS Modeler ヒモトク
【リレー連載】わたしの推しノード – お助けロボ参上!?「データの自動準備ノード」があなたに代わって予測精度を上げる
2020年04月13日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:

MAIの木暮です。弊社はデータ分析支援を通し、分析リテラシーを高め、業界の発展に広く貢献していくことを1つの企業理念として、日々のビジネスに関するさまざまな課題を承り、データマイニング手法を用いて課題解決を支援するサービスを提供しています。
分析を始めるにあたって、データを加工することは効果的なモデルを作成するのに最も重要なものの1つとして挙げられます。ほとんどの場合、データは分析用に集められたものではなく、データベースや収集システムの設計上効率の良い形になっています。そのため、データ分析にあたっては、データの下準備がモデリングよりも重要な位置を占めるのです。データの準備における主な作業としては、集めたままのデータの中から有用なフィールドを抽出したり、欠損値や外れ値を処理したり、新しいフィールドを作成することなどが含まれます。このように、データの加工では数多くのタスクをこなさなければならず、分析に必要不可欠な段階であると同時に最も時間がかかってしまう段階でもあります。
今回ご紹介するデータの自動準備ノード(ADP)は、こうしたデータ準備にかかる時間を短縮するものとして、非常に便利なツールとなっています。この機能により、SPSS Modelerを操作する分析者のデータ準備作業をロボット化し、それよりも高度なAIを自動運転するかのように扱うことができるのです。
ノード内で何が行われている?
では、実際にデータ自動準備ノードで具体的にどのようなことが設定可能なのか、編集画面の設定タブを見ながら説明していきます。5つのグループにわかれているタブのうち、「入力と対象の準備」と「変数の構築・選択の設定」の機能にハイライトしてご紹介していきます。
入力と対象の準備
「入力と対象の準備」タブでは、外れ値や欠損値の処理などをおこなうことができます。わかりやすい例として、外れ値と欠損値の処理、連続型フィールドの変換についてみていきましょう。
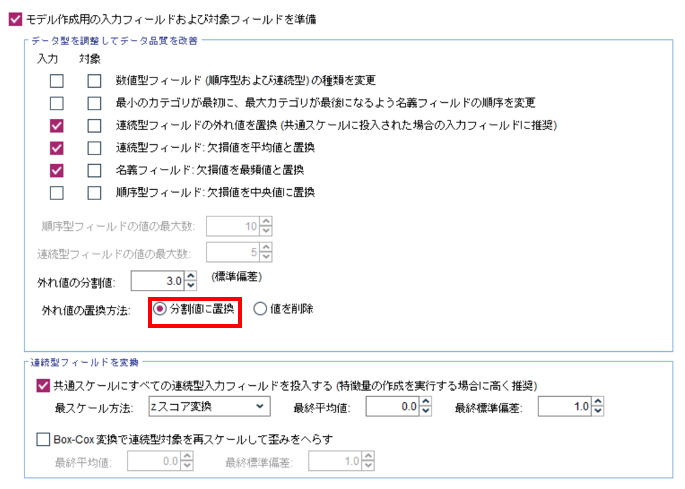
上図のように、「データ型を調整してデータ品質を改善」枠の3つ目~5つ目の入力ボックスにそれぞれチェックを入れます。
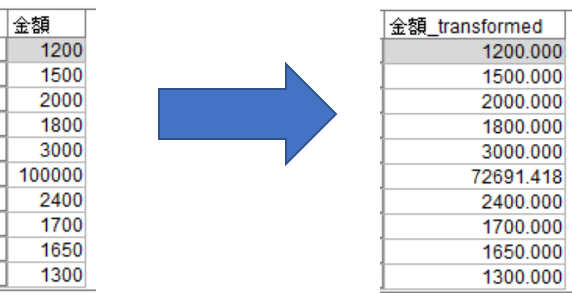
まず、「連続型フィールドの外れ値を置換」ですが、ここで入力データに存在する連続型フィールドの外れ値を変換するかどうかを指定します。そして、その下にある「外れ値の置換方法」において、標準偏差を基準とした分割値に置換するか、削除して欠損値として扱うかを設定できます。例えば、上図のように分割値はデフォルトの3(標準偏差)のまま、外れ値の置換方法を「分割値に置換」と選択します。すると、下テーブルのように5レコード目の値が「100000」から「72691.418」と、自動的に算出された分割値によってトリム化されています。
「連続型フィールド:欠損値を平均値と置換」、「名義フィールド:欠損値を最頻値と置換」では、数値型フィールドにおける欠損値を平均値に、カテゴリ型フィールドにおける欠損値を最頻値に置き換えることができます。

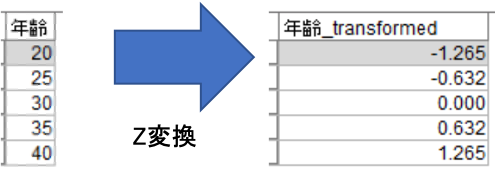
次に「連続型フィールドを変換」枠において、連続型フィールドを共通の値に変形(正規化)することができます。下図のようにデフォルトは「zスコア変換」になっており、平均値が0、標準偏差が1になるよう、各数連続型フィールドの標準化得点(Zスコア)を算出して置換してくれます。
変数の構築・選択の設定
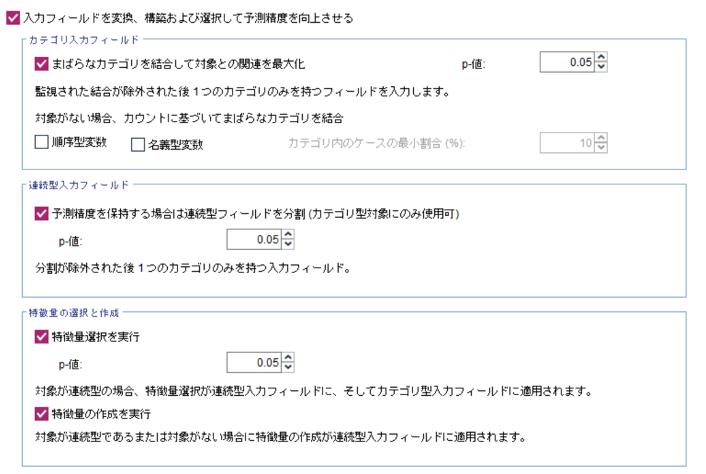
「変数の構築/選択」タブでは、データの予測精度の向上のために入力フィールドを変換したり、既存のフィールドから新しいフィールドを構築したりすることができます。
まず、「カテゴリ入力フィールド」枠の「まばらなカテゴリを結合して対象との関連を最大化」にチェックを入れることで、対象フィールドとの関連が高くなるようにカテゴリ型フィールドのカテゴリ数をより少なくなるようにまとめます。これにより、よりシンプルで解釈のしやすいモデル作成が期待できます。例えば下図のように、対象フィールドとの関連が最大となるよう職種のフィールドが変換され、新たに「職種_transformed」というフィールドができます。
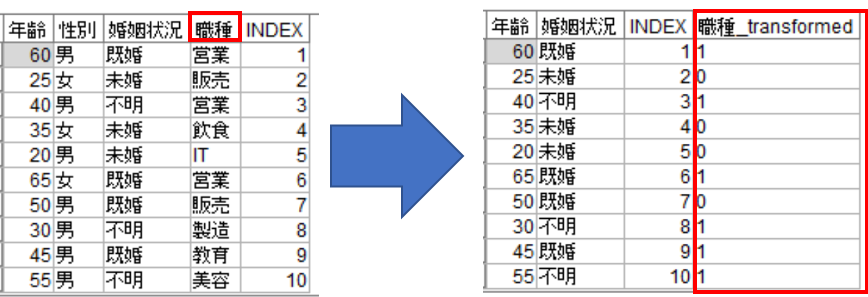
続いて「連続型入力フィールド」枠の「予測精度を保持する場合は連続型フィールドを分割」にチェックを入れることで、対象フィールドがカテゴリ型の場合、関連が高くなるように連続型入力フィールドを分割します。これにより、モデル作成時の精度向上が期待できます。
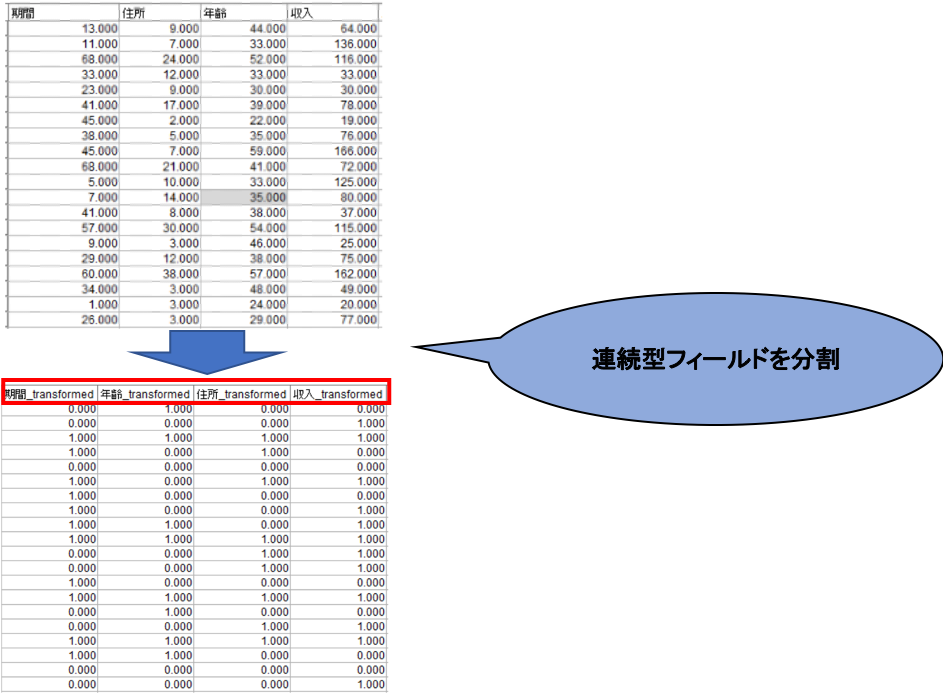
最後に「フィールド選択と構築」タブでは「特徴量選択を実行」をチェックすることで、関連が低いフィールドを削除し、「特徴量の作成を実行」にチェックすることで、連続型フィールドに数学的処理を施して新しい特徴量を作成してくれます。
特徴量の作成に使用されたフィールドは分析から除外され、新たに「feature」というフィールドとして分析に使用されます。
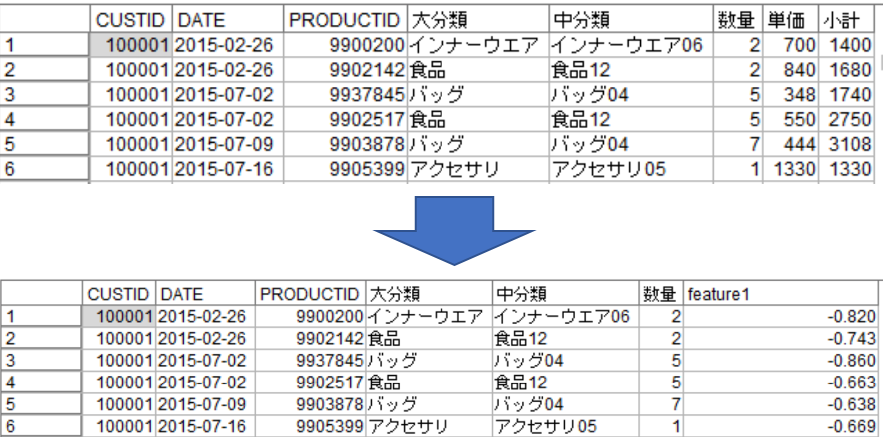
上図の例においては単価と小計が使用され、新たに「feature1」として分析に使用されるということになります。これらの数字がどういう計算に基づいているのかは自動準備ノードの精度分析タブ左下のビューより、フィールドを選択することで右側の画面にて知ることができます。
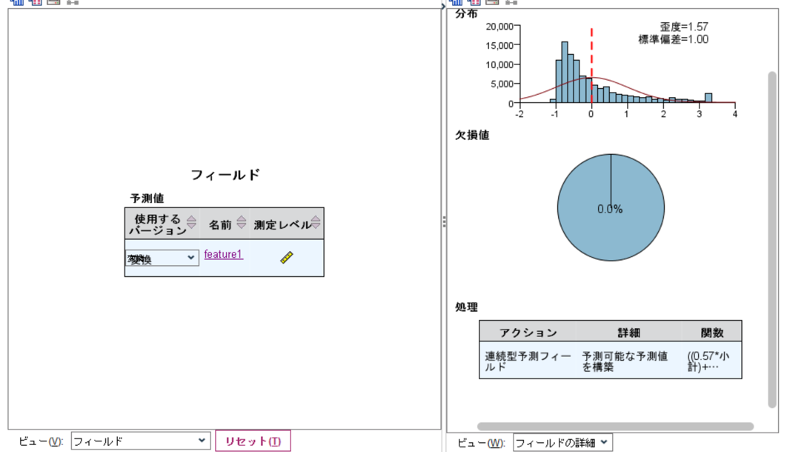
左側にフィールドの概要が示され、右側に分布や欠損値率、処理内容が出力されます。処理内容をみてみると、feature1は(0.57*小計)+(0.57*単価)という計算によって得られた値だということがわかります。
データ自動準備ノードで分析してみよう
それでは、データ自動準備ノードを使って得られたモデルはどれほどの精度を確保できるのでしょうか。自動準備ノードありのモデルとなしのモデルとで次のストリームを使って精度比較を行います。
今回使用するサンプルデータは、ある通信会社の会員データであり、テーブルの一部が下図に示されています。
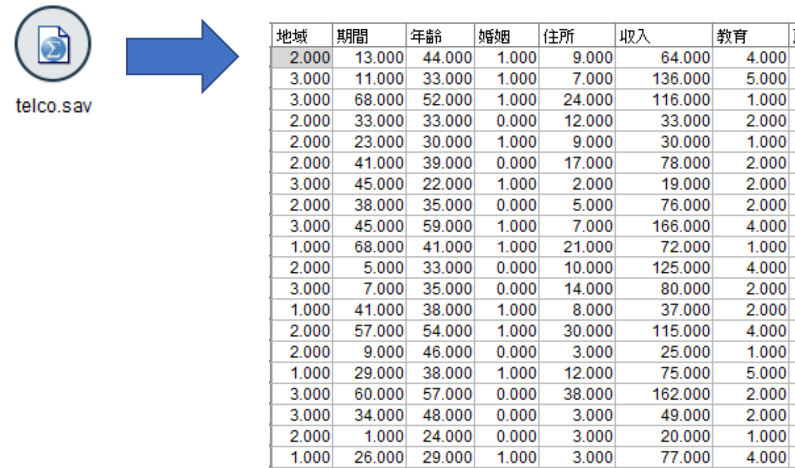
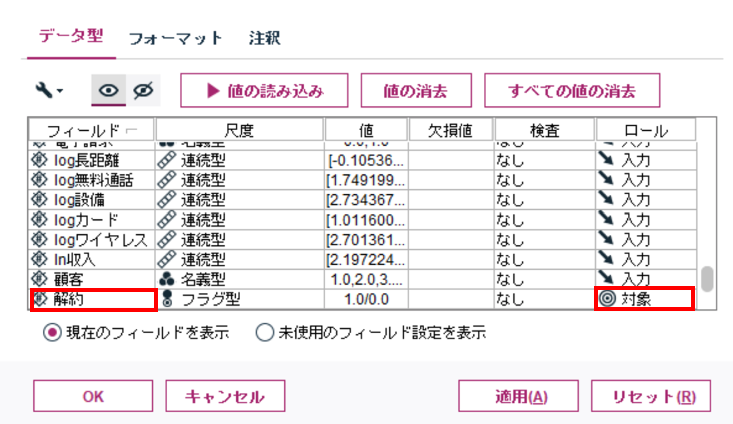
この入力ノードからデータ型ノードをリンクし、データ型ノードの編集画面で、「解約」のフラグ型フィールドのロールで対象を選択し、その他はすべて入力にします。
それではまず、自動準備ノードを使わずにこのままモデルにデータを通してみます。
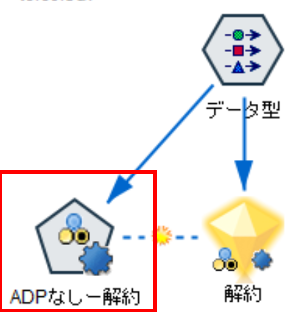
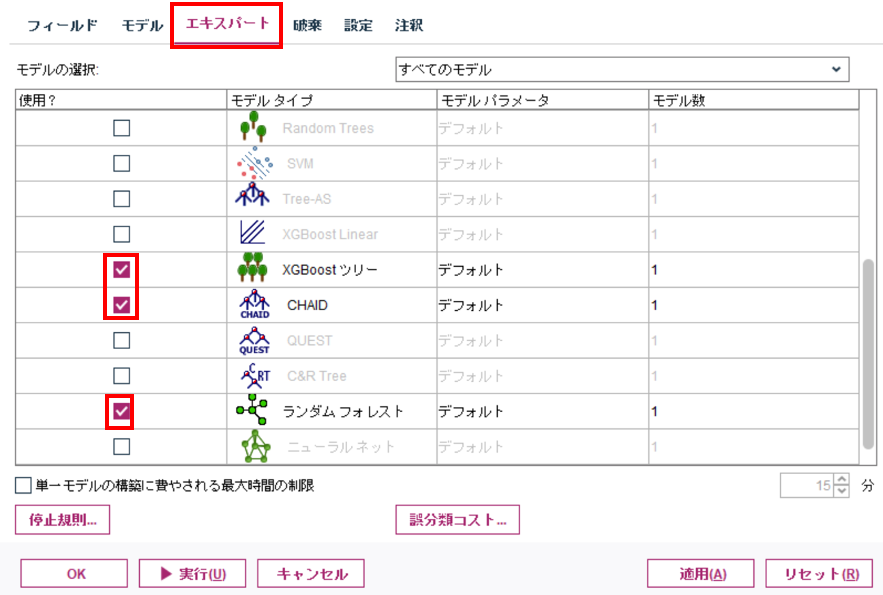
モデリングには自動分類ノードを使用します。自動分類ノードは、指定した複数の判別予測アルゴリズムを実行し、それぞれの結果を精度順に出力してくれます。編集画面のエキスパートタブにて使用するアルゴリズムをCHAID、ランダムフォレスト、XGBoostツリーの3つに設定し、モデルを実行します。これで自動準備ノードなしのモデルナゲットが生成されます。続いて、自動準備ノードありのモデルを作成しましょう。
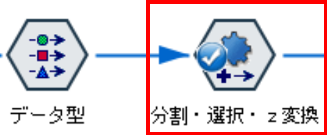
データ型ノードから自動準備ノードを接続し、編集画面を開きます。設定タブに行き、まず「入力フィールドを除外」の設定を行います。「欠損値が多すぎるフィールドを除外する」と「一意のカテゴリが多すぎる名義フィールドを除外する」にチェックを入れます。
なお、今回は「フィールド設定」はデフォルトのままとし、「日付/時間を準備」の設定も入力データに日付データが存在しないため、すべてオフにしておきます。
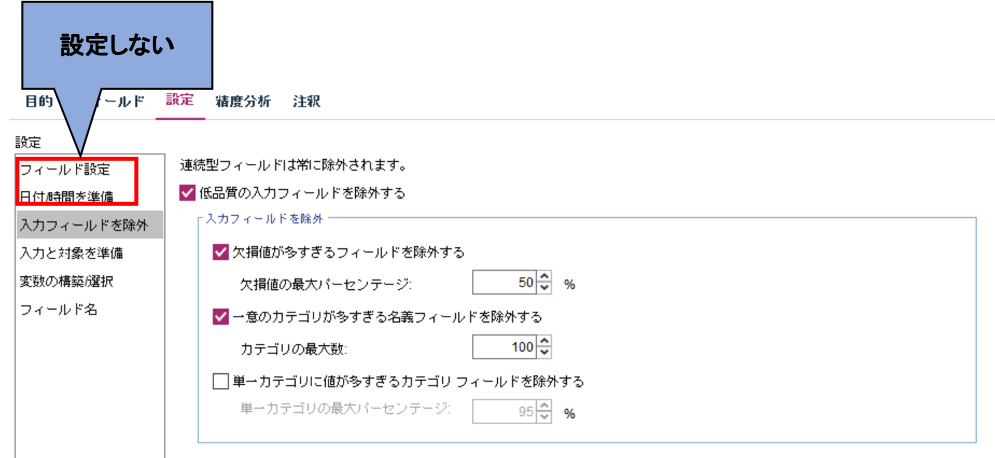
続いて「入力と対象を準備」の設定画面で、下図のとおり、「連続型フィールド:欠損値を平均値と置換」、「名義フィールド:欠損値を最頻値と置換」、「共通スケールにすべての連続型入力フィールドを投入する」の3つのチェックボックスを選択します。
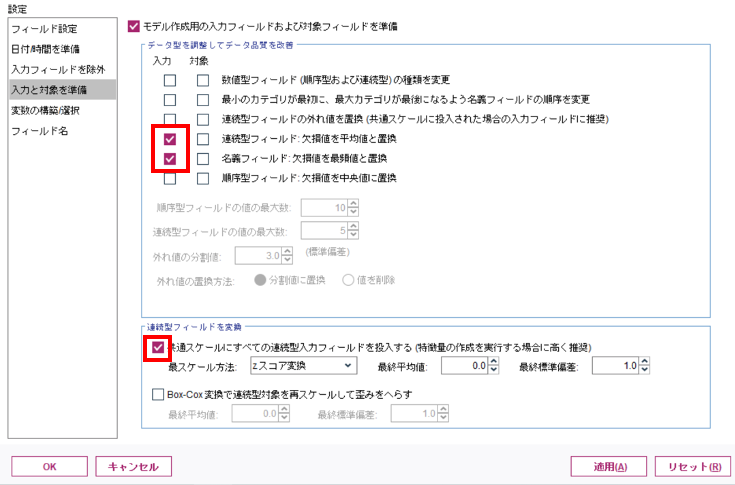
最後に「変数の構築/選択」の設定では、「入力フィールドを変換、構築および選択して予測精度を向上させる」にチェックを入れたのち、中央の「予測精度を保持する場合は連続型フィールドを分割」を選択します。特徴量の選択や作成の項目は対象フィールドが連続型でなければならないので、今回は設定しません。
これで設定が完了したので編集画面を閉じ、自動分類ノードを接続します。自動分類ノード編集画面のエキスパートタブで先程と同様に3つのアルゴリズムを選択し、実行します。自動準備ノードありのモデルナゲットを作成できました。
モデルの作成が終了しましたので、それぞれのナゲットの内容を見てみましょう。自動準備なしのモデルでの予測結果は下図のようになっています。表の「全体精度(%)」が実測値に対する予測値の正解率を示しています。CHAIDとXGBoostツリーは高い水準で予測が当たっていますが、ランダムフォレストではわずか12.6%とかなり低い精度となってしまっています。
では、これらの結果を踏まえた上で次の自動準備ありのモデルについてみていくと精度はどう変化するでしょうか。
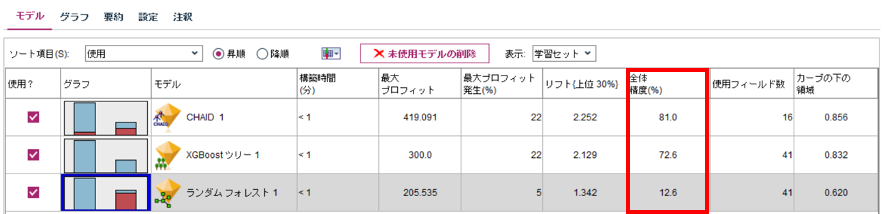
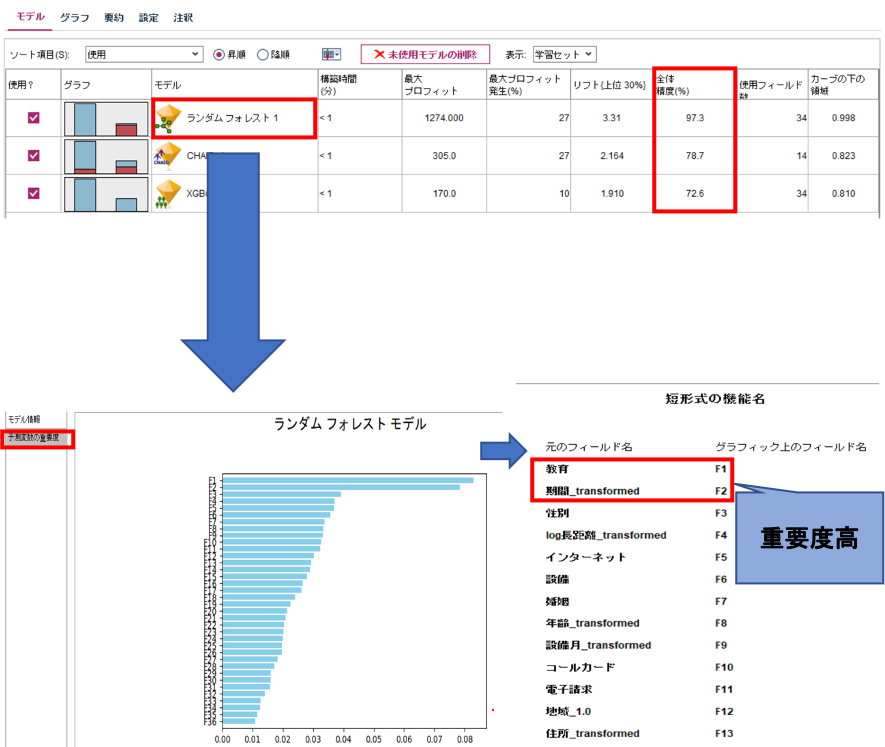
自動準備ありの場合、下図の全体精度を見ると、CHAIDとXGBoostツリーにおいては精度が自動準備前のモデルとほとんど変化しないのですが、ランダムフォレストでの全体精度を見てください。自動準備前ではわずか12.6%だった精度が97.3%まで上昇しているのがお分かりいただけると思います。
さらにここで、表にあるランダムフォレストのナゲット部分をダブルクリックし、予測変数の重要度をクリックすることで、このモデルでの重要フィールドを上位順に確認することができます。F1、F2・・・と続く特徴量の内容を見てみると、F1では教育レベルという自動準備で変換されていないフィールドが来ているのですが、F2の「期間_transformed」は自動準備ノードによって、サービス継続期間が変換されたフィールドになっています。下グラフにおいてこのF2のフィールドがF1とほぼ変わらない重要度を示していることから、自動準備ノードで作成された新たな特徴量が精度の向上に大きく貢献していることが示せました。
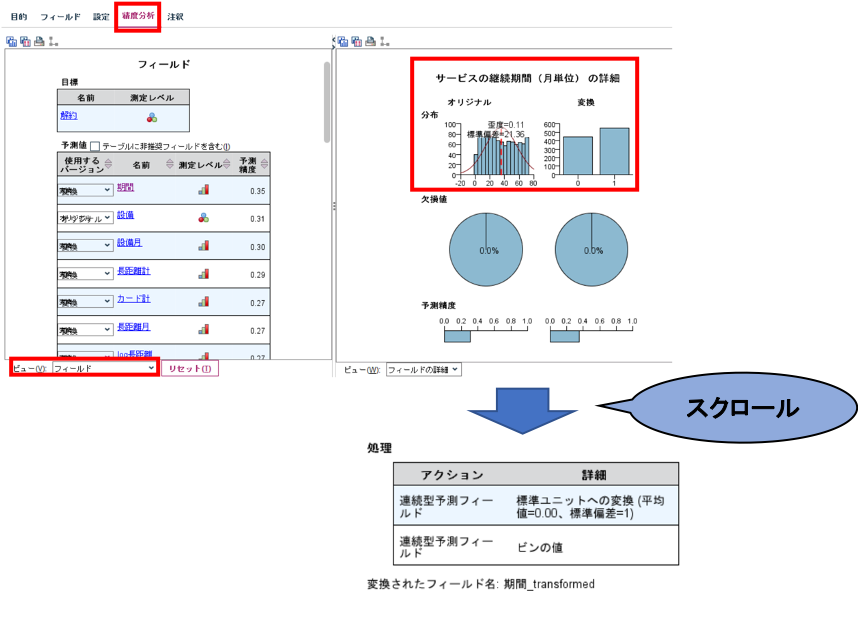
最後に、この「期間_transformed」でどのような変換がされたのか確認します。自動準備ノードの編集画面から精度分析タブを開き、左下にあるビューより「フィールド」を選択します。下図左側のテーブルから期間をクリックすると右側にフィールドの詳細が出力されます。分布のグラフを確認すると、元の「期間」のフィールドは変換されて、0/1に2値化されていることがわかります。また、右側画面をスクロールしていくと処理の詳細を確認でき、「期間_transformed」は「期間」フィールドをZスコア変換して、2つにフィールドを分割したものだということが示されています。
まとめ
これまでみてきたように、データの自動準備ノードを使用するだけで、多種多様な特徴量を抽出でき、これらがモデルの精度向上に役立つことがお分かりいただけたと思います。また、先ほどのデモンストレーションのように、自動分類ノードおよび自動数値ノードと組み合わせることで、各モデリング手法や特徴量についての知識がなくても容易に高精度のモデルを作成できるのもこのノードの魅力の一つです。今まで、このノードの存在を知らなかった方も、あえて使ってこなかったという方も、この機会に一度このノードの魅力に触れ、使ってみてはいかがでしょうか。
リレー連載次回推しノード#06はIBMのSPSSテクニカルセールス山下さんがCHAIDノードを取り上げてくださいます!
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら


データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む

【予約開始】「SPSS秋のユーザーイベント2024」が11月27日にオンサイト開催
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
本年6月800名を超える方々にオンライン参加いただいたSPSS春のユーザーイベントに続き、『秋のSPSSユーザーイベント』を11月27日に雅叙園東京ホテルにて現地開催する運びとなりました。 このイベントは ...続きを読む